


Emulation is not just the sincerest form of flattery. It is also how you jump start the adoption of a new compute engine or move an entire software stack from one platform to another with a different architecture. Emulation always involves some form of performance hit, but if you are clever enough, it can be modest and a fair compensation for the time and effort saved in actually porting code from one compute engine to another.
With CPUs now getting both vector and matrix math units and with a shortage of GPU compute engines compared to the huge demand thanks to the generative AI boom, there is without question not only a need for alternatives to the CUDA parallel programming environment that Nvidia created as the core of its GPU compute platform, but a need to run CUDA codes on anything and everything that can do vector or matrix math. Alternative and parallel (in terms of features and functions) programming environments such as HIP from AMD (part of its ROCm stack) and SYCL from Intel (the core of its oneAPI effort) can help CUDA programmers take their knowledge and apply it to a new device, which is great. But there is plenty of fussing around with some parts of the code and there is not yet a universal emulator that can convert CUDA to any GPU or CPU.
What we need for GPU and CPU vector/matrix compute is something akin to the QuickTransit emulator, which was created by a clever team of techies at the University of Manchester, which launched in 2004 as a commercial products by a company called Transitive after four years of development, and which had huge potential to upset a lot of server platform apple carts in the datacenter, but didn’t for reasons that will become obvious in a second.
Many of you have used QuickTransit without knowing it. Supercomputer maker SGI was the first to employ this emulator as it shifted from MIPS to Itanium architectures, and Apple followed suit, basing its own “Rosetta” emulation environment on QuickTransit as it shifted from PowerPC to Intel Core processors for its client computers. IBM acquired Transitive in 2008 and basically sat on the technology because it was too dangerous to let loose. (Big Blue did use it to provide an X86 runtime environment for Linux on its Power iron, which it withdrew from support in 2012.)
We don’t have QuickTransit for GPUs, but we do have something with the unwieldy name of Cuda for Parallelized and Broad-range Processors out of researchers from the Georgia Institute of Technology and with contributions from Seoul National University that can take CUDA kernels and automagically port them to run on the LLVM compiler stack and execute on GPUs or CPUs. (Interestingly, Chris Lattner, one of the creators of LLVM, is chief executive officer at Modular AI, which is creating a new programming language called Mojo to provide a kind of portability for AI applications at a higher level across many devices.) This CuPBoP framework is a bit like QuickTransit in concept, but is a very different beast entirely.
The CuPBoP framework was introduced in a paper published back in June 2022, and the source code for the framework is available on GitHub. CuPBoP came to our attention this week as the Georgia Tech researchers released a variant of the framework called CuPBoP-AMD that is tuned to work on AMD GPUs and that presents an alternative to AMD’s HIP environment in ROCm to port Nvidia CUDA code to AMD GPUs. Lots of people are thinking about that now that AMD is shipping its “Antares” MI300X and MI300A compute engines, which can stand toe-to-toe with Nvidia “Hopper” H100 and H200 devices. The CuPBoP-AMD paper is at this link. (This framework needs a better name, folks. . . .)
While AMD and Intel talk about porting or emulating CUDA applications, here is how the Georgia Tech team sees the situation as of when this latter paper was presented at the SC23 supercomputing conference in Denver:
“Intel has a Data Parallel C++ (DPC++) library called SYCLomatic for converting CUDA to SYCL, which has runtime support for AMD GPUs for ROCM 4.5.1, but it is in beta mode without complete feature support at the time of this writing. AMD utilizes HIPIFY for source-to-source translation of CUDA to HIP. However, HIPIFY does not account for device-side template arguments in texture memory and multiple CUDA header files “.cuh”. Thus, manual manipulation by the developer is required in HIPIFY. Manual manipulation by developers can be cumbersome in large repositories of CUDA programs, which is a reason the CuPBoP framework aims to resolve. CuPBoP is a framework to allow the execution of CUDA on non-Nvidia devices.”
The trick with CuPBoP, in part, is to use the LLVM framework and its Clang compiler, which can compile both Nvidia CUDA and AMD HIP programs to a standard intermediate representation (IR) format, which in turn can be compiled into a binary executable for the AMD GPUs. The CuPBoP compilation pipeline looks like this:
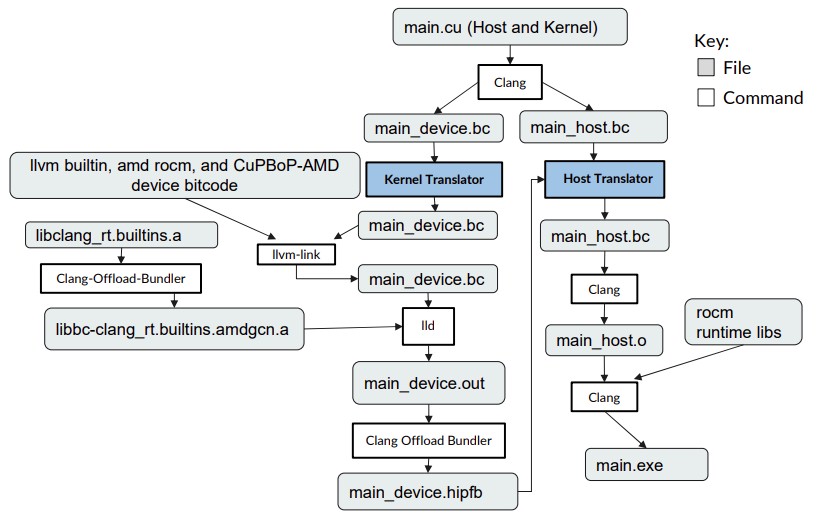
The CuPBoP framework creates two IR files, one for the kernel code and one for the host code, and it is at this IR level that the translation to the AMD GPUs is done rather than at a higher level where translating macros and separate header files gives AMD’s HIP tool some trouble.
At the moment, the CuBPoP framework only supports the CUDA features that are used in the Rodinia Benchmark, a suite of tests created by the University of Virginia to test current and emerging technologies that first debuted back in 2009, right as GPUs were starting to make their way into the datacenter. The Rodinia applications and kernels cover data mining, bioinformatics, physics simulation, pattern recognition, image processing, and graph processing algorithms – the kinds of things that advanced architectures are created to better tackle.
Here is how CuPBoP-AMD variant of the CuPBoP framework lines up against AMD’s HIPIFY tool in the ROCm stack:
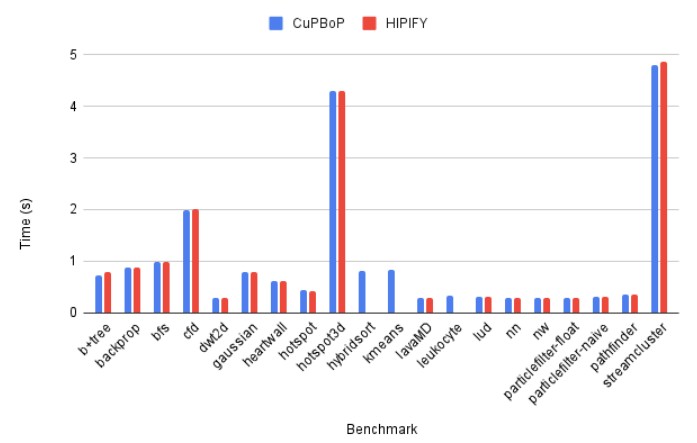
In terms of the execution of CUDA code that has been translated to run on AMD GPUs, the performance of CuPBoP-AMD looks to be indistinguishable from HIP. We would love to see how this translated CUDA code compares to running natively on Nvidia A100, H100, and H200 GPUs, of course. The researchers say that CuPBoP-AMD is still a work in progress and more Rodinia Benchmark features need to be enabled. And that is always the issue with emulators and translators: They are always playing catch up. But, then again, they allow a new platform to actually catch up faster.
The wonder is that AMD has not already bought the rights to this tool and hired the Georgia Tech team . . .