



In many ways, the “Grace” CG100 server processor created by Nvidia – its first true server CPU and a very useful adjunct for extending the memory space of its “Hopper” GH100 GPU accelerators – was designed perfectly for HPC simulation and modeling workloads. And several major supercomputing labs are putting the Grace CPU through the HPC paces and we are seeing some interesting early results.
The Grace CPU has a relatively high core count and a relatively low thermal footprint, and it has banks of low-power DDR5 (LPDDR5) memory – the kind used in laptops but gussied up with error correction to be server class – of sufficient capacity to be useful for HPC systems, which typically have 256 GB or 512 GB per node these days and sometimes less.
Put two Grace CPUs together into a Grace-Grace superchip, a tightly coupled package using NVLink chip-to-chip interconnects that provide memory coherence across the LPDDR5 memory banks and that consumes only around 500 watts, and it gets plenty interesting for the HPC crowd. That yields a total of 144 Arm Neoverse “Demeter” V2 cores with the Armv9 architecture, and 1 TB of physical memory with 1.1 TB/sec of peak theoretical bandwidth. For some reason, probably relating to yield on the LPDDR5 memory, only 960 GB of that memory capacity and only 1 TB/sec of that memory bandwidth is actually available. If Nvidia wanted to do it, it could create a four-way Grace compute module that would be coherent across 288 cores and 1.9 TB of memory with 2 TB/sec of aggregate bandwidth. Such a quad might give an N-1 or N-2 generation GPU a run for the money. . . .
For reference, we did our initial analysis on the Grace chip at launch back in March 2022, drilled down into the architecture of the Grace chip in August 2022 (when no one was sure what Arm core Nvidia was using as yet), and went deep into the Demeter V2 core in September 2023 when Arm released details on the architecture. We are not going to get into the architecture all over again but we will remind you that the Arm V2 core that Nvidia adopted for Grace (rather than design its own core) has four 128-bit SVE2 vector engines, making it comparable to the pair of AVX-512 vector engines in an Intel Xeon SP architecture and therefore able to run classic HPC workloads as well as certain AI inference workloads (those that aren’t too fat) and maybe even the retraining of modestly sized AI models.
The data recently published out of the Barcelona Supercomputing Center and the State University of New York campuses in Stony Brook and Buffalo certainly bear this out. Both groups published some benchmark results pitting Grace-Hopper and Grace-Grace superchips on a wide variety of HPC and AI benchmarks, and it shows what we already surmised: if you look at thermals and probably cost, the Grace CPU is going to be able to pull its weight in HPC.
Both organizations published papers out of the HPC Asia 2024 conference held in Nagoya, Japan last week. The one that came out of BSC is called Nvidia Grace Superchip Early Evaluation for HPC Applications, which you can read here, and the one from the Stony Brook and Buffalo researchers is called First Impressions of the Nvidia Grace CPU Superchip and Nvidia Grace Hopper Superchip for Scientific Workloads, which you can read here. Together, the papers present a realistic view of how key HPC applications perform on Grace-Grace and Grace-Hopper superchips. The paper from the SUNY researchers is more useful perhaps because it brings together performance figures from multiple HPC centers and one cloud builder. To be specific, the data from the second paper draws on performance data from Stony Brook, Buffalo, AWS, Pittsburgh Supercomputing Center, Texas Advanced Computing Center, and Purdue University.
BSC compared the performance of the Nvidia Grace-Grace and Grace-Hopper superchips, which are part of the experimental cluster portion of its MareNostrum 5 system, against the X86 CPU nodes of the prior MareNostrum 4 supercomputer, which was based on nodes comprised of a pair of 24-core “Skylake” Xeon SP-8160 Platinum processors running at 2.1 GHz. Here is a handy dandy block diagram of the MareNostrum 4 nodes compared to the Grace-Hopper and Grace-Grace nodes:
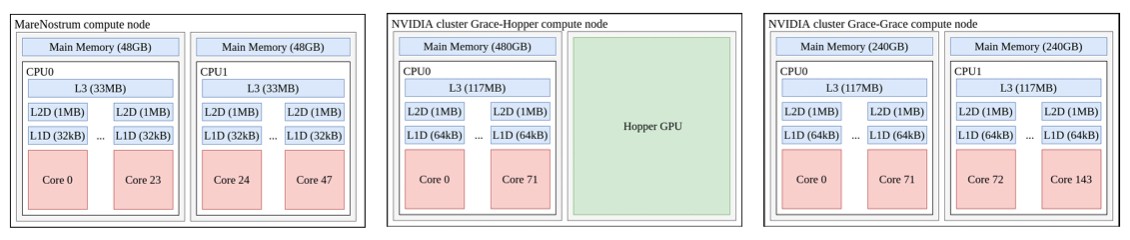
On the Grace-Hopper nodes, BSC only tested various HPC applications on the CPU portion of the superchip. (The Buffalo and Stony Brook team tested the CPU-CPU pair and the CPU-GPU pair in its evaluation of the early adopter Nvidia systems.)
Here is another handy dandy table that BSC put together comparing the architectures of the three systems tested:
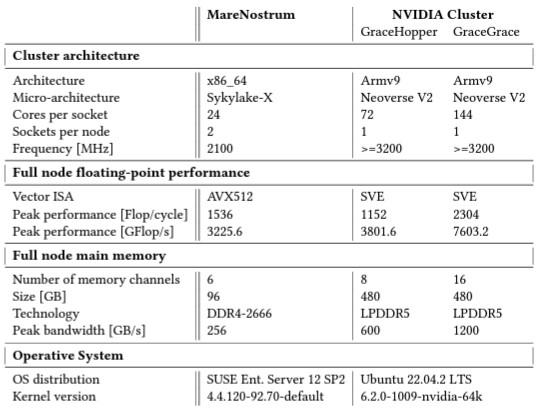
BSC says that the early access versions of the Grace processor had CPUs that were geared down to 3.2 GHz and that the memory bandwidth was also geared down from what Nvidia expected that full production units would have. The exact amount was not quantified, but the unit tested had a clock speed of around 3.2 GHz on the Grace CPU.
As for applications, BSC ran its homegrown Alya computational mechanics code as well as the OpenFOAM computational fluid dynamics, the NEMO oceanic climate model, the LAMMPS molecular dynamics model, and the PhysiCell multicellular simulation framework on the three types of nodes. Here is the rundown on how the Grace-Grace nodes compared to the MareNostrum 4 nodes. We are ignoring the Grace-Hopper nodes since the GPUs were not used and since it should be roughly half the performance of the Grace-Grace nodes. Take a look at these speedups when the same number of cores are used:
- On the Alya application, Grace-Grace was 1.67X faster to 1.81X.
- On OpenFOAM, the speedup with Grace-Grace was 4.49X.
- On NEMO, the speedup was 2.78X.
- On LAMMPS, the speedup was 2.1X to 2.9X for the same number of cores, varying from 1 to 288.
- On PhysiCell, the speedup was 3.24X for the same 48 cores on each node.
Obviously, the Grace-Grace unit has three times as many cores, so the node-to-node performance should be in proportion to this.
The Buffalo and Stony Brook paper also did a bunch of benchmarks and collected results from other machines, as we pointed out above. Here is the table showing the relative performance of the various nodes running the HPC Challenge (HPCC) benchmark, with the Matrix, LINPACK and FFT elements pulled out separately:
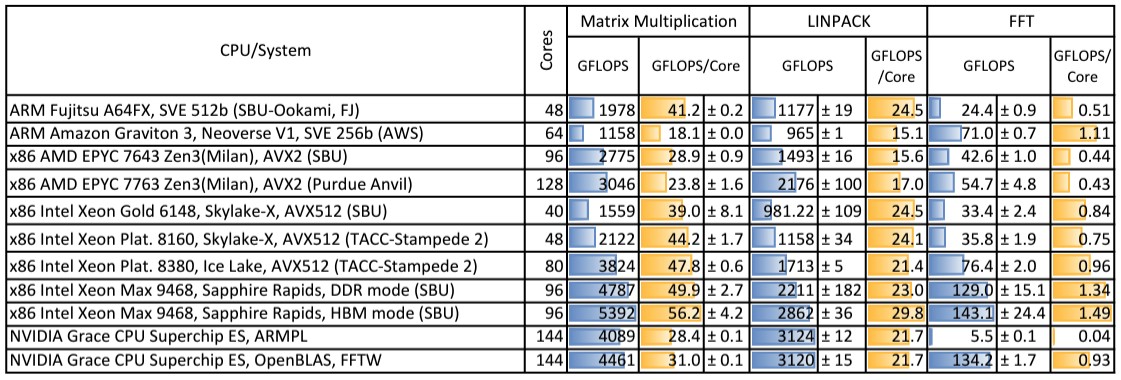
It has been a long time since we have seen benchmark data with error bars, which are obviously always present because of the difficulty of making readings and which most tests do not include. Anyway, at the socket level, the Grace-Grace superchip performance somewhere between an Intel “Ice Lake” and “Skylake” Xeon SP and somewhere higher than a “Milan” and “Rome” AMD Epyc. (Beautiful tables, but the way. Thank you.)
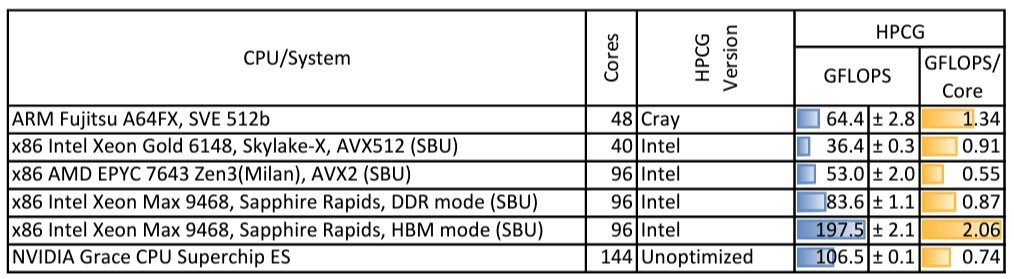
On the much tougher High Performance Conjugate Gradients (HPCG) test, which stresses the balance between compute and memory bandwidth and which often makes supercomputers look pathetic, here is how the Grace-Grace superchip stacked up:
Here is how Grace-Grace stacked up on OpenFOAM, using the MotoBikeQ simulation with 11 million cells across all machines:
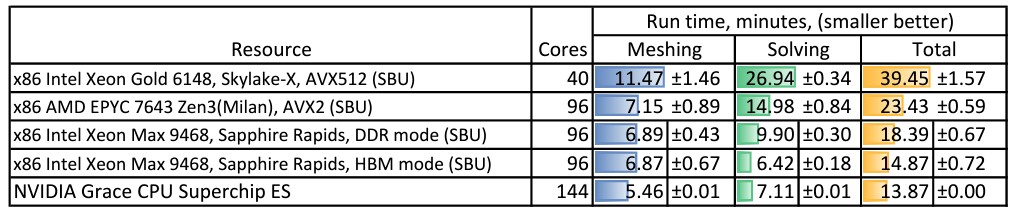
We would have expected for the Grace-Grace unit to do better here in the Solving part. Hmmm.
And finally, here is how the Gromacs molecular dynamics benchmark lined up on the various nodes, with both CPU-GPU and CPU-only variations:
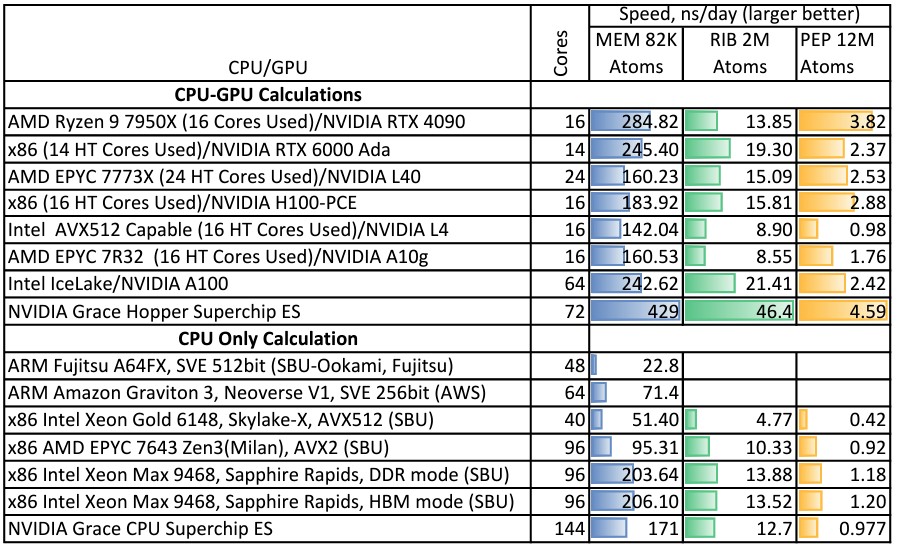
We have a winner! Look at how well that Grace-Hopper combination does. But any CPU paired with the same Hopper GPU would probably do as well. On the CPU-only Grace-Grace unit, the Gromacs performance is almost as potent as a pair of “Sapphire Rapids” Xeon Max Series CPUs. It is noteworthy that the HBM memory on this chip doesn’t help that much for Gromacs. Hmmmm.
Anyway, that is some food for thought about the Grace CPU and HPC workloads. There are other benchmarks in the Buffalo and Stony Brook paper, so be sure to check them out.