


Many of us have been wracking our brains why Nvidia would spend a fortune – a whopping $40 billion – to acquire Arm Holdings, a chip architecture licensing company that generates on the order of $2 billion in sales – since the deal was rumored back in July 2020. As we sat and listened to the Arm Vision Day rollout of the Arm V9 architecture, which will define processors ranging from tiny embedded controllers in IoT device all the way up to massive CPUs in the datacenter, we may have figured it out.
There are all kinds of positives, as we pointed out in our original analysis ahead of the deal, in our analysis the day the deal was announced in September 2020, and in a one-on-one conversation with Nvidia co-founder and chief executive officer Jensen Huang in October 2020.
We have said for a long time that we believe that Nvidia needs to control its own CPU future, and even joked with Huang that it didn’t need to have to buy all of Arm Holdings to make the best Arm server CPU, to which he responded that this was truly a once-in-a-lifetime opportunity to create value and push all of Nvidia’s technologies – its own GPUs for compute and graphics and Mellanox network interface chips, DPU processors, and switch ASICs – through an Arm licensing channel to make them all as malleable and yet standardized as the Arm licensing model not only allows, but encourages.
Huang would be the first to tell you that Nvidia can’t create every processor for every situation, and indeed no single company can. And that is why the Arm ecosystem needs to not only be protected, it needs to be cultivated and extended in a way that only a relatively big company like Nvidia can make happen. (Softbank is too distracted by the financial woes of its investments around the globe that have gone bad and basically has to sell Arm to fix its balance sheet. Which is a buying opportunity for Nvidia, which is only really spending $12 billion in cash to get control of Arm; the rest is funny money from stock market capitalization, which in a sense is “free” money that Nvidia can spend to fill in the remaining $28 billion.)
We have sat through these interviews, and chewed on all of this, and chocked it up to yet another tech titan having enough dough to do a big thing. But, as we watched the Vision Day presentations by Arm chief executive officer Simon Segars and the rest of the Arm tech team, they kept talking about pulling more vector math, matrix math, and digital signal processing onto the forthcoming Arm V9 architecture. And suddenly, it all finally became clear: Nvidia and Arm both believe that in a modern, massively distributed world all kinds of compute are going to be tailored to run analytics, machine learning, and other kinds of data manipulation and transaction processing or preprocessing as locally as possible and a single, compatible substrate is going to be the best answer to creating this malleable compute fabric for a lot of workloads. What this necessarily means is that both companies absolutely believe that in many cases, the applicability of a hybrid CPU-GPU compute model will not and cannot work.
In other words, Nvidia’s GPU compute business has a limit to its expansion, and perhaps it is a lot lower than many of us have been thinking. The pendulum will be swinging back to purpose built CPUs that have embedded vector and matrix capabilities, highly tuned for specific algorithms. This will be specifically true for intermediate edge computing and endpoint IoT devices that need to compute locally because shipping data back to be processed in a datacenter doesn’t make sense at all, either technically or economically.
Jem Davies, an Arm Fellow and general manager of its machine learning division, gave a perfect example of the economic forces that are driving compute out of the datacenter and into a more diffuse data galaxy, as we called it three years ago.
“In the Armv9 decade, partners will create a future enabled by Arm AI with more ML on device,” Davies explained. “With over eight billion voice assistive devices. We need speech recognition on sub-$1 microcontrollers. Processing everything on server just doesn’t work, physically or financially. Cloud computing bandwidth aren’t free and recognition on device is the only way. A voice activated coffee maker using cloud services used ten times a day would cost the device maker around $15 per year per appliance. Computing ML on device also benefits latency, reliability and, crucially, security.”
To bring this on home, if the coffee maker with voice recognition was in use for four years, the speech recognition cost for chewing on data back in the Mr Coffee datacenter would wipe out the entire revenue stream from that coffee maker, but that same function, if implemented on a device specifically tuned for this very precise job, could be done for under $1 and would not affect the purchase price significantly. And, we think, the coffee maker manufacturer could probably charge a premium for the voice recognition and recoup some or all of the investment in the technology added to the pot over a reasonably short time until it just became normal. Like having a clock and timer in a coffee maker did several decades ago, allowing us all to wake up to a hot cup of java or joe or whatever you call it in the morning by staging the ground coffee beans and water the night before.
What holds true for the coffee maker is going to hold true for most of the hundreds of billions of devices that span from the client back to the edge and up through the datacenter.
There will be millions of such examples across hundreds of billions of devices in the next decade, and that is why with the Armv9 architecture, Arm engineers are planning to make so many changes. The changes will come gradually, of course, just as happened with the Armv7 and Armv8 architectures that most IT people are familiar with because these designs coincide with the rise of the Arm’s use as the motor of choice in smartphones and tablets and increasing use in datacenter infrastructure, including but not limited to servers.
Here is the key question, and it is one that we have asked in many slightly different ways over in the several decades we have been watching the IT sector grow and evolve: Does the world want a single, malleable, compatible substrate? By which we mean in the next decade will it be Arm’s time to help IT wave goodbye to X86? The rise of the mobile phone and then smartphones put the Arm architecture on a collision course with the X86 instruction set starting with the launch of the Nokia 6110 mobile phone in 1997 and with the Apple iPhone launch in 2007.
With the launch of server chip maker Calxeda in 2010, we thought something could give X86 a run for the server money, much as X86 did for RISC/Unix and RISC/Unix did for proprietary CISC in the prior decades of datacenter compute. And we have watched over the past decade as Arm server chip makers have come and gone. But today it is different. Amazon Web Services is already the largest maker of Arm servers in the world, with its Graviton2 chip, and it looks like Microsoft could be working on its own Arm server chips. Ampere Computing is fielding a good set of Arm server processors, too. Fujitsu’s A64FX is a resounding success in the “Fugaku” supercomputer in Japan, and SiPearl in Europe and HiSilicon in China are continuing to invest in new chippery for systems, too.
Despite all of the disappointments – and some successes – with servers to date, it is hard to bet against Arm. Volume and momentum is on the side of the Arm architecture so long as Nvidia does not mess with success should it prevail in its $40 billion acquisition. (We do not believe Nvidia will change Arm’s licensing and take it at face value from Huang himself that Nvidia will pump more, not less, technology through the Arm licensing pipeline.) In his keynote address, Segars said that by the end of 2021, Arm’s partners would ship a cumulative of 200 billion devices based on its architecture. The first 100 billion took 26 years, as Acorn Computers evolved into Advanced RISC Machines and transmuted into Arm Holdings. The second 100 billion chips (through the end of 2021) took only five years to sell. And between the end of 2021 and the end of this decade, Segars predicts that Arm will sell another 300 billion chips. If history is any guide, then that is a run rate of 20 billion chips per year here in 2021 but around 55 billion per year through 2030. The rate of change of Arm deployments is itself expected to accelerate.
How much of these Arm chips will be in the datacenter, at different levels of the edge, and within endpoints remains to be seen. While Arm server shipments were up by a factor of 4.5X in the fourth quarter, according to IDC, it is from a base that is small enough that this is not really affecting Intel’s hegemony in the datacenter server. As we reported years ago, Arm had hoped to represent 20 percent of server shipments by now, and at one point raised its expectations to 25 percent of shipments by 2020. Not even close. And the re-emergence of AMD with its Epyc processors has not helped. But only a fool would count Arm out. Hope springs eternal for Arm servers, as we discussed a few months ago.
The ArmV9 architecture certainly has servers in mind as well as other devices, and Segars contends that there won’t be one bit of data in the world that doesn’t somehow go through or end up on an Arm-based device. It might take another five to ten years for Arm to be representative in servers, we think. Segars and the Arm team were not foolish enough to put a new stake in that old ground as part of the architecture rollout – particularly with the Nvidia acquisition still not completed. But clearly one of the arguments that Nvidia can credibly make is that there needs to be more competition and more innovation inside the servers of the world.
Richard Grisenthwaite, another Arm Fellow who is also the company’s chief architect, gave an overview of the evolution of the Arm architecture since 1990 and pulled back the curtain a bit on the forthcoming Armv9 architecture. We have mashed up these two charts into one so you can see it all in proper perspective.
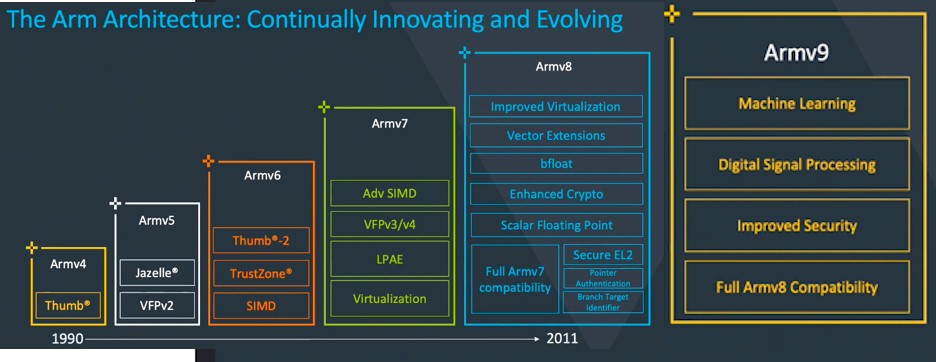
As far as we area concerned, Arm did not become a possible server instruction set until 40-bit memory addressing (LPAE), hardware-assisted server virtualization, and vector floating point (VFP) units, and Advanced SIMD Extensions (which made integer and floating point vector instructions native to the architecture) were added with Armv7. But it really took the Armv8 architecture launched in 2011, with its memory extended to 64-bits, to make a good server chip, and in the past decade a slew of technologies have been added to this architecture to make it a very good instruction set for a server chip.
“The architecture is not a static thing,” Grisenthwaite explained. “We keep on innovating and evolving it to meet the ever-changing needs of the computing world. In the years since we introduced 64-bit processing in Armv8, we’ve added a number of extensions, such as improved support for virtualization, the addition of float16 and bfloat to substantially enhance the performance of machine learning, and a number of security enhancements, including increased resilience against return-oriented programing and support for a secure hypervisor. Innovating the Arm architecture never stops.”
The Armv9 architecture unveiled today is technically known as the Armv9-A architecture profile, with the A being short for “application” and is meant to designate the fullest feature set for client and server devices. The R profile is for “real-time” uses, and the M profile is for “microcontrollers” that do not need the full set of features and are aimed at low cost and low power uses. The R and M profiles will be added soon, we presume, and the feature set will expand for all Armv9 profiles as needed by the market, based on input from Arm licensees who make chips, Arm chip buyers, and the competitive landscape.
The first thing to note in the Armv9 architecture is that it is a superset of Armv8 and there is absolute backwards compatibility. Without that, Arm is dead in the water.
The second big thing on the computing front is support for Scalable Vector Extensions 2, or SVE2, vector processing.
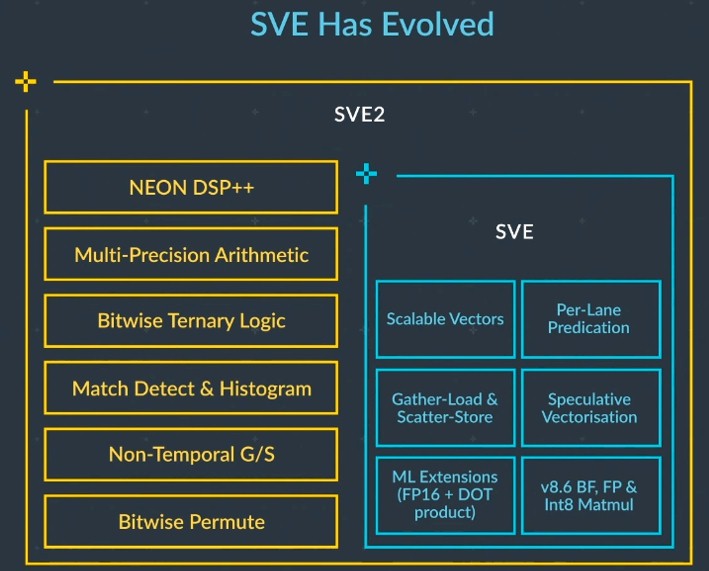
Arm worked with Fujitsu to create the original SVE vector math specifications, which are implemented in Fujitsu’s A64FX processor, the heart of the “Fugaku” supercomputer at the RIKEN lab in Japan. These are 512-bit wide SIMD processors that support FP32 and FP64 math as you might expect but also FP16 half precision and INT16/INT8 dot product processing as well – the latter mixed precision formats all important for digital signal processing and machine learning.
Arm’s own “Ares” N1 processor core design did not support SVE, but the Neoverse “Zeus” V1 core has a pair of 256-bit vector units compatible with SVE2 and the “Perseus” N2 core will have a pair of 128-bit SVE units. Future “Poseidon” Neoverse V2 and N3 cores, we presume, will support SVE2 vector units with the expanded capabilities outlined in the chart above.
“That technology was designed in a scalable manner so that the concepts used supercomputers can be applied across a far wider range of products,” said Grisenthwaite. “We have added increased functionality to create SVE2 to enhance scalable vector extensions, to work well for 5G systems and in many other use cases, such as virtual and augmented reality, and also for machine learning within the CPU. Over the next few years, we will be extending this further with substantial enhancements in performing matrix-based calculations within the CPU.”
That sure doesn’t sound like a company that is just going to offload hard math problems to a GPU.
The biggest parts of the Armv9 architecture have to do with completely reworking the security model in the processor to make Arm a better option than an X86 processor besides that it might be a little more energy efficient and it might cost a little bit less. While these are important, the idea that companies could deploy more secure chippery across the spectrum of client, edge, and datacenter devices is one that we think IT organizations all over the world will be able to get behind.
One new security technology is called Memory Tagging Extensions, which is going to make it a lot harder for hackers to exploit vulnerabilities hidden in time and space within the code of the world.
“Analyzing the large number of security issues that get reported in the world’s software, a depressing reality is the root cause of many of those problems really comes back to the same old memory safety issues that have been plaguing computing for the last 50 years. Two particularly common memory safety problems – buffer overflow and use after free – seem to be incredibly persistent over the years. And a huge part of the problem is that they are frequently present in software for years before they are discovered and exploited.”
While this is a complex feature, the idea is to encapsulate the accessibility information for data stored in memory with the data itself – a kind of object-oriented security, we reckon. If a pointer to memory has a tag, and the tag doesn’t match when the application tries to access memory – perhaps the memory has moved on or the access is out of range – the tag check fails and the memory access is denied. No more access to memory thanks to buffer overflows and use after free hacks.
We often talk about a 20 percent price/performance advantage being enough to change chip instruction sets. What is this kind of security worth, particularly if it can be done transparently to applications? We will find out more about the CHERI project at the University of Cambridge and its derivative Project Morello that Arm Holdings is working on with Microsoft, Google, the University of Cambridge, and the University of Edinburgh, which implement memory tagging as Arm is pulling into the Armv9 architecture. Not for nothing, but IBM’s proprietary CISC processors used in its AS/400 line dating from 1988 had memory tags for just this reason, and this capability moved over to Power chips in 1995 and is still in the IBM i follow-on platform today. That said, IBM has not used the memory tags for security, per se, but rather to enhancement the performance of the system. So that use appears to be new.
The other new feature in Armv9 is called Realms, and it adds a new, secure address space extension to the trusted firmware that has evolved during the Armv8 generation.
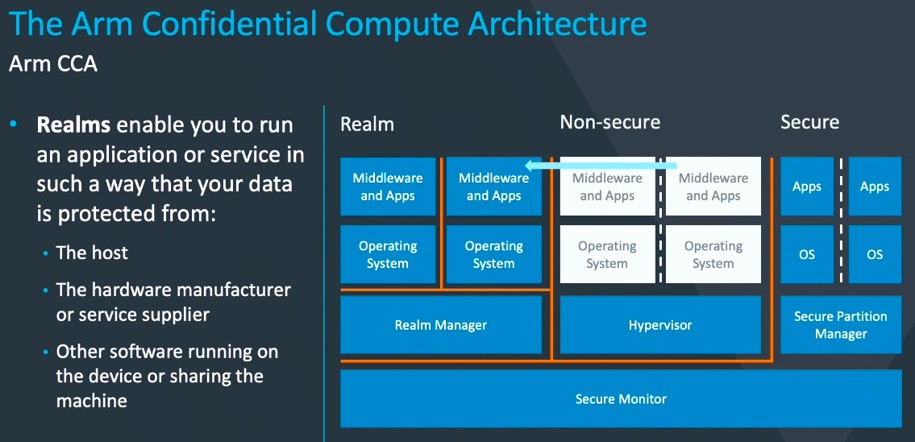
A realm is a kind of memory partition, it looks like, at least according to the explanation given by Mark Hambleton, vice president of open source software at Arm. So instead of hosting virtual machines in a common address space, as is done by hypervisors today, each VM would be hosted in a protected address space that is walled off from the other VMs in the system, and equally important, from the unsecured areas where the operating system is running. The question we have is: Why have a hypervisor at all then, if the realm manager can do all this carving up and securing.
That’s a very high level for the Armv9-A architecture, to be sure, and we will learn more as Arm says more. But the real takeaway is that Arm believes in specialized processing within a device as well as across devices as the only way to keep advancing compute as Moore’s Law goes the way of Dennard scaling. Like this:
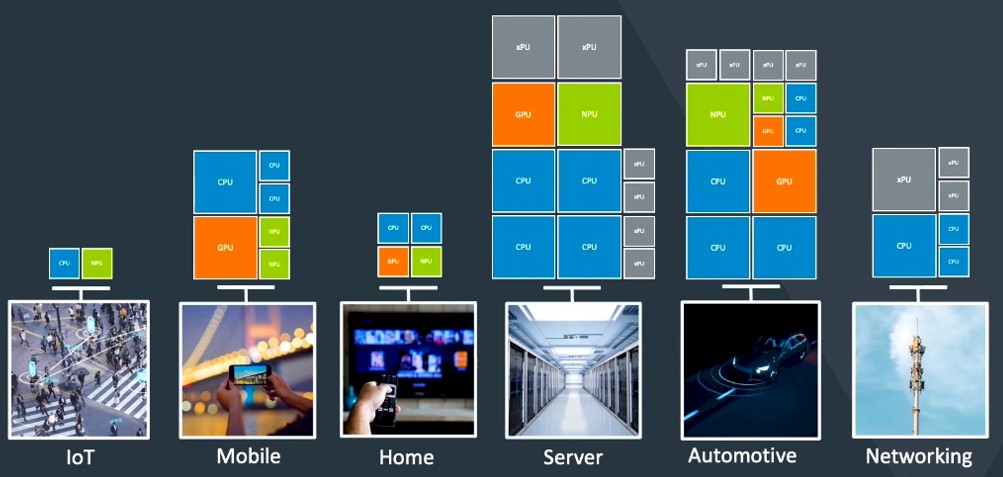
In the next decade, software is going to have to be co-designed with hardware on a ridiculous scale, and the idea of a what constitutes a high volume chip is going to change. It is going to be quite a balancing act between having a general purpose platform that has too much dark silicon but is cheaper per unit to make and having a specifically designed ASIC with all the right features for a specific workload right now.
This is going to be one, massive hardware-software engineering headache. So many choices, maybe too many choices.
Welcome to being a hyperscaler, everyone. Sucks, don’t it? At least Arm and its licensees – and maybe along with Nvidia – are going to try to help.