


What is the most expensive component that hyperscalers and cloud builders put into their X86 servers? It is the GPU accelerator, correct. So let’s ask this question another way: What is the most expensive component in the more generic, non-accelerated servers that comprise the majority of their server fleets? Main memory, correct again.
If you do the math on what things costs over time, about a decade ago the CPU used to comprise about half of the basic server cost in the datacenter for infrastructure workloads; HPC systems were a little more intense on cores and a little less intense on memory. Memory was about 15 percent of the system cost, the motherboard was about 10 percent, and local storage (which was a disk drive) was somewhere between 5 percent and 10 percent, depending on how fat or fast you wanted that disk. The power supply, network interfaces, and chassis made up the rest, and in a lot of cases the network interface was on the motherboard already, so that cost was bundled in already except in cases where companies wanted a faster Ethernet or InfiniBand interface.
Over time, flash memory was added to systems, main memory costs for servers spiked through the roof (but have some down some relative to the price of other components), and competition returned to X86 CPUs with the re-entry of AMD. And so the relative slice sizes in the server cost pie for generic servers widened and shrank here and there. Depending on the configuration, the CPU and the main memory comprise about a third of the cost of the system each, and these days, memory is usually more expensive than the CPU. With the hyperscalers and cloud builders, memory is definitely is the most expensive item because the competition is more intense on the X86 CPUs, driving the cost down. Server main memory is in relative short supply – and intentionally so as Micron Technology and Samsung and SK Hynix Flash and disk together are around 10 percent of the cost, the motherboard is around 5 percent of the cost, and the rest is the chassis and other peripherals.
An interesting aside: According to Intel, the CPU still represents about 32 percent of the IT equipment power budget, with memory only burning 14 percent, peripheral costs around 20 percent, the motherboard around 10 percent, and disk drives 5 percent. (Flash is in the peripheral part of the power budget pie, we presume.) The IT equipment – compute, storage, and networking – eats a little less than half of the power, and power conditioning, lighting, security systems, and other aspects of the datacenter facility eat up a little more than half, and that gives a rather pathetic power usage effectiveness of 1.8, more or less. The typical hyperscale and cloud builder datacenter has a PUE of around a 1.2.
Suffice it to say, memory is a big cost factor, and with plenty of applications being constrained on memory bandwidth and memory capacity, disaggregating main memory from the CPU, and indeed any compute engine, is part of the composable datacenter that we write about a lot here at The Next Platform. And the reason is simple: We want the I/O coming off the chips to be configurable, too, and that means, in the long run, converging the memory controllers and PCI-Express controllers, or coming up with a generic transport and controller that can speak either I/O or memory semantics depending on what is plugged into a port. IBM has done the latter with its OpenCAPI Memory Interface on the Power10 processor, but we think over time Intel and others will do the former with the CXL protocol running atop the PCI-Express transport.
Chip maker Marvell, which no longer is trying to sell its ThunderX family of Arm server CPUs into the datacenter, nonetheless wants to get in on the CXL memory game. And to that end, back in early May it acquired a startup called Tanzanite Silicon Solutions for its Smart Logic Interface Connector, which is a CXL bridge between CPUs and memory that is going to help smash the server and stitch it back together again in a composable way – something we have been talking about since before The Next Platform was established. Tanzanite was founded in 2020 and demonstrated the first CXL memory pooling for servers last year using FPGAs as it is putting the finishing touches on its SLIC chip.
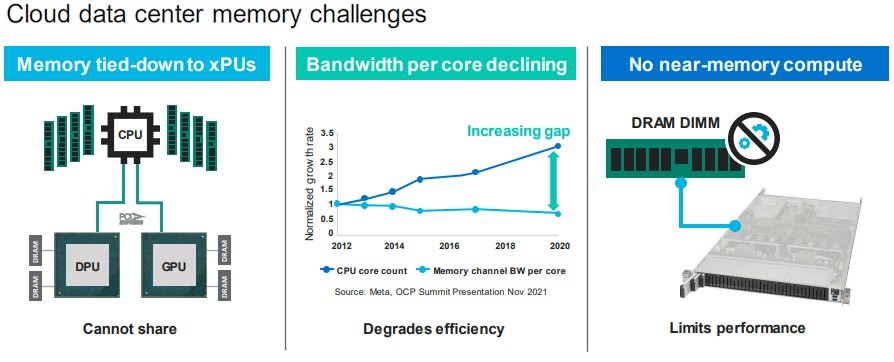
As Omura points out in the chart above, another issue is that core counts on CPUs are expanding faster than memory bandwidth, so there is a widening gap between the performance of the cores and the DIMMs that feed them, as the Meta Platforms data above shows. And finally, aside from some science projects, there is no way to aggregate memory and move compute closer to it so it can be processed in place, which is limiting the overall performance of systems. Gen Z from Hewlett Packard Enterprise, OpenCAPI from IBM, and CCIX from Xilinx and the Arm collective were all contenders to be a converged memory and I/O transport, but clearly Intel’s CXL has emerged as the standard that everyone is going to rally behind in the long run.
“CXL is gaining a lot of traction, and are working with basically all the major hyperscalers on their architectures, helping them figure out how they are going to deploy this technology,” says Omura. Hence, the Tanzanite acquisition, the value of which was not disclosed, which closed at the end of May.
With the SLIC chip, Marvell will be able to help the industry create standard DIMM form factors with CXL expander controllers as well as fatter and taller expanded memory modules that are larger than DIMM form factors. (IBM has done the latter with several generations of its Power Systems servers and their homegrown “Centaur”: buffered memory controllers.)
The first thing that CXL memory is going to do its open up the memory bandwidth over both the DRAM and PCI-Express controllers on modern processors, says Omura. And we agree.
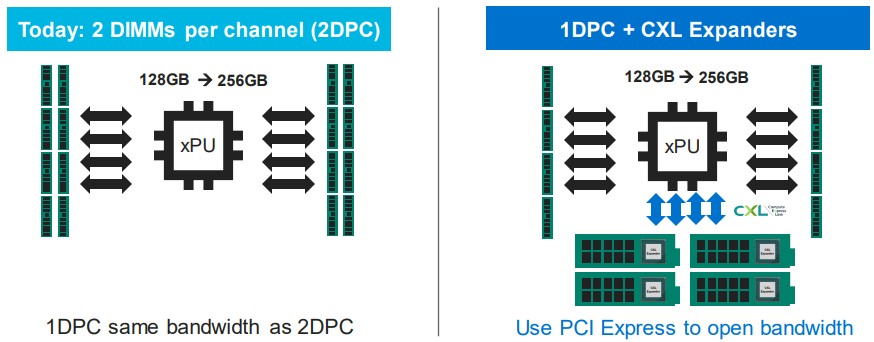
If you have a system today and you have a set bandwidth across its memory slots, you can increase capacity by adding two DIMMs per memory channel, but then each DIMM gets half the memory bandwidth. But with the addition of CXL memory DIMMs to the system using the SLIC chip, you can use a significant portion of the PCI-Express bus to add more memory channels to the system. Admittedly, the bandwidth coming out of PCI-Express 5.0 slots is not as high and the latency is not as low as with the DRAM controllers on the chip, but it works. And at some point, when PCI-Express 6.0 is out, there may not be a need for DDR5 or DDR6 memory controllers in certain classes of processors, and DDR controllers may turn into exotic parts much as HBM stacked memory is exotic and only for special use cases. The hope to CXL memory over PCI-Express 5.0 and 6.0 will not be much worse (if at all) than going through the NUMA links to an adjacent socket in a multi-socket system, and it may be even less of a hassle once CXL ports literally are the main memory ports on systems and DDR and HBM are the specialized, exotic memory that is only used when necessary. At least that’s what we think might happen.
The CXL memory expansion is just the first stage in this evolution. It won’t be long before CXL chips like Marvell’s SLIC will be used to create shared memory pools across diverse – and often incompatible –compute engines, and even further down the road, we can expect for there to be CXL switching infrastructure that creates a composable fabric between different types of memory devices and different kinds of compute engines. Like this:

In the full vision that Marvell has, sometimes there will be some local memory on XPUs – the X is a variable for designating CPU, GPU, DPU, and so on – and a CXL ink over PCI-Express will hook out to a memory module that has integrated compute on it for doing specialized functions – and you can bet that Marvell wants to use its custom processor design team to help hyperscalers, cloud builders, and anyone else who has reasonable volumes put compute on memory and link it to XPUs. Marvell is also obviously keen on using the CXL controllers it is getting through the Tanzanite acquisition to create SmartNICs and DPUs that have native CXL capabilities and composability in their own right.
And then, some years hence, as we have talked about many times, we will get true composability within datacenter racks, and not just for GPUs and flash working over PCI-Express. But across compute, memory, and storage of all kinds.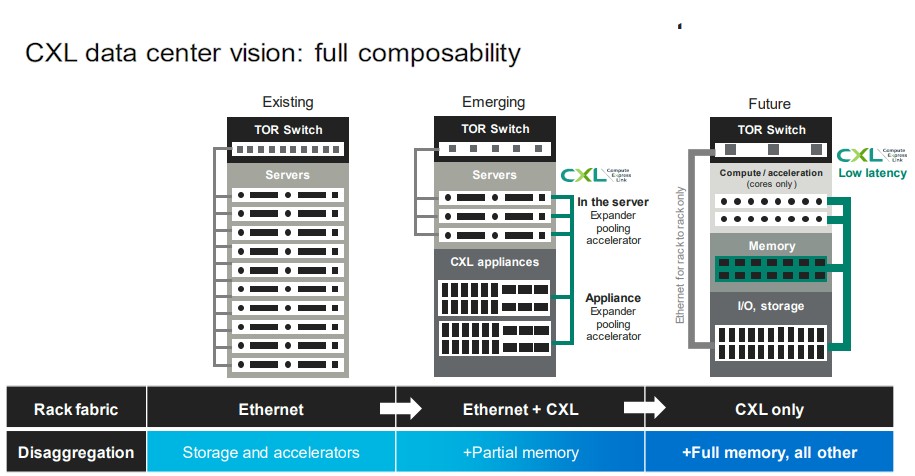
Marvell already has the compute (Octeon NPUs and custom ThunderX3 processors if you want them), DPUs and SmartNICs, electro-optics, re-timers, and SSD controllers needed in datacenter server and rack architectures, and now Tanzanite gives it a way to supply CXL expanders, CXL fabric switches, and other chippery that together comprise what Omura says is a “multi-billion dollar” opportunity.
This is the opportunity that Tanzanite was created to chase, and here are the prototype use cases it had envisioned prior to the Marvell deal:

We think every one of these machines above will sell like hot cakes – provided the DRAM memory comes down in price a bit. Memory is still too expensive.