



Ever-increasing Greek prefixes of flops is what makes the simulations and models of the world hum, but we at The Next Platform like money. And that is because money determines the kind and the amount of flops that people can afford to deploy to run their simulations and models. Money, or the lack thereof, is what makes architectural choices as much as any key technological factor.
With so many pre-exascale supercomputing systems being launched in the past several months – the latest being the 180+ petaflopping “Aurora” system being built by Intel for Argonne National Laboratory – it got us to thinking not only about just how far we have come in the past four decades in supercomputing in terms of the aggregate performance that can be crammed into systems. We also started wondering how the bang for the buck of the machines has changed over time.
Good luck trying to find that out.
The HPC industry does a great job tracking the performance of every architecture under the sun, and the people buying and running the upper echelon of systems certainly know what they cost to acquire, operate, and upgrade. But piecing together any sort of price/performance data over time for supercomputers is not trivial, as we discovered. We are the sporting type here at The Next Platform, if for no other reasons than to make a point and to get the industry to provide us the hard data that we crave. So in the absence of precise data, we combed through the archives and dug up pricing and basic configuration information on some of the biggest HPC iron built in the past couple of decades to see how far we are coming along on that price/performance curve.
Show Me The HPC Money
The short answer is that it is a lot easier to build a faster supercomputer than it is to bring the cost of calculations down. The good news is that the industry is, generally speaking, doing a remarkable job staying on Moore’s Law for peak raw performance, despite the engineering challenges. But these capability-class supercomputers are still exotic and expensive pieces of machinery and the cost of calculation is not falling anywhere near as fast as the aggregate performance is rising.

This makes sense. First, compute capacity will expand to consume all available budget in an HPC niche, but at the same time no system vendor is going to be so foolish as to deliver far more compute for the same money today when it knows it has to be able to sell an upgrade or a new system two to three years from now to remain in business. This is, once again, about the money, not just the flops.
Route 128, Highway 101, and a few windy roads in Minnesota, New York, and Wisconsin are littered with the hulking carcasses of supercomputing makers who did not understand this – and we have loved many of them for the brilliance of their engineering and the audacity of their business plans. HPC was perhaps the only place in IT where there was swashbuckling, at least until the Googles of the world warped into hyperscale and bent the IT sector around them like a neutron star. And that isn’t swashbuckling so much as it is an aircraft carrier coming into port, anyway. But we digress – often, and generally with enthusiasm.
Help Us Help You
The publicly available information on the pricing of large-scale HPC systems is a bit thin, but this is what we have to work with. To get a sense of the evolution of performance and price/performance over time, we started out with the Cray 1A system installed at the National Center for Atmospheric Research. We could have gone further back to earlier IBM and Control Data Corporation machinery, but there is a limit to how much you can get done in a few hours. Suffice it to say that we know that there have been calculating machines that can be thought of the supercomputers of their day as long as there have been data processing systems that counted the money. We draw the line at 1977 because that is when Seymour Cray popularized the idea of a supercomputer and not only created a brilliant machine, but laid down the foundations of the HPC industry that we know today.
Our table ends with the IBM “Summit” and Intel/Cray “Aurora” systems that are due in 2017 and 2018, respectively, and that will deliver at least 150 petaflops and 180 petaflops, respectively. And possibly more than that if the vague statements from their makers are any guide. Summit could be expanded to 300 petaflops and Aurora to 450 petaflops, if you read the fine print in the announcements, and it is never made clear to those of us on the outside if the prices for these contracts (or any prior ones where money is mentioned) include such upgrades as a matter of course.
Take a gander at a few points on the line of four decades of supercomputing history:
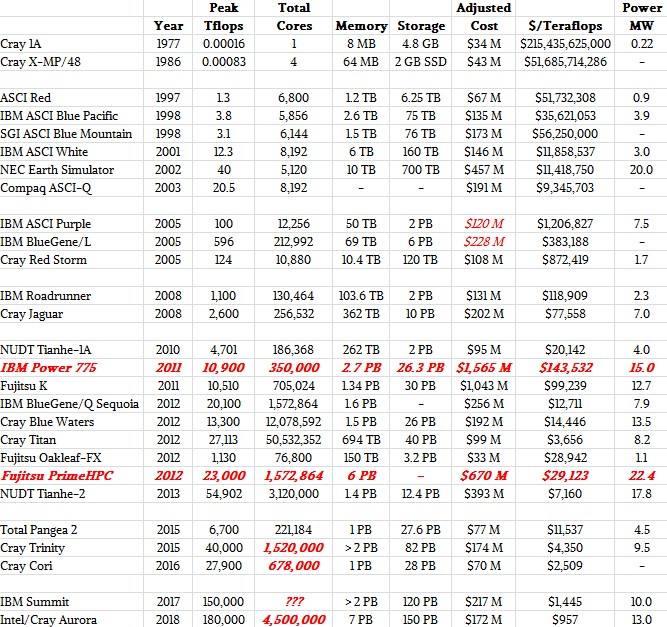
There is, admittedly, a lot of fuzzy data in this table, and it is not meant to be exhaustive but illustrative.
Frankly, as tax-paying citizens, we think government-supported supercomputing efforts and indeed any massive publicly funded projects should have their full cost available somewhere, and it should be updated as it changes, too. We used the data we could find because we wanted to get a general sense of the trends. We are aware that these contracts include services and software and other parts of the system, not just the compute elements, and we agree that it would also be useful to see what the compute, memory, interconnect, and storage all cost in these behemoths of their eras. But as you can see from the table, compute, memory, and storage all tend to scale – with very wide bars, of course, because of architectural and application differences – with each other.
Which brings us to another point we are well aware of, and that is that we are mixing data for a large number of different architectures over time and within a time. We tried to deal with some of the time factor by adjusting the costs of machines with the inflation rate in the United States, so all of the values shown in the table above are in 2015 dollars. We are using the Cray 1A and Cray X-MP/48 machines at NCAR to represent their decades, and are well aware that this is an oversimplification. But if you do the math, it surely does show you just how quickly the cost of a floating point operation came down over time. Our table shows teraflops for performance and cost per petaflops for price/performance, and this is just to keep the significant digits in the columns manageable. (The Cray 1A was rated at 160 megaflops, not zero as it shows in the chart. The Cray X-MP was around 833 megaflops as far as we can tell.)
Any items in red are estimates. The data for the late 1990s and early 2000s comes from the Department of Energy’s Accelerated Strategic Computing Initiative, which spent billions of dollars to revitalize the indigenous supercomputing business in the United States and to experiment on innovative and competing system designs. Significantly we broke apart the $290 million contract for ASCI Purple and BlueGene/L machines along the lines that make sense to us and adjusted the contract for inflation.
IBM’s “Roadrunner” built for Los Alamos National Laboratory and Cray’s “Jaguar” for Oak Ridge National Laboratory represent the late 2000s in our table. Just for fun, in the late 2000s, we put in the cost of a fully loaded Power 775 cluster at list price, and also added in a fully loaded Fujitsu PrimeHPC system. No one has, to our knowledge, ever bought either of these machines full out. We added in the feeds and speeds of the new Pangea 2 machine that was just installed by oil giant Total, and we realize that this is an all-CPU machine and a commercial system to boot with an upgrade built in.
For the most recent DOE big machines – Trinity, Cori, Summit, and Aurora – we have estimated the number of cores we think might be in the systems. There are too many variables in the Summit machines in terms of the number of IBM Power9 and Nvidia Tesla coprocessors in each system node and how many cores each might have to make a guess. Suffice it to say the Summit system will have many millions of cores spread across its computing elements.
The pricing data is a bit rough, and we realize this. In some cases, the contract price could more accurately be described as a system upgrade, not a new system. In others, the contract price shown could be for the initial system and a later upgrade – again, the publicly available information is vague and hence so is our table.
None of this takes anything away from our larger point, and that is the price/performance of these upper-echelon machines has improved dramatically over time. Take a look at this scatter graph:
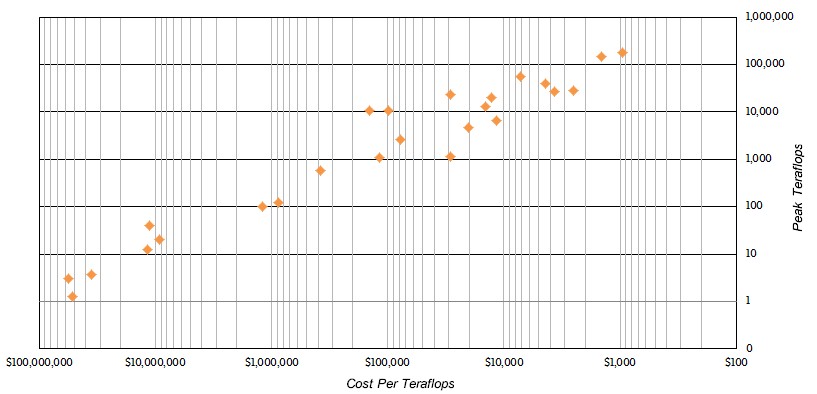
The performance between 1977 and 2018, book-ended by the Cray 1A and the Intel/Cray Aurora system, will have increased by a factor of 1.125 billion. If Aurora goes to 450 petaflops at some later date, as the Intel documents suggested could happen, then that will represent a performance jump of a factor of 2.81 billion over the Cray 1A. Not too shabby, and for those who will complain that these numbers are for peak theoretical performance, it was tough to get anywhere near 50 percent of peak on the old Cray systems just like it is tough to get close to peak performance on modern systems, even running benchmarks like LINPACK. Fujitsu’s K super hits an amazing 93 percent efficiency on LINPACK, and IBM’s BlueGene/Q hits 85 percent, but the top-ranked NUDT Tianhe-2 hybrid Xeon/Xeon Phi machine only hits 62 percent and the Cray Titan machine, which mixes Opterons CPUs and Tesla GPUs, only hits 65 percent. There are memory bandwidth issues with these hybrid machines, which are being fixed in the next-generation systems like Summit and Aurora.
What we want to talk about is the money. In the chart above, both the X axis, which shows the cost of a petaflops for each of the systems in the table, and the Y axis, which shows the performance in teraflops of the systems in the table, are both on log scales (base 10). For some reason, Excel will not allow us to add in the second set of log scale minor gridline indicators on the Y axis, but it is not on a linear scale no matter what the chart seems to say. Our point is to show that the progress on both the performance and price/performance front has been about as steady as can be expected under the circumstances.
But our larger point is that as performance has increased by more than a factor of 1 billion over the time shown in the table, the improvement in bang for the buck has improved by only a factor of 225 million. This is still impressive, mind you. But the cost of the most capable HPC systems in the world still remains fairly high.