


Other than Hewlett Packard Enterprise, who wants to build the future NERSC-10 supercomputer at Lawrence Berkeley National Laboratory or the future OLCF-6 system at Oak Ridge National Laboratory? Anyone? OK, yes, we see you, Microsoft, and you, Amazon Web Services, raising your hands at the back of the room. Yes, we see you. Put your hands down, please. Anyone else?
Yeah, that’s what we thought.
Lawrence Berkeley put out the request for proposal technical requirements for the kicker to the current “Perlmutter” system on September 15, and Oak Ridge followed suit with its RFP technical requirements for the kicker to the “Frontier” system on September 27, and we can’t help but wonder what kinds of options both labs, and indeed any of the US Department of Energy national labs, has when it comes to acquiring their next-generation supercomputers.
Intel has had quite enough of being a prime contractor for supercomputers, and chief executive officer Pat Gelsinger has come to his senses and stopped talking about reaching zettascale – 1,000 exaflops – by 2027. Gelsinger dropped that mike on the stage two years ago talking to us at a briefing, and we did the math that showed if Intel could double the performance of its CPUs and GPUs every year between 2021 and 2027, it would still take 116,000 nodes and consume 772 megawatts to achieve zettascale. As far as we can tell, that mike drop broke the mike. And the Raj.
IBM is done with being a prime contractor, too, after losing money building massive machines in the past, and has focused on AI inference as its key HPC workload. Years ago, Nvidia and Mellanox worked independently with IBM on pre-exascale systems, which were installed at Lawrence Livermore National Laboratory and Oak Ridge, and at some point, Nvidia was making so much money from AI training that it no longer needed to care about HPC simulation and modeling like it did from 2008 through 2012. If Nvidia doubled its HPC business, it would have barely showed up in the numbers in 2019 and 2020, and these days, it would be a rounding error thanks to the generative AI explosion.
There is no way that Atos or Fujitsu can sell into US government labs. Dell could do it, but its stomping grounds at the University of Texas seem to be enough to whet its HPC appetite and to wave the American flag patriotically. (Michael Dell doesn’t like to lose money.)
Who is left? Yes, we see you, Microsoft and AWS and even Google. But you have your own issues, as we have recently reported, and among them is you talk big but people can’t really rent big. The perception of infinite capacity, with an easy on and easy off switch, is largely an illusion – especially at the scale of national supercomputing centers that will need tens of millions of concurrent cores to do their work and networks that interlink them at high bandwidth and low latency.
Lawrence Berkeley – and specifically, the National Energy Research Scientific Computing Center at the lab – put out a request for information from vendors regarding its NERSC-10 machine back in April, in which we did some prognosticating and complaining, and we are not going to repeat all of that here. We will show you the supercomputer roadmap at the lab as a reminder, however:
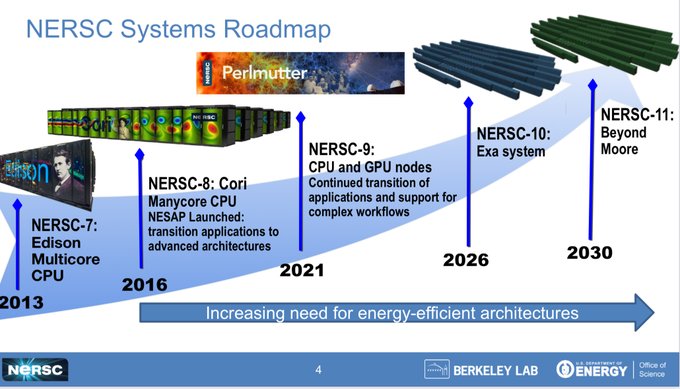
The RFP technical requirements document is not the RFP, but kind of a preview to get the juices going amongst those who will try to compete for the right to break even on the deal. The RFP for NERSC-10 will come out on February 5, 2024 and after a period of time for questions and answers, the proposals from vendors will be due on March 8, 2024. An early access machine has to be delivered in calendar 2025, the NERSC-10 system has to be delivered in the second half of 2026, and the system acceptance – and therefore when the prime contractor gets paid – is anticipated to happen in 2027.
The technical documents are a long shopping list of features and functions, but there is not much in the way of precision because Lawrence Berkeley is trying to keep an open mind about open architectures and complex HPC and AI workflows and their interplay. Nick Wright, leader of the Advanced technologies Group at Lawrence Berkeley and architect of the NERSC machines, gave a presentation at the recent HPC User Forum meeting saying that HPC was at an inflection point and that the HPC industry and the HPC community – these are not the same thing, according to us – need to deal with the end of Moore’s Law and the rise of AI.
The goal is for NERSC-10 to deliver at least 10X the performance of Perlmutter on HPC workloads. Lawrence Berkeley has a suite of quantum chromodynamics, materials, molecular dynamics, deep learning, genomics, and cosmology applications that are being used to gauge that 10X performance boost. We get the distinct impression that if a massively parallel array of squirrels running on mousewheels with abacuses in their front paws for doing calculations delivered better performance and better performance per watt than a hybrid CPU-GPU architecture, then all of the national labs would be buying up peanut farms and designing datacenters that looked like commercial chicken coops from days gone by built as an array of treehouses.
Four years ago, Hyperion was saying that saying that NERSC-10 would weigh in at somewhere between 8 exaflops and 12 exaflops of peak performance, but was also saying that Frontier would be somewhere between 1.5 exaflops and 3 exaflops peak and that El Capitan at Lawrence Livermore would be between 4 exaflops and 5 exaflops. Take a lot of salt with that. And you won’t be able to see how far that is off from reality because no matter what the NERSC-10 machine ends up being, Wright says the RFP will not have a peak flops measure. Wright added that Lawrence Berkeley is trying to expand the pool of vendors, including those who have not responded to a “leadership class” RFP from the US Department of Energy before.
The NERSC-10 RFP technical document are short on details – sadly – but the proposed system has to fit within a 20 megawatt maximum power draw and fit in a system footprint of 4,784 square feet. This being NERSC, energy efficiency is of the utmost importance, and it goes without saying that the machine has to be water cooled given the heat density of that tight space. (Just like Perlmutter is.)
Some 2,465.8 miles just a little south of due east from the communal hills of the University of Berkeley is Oak Ridge, nestled in the wild hills of eastern Tennessee. And that is where the RFP technical document for the OLCF-6 system was released to give HPE and any competition that might want to come up against it a chance to think about bidding on NERSC-10 and the OLCF-6 kicker to Frontier at the same time.
Here is an old roadmap that suggests what the goals for Frontier and its follow-on would be back in 2019 or so:
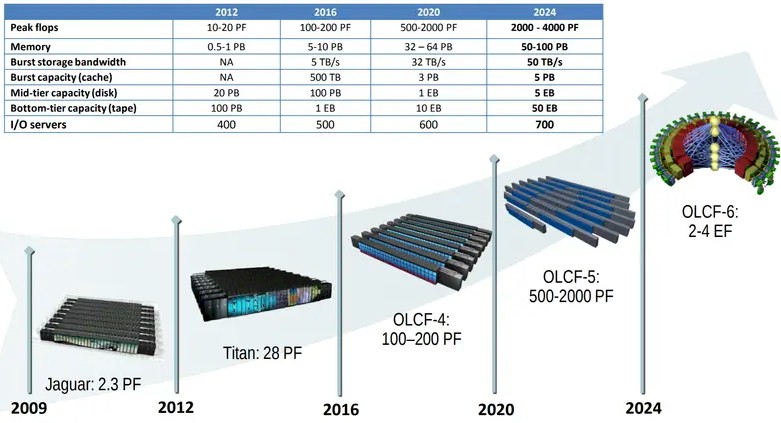
The “Summit” OLCF-4 machine hit its top-end performance target, and the Frontier OLCF-5 machine almost hit its top-end. If you assume that the machines launched in the middle of those time frames, then they are right on track with deliveries in 2018, 2022, and expected in 2027. But the “Jaguar” system was delivered in 2009 and “Titan” came in 2012, so the lines were the expected dates when this roadmap was drawn, probably sometime in 2014.
It’s OK. Everybody’s HPC roadmap was stretched a few years, and we think it will stretch even further, under the influence of the gravity of the Moore’s Law situation, in the next ten years.
Anyway, way back then, OLCF-6 was expected to weigh in at somewhere between 2 exaflops and 4 exaflops peak, with history guiding that up to 4 exaflops. The RFP technical requirements document says that by 2028, Frontier will be nearing its end of life. Before that day comes – specifically, in 2027 – OLCF-6 needs to be in place. Oak Ridge is willing to take bids for an upgrade to Frontier, whole new system designs, as well as off-premises systems – by which we presume it means hyperscalers and cloud builders. Oak Ridge is also welcoming bids on a parallel file system and an AI-optimized storage system separately for those who want to do that. (That means you, DataDirect Networks and Vast Data.)
Oh, and by the way, if the Frontier successor is not located in the state of Tennessee, there is a 9.75 percent sales tax that has to be part of the bid. So, say welcome to the US-East Knoxville datacenter region. . . .
Whatever the successor machine, it has to fit in a 4,300 square foot area in the Oak Ridge datacenter and it has to fit in a 30 megawatt power draw. There is no target as yet to application performance, but the list of applications in the OLCF-6 benchmark suite – LAMMPS, M-PSNDS, MILC, QMCPACK, SPATTER, FORGE, and Workflow – that covers a lot of the same bases as the NERSC-10 benchmark suite in HPC simulation and AI training.
It is hard to imagine that anyone but HPE will bid on these deals, but the government has to have more than one bidder. It may have to create one at this point, which is something we suggested in covering NERSC-10 earlier this year.
The real inflection point, and the question it drives, is whether HPE peddling an on-premises system can beat out Microsoft or AWS in winning these two deals. The cloud builders would have to do some things differently – acting more like a hosting company than a cloud, investing in real HPC interconnects that provide good performance on both HPC and AI workloads, and so on – but they may be the only ones who have deep enough pockets to do the job to push higher than exascale.
The only trouble is, they won’t do it at cost or less like SGI, IBM, Intel, and HPE have done in the past. This is a real quandary, particularly if AMD no longer needs Uncle Sam as an investment partner in its CPU and GPU efforts, as it most definitely did for the Frontier and El Capitan machines. Immunity from prosecution and the ability to build monopolies are something that the US government can trade to get its HPC/AI supercomputers on the cheap, but we don’t hear anyone talking about such a bold quid pro quo. Yet.