


Last year, amid all the talk of the “Blackwell” datacenter GPUs that were launched at last year’s GPU Technicval Conference, Nvidia also introduced the idea of Nvidia Inference Microservices, or NIMs, which are prepackaged enterprise-grade generative AI software stacks that companies can use as virtual copilots to add custom AI software to their own applications.
For the rest of 2024, Nvidia continued to build on the NIMs idea, including later in the summer at Hot Chips with the rollout of NIM Agent Blueprints, reference AI workflows compete with sample applications that included not only NIMs but also partner microservices and other resources for developing and deploying custom GenAI applications.
Last summer, Nvidia was talking about a NeMo-based framework to create a “data flywheel,” a continuous learning cycle where the custom AI applications through exposure to enterprises’ data and interacting with users generate data that can be fed back into the process, improving the applications and the models that helped build them. Nvidia executives also talked about work they were doing with Accenture, Deloitte, and Quantiphi to use the NIM Agent Blueprints and NIMs and NeMo microservices to create custom AI software and services for their own clients.
The AI computing giant took another step in that direction this week, announcing the general availability of NeMo microservices developers can use to create agentic AI systems that are constantly being improved through the data flywheel process that spins back in inference, data business data, and user inputs.
“The microservice software … can automate and scale these flywheels to ensure that agents – or ‘Ai teammates’ – are very accurate and have the latest information based on the business and the customer interactions,” Joey Conway, senior director of generative AI software for enterprise at Nvidia, told journalists during a briefing this week.
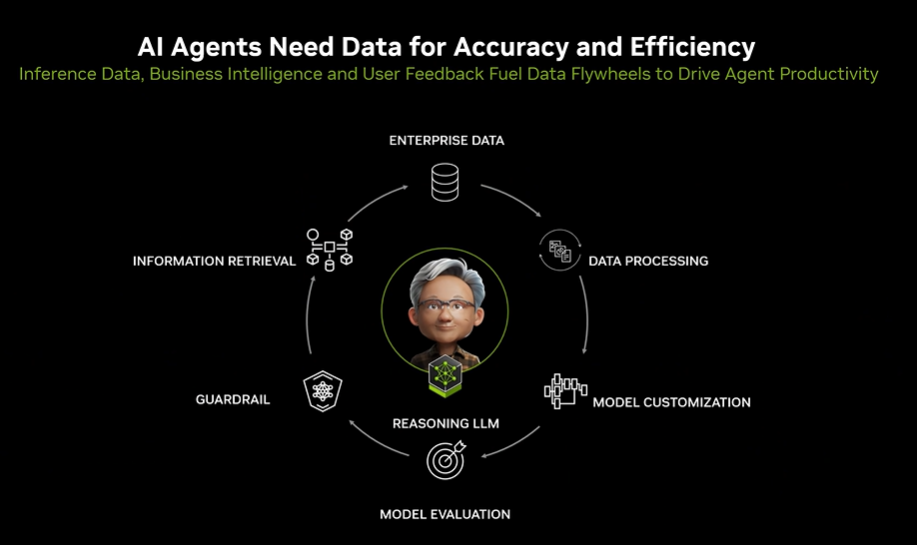
The Data Flywheel
The idea of a data flywheel essentially goes to the heart of generative and every other form of AI – that systems and software not only need data to be useful and relevant, but the data needs to be continuously added to and updated.
The models behind AI agents need to be maintained and improved through a continuous flow of inputs to ensure that the agents’ understanding of the world around them doesn’t falter, which he said could hurt their reliability and productivity.
“Every AI agent will need a data flywheel,” Conway said. “The data flywheel is how we can go from enterprise data – things like inference data, business intelligence, and user feedback – to be able to power and improve the agents so that it learns and grows, brings in new capabilities and skills as well as learns from its experiences.”
Through this process, AI agents can take their place as useful partners to what he said could be as many as a billion workers around the world.

Nvidia’s NeMo microservices – which are deployed via Nvidia’s AI Enterprise software platform – pass data along a chain, starting with NeMo Curator for processing data at scale for training and customization. Enterprise data is constantly changing and growing, Conway said.
NeMo Curator lets organization declassify it and deduplicate it so the model can focus on the most relevant information and then pass it onto NeMo Customizer, which uses the most advanced training techniques to teach models new skills and knowledge to ensure they stay up-do-date.

The techniques include supervised find tuning and low-rank adaptation. Low-rank adaption is used with large language models by training low-ranked matrices instead of the entire model, reducing memory requirements and making the process more efficient.
The next step is NeMo Evaluator to ensure the AI agent actually improved and gained new skills and didn’t regress, Conway said, adding that “we do that by incorporating some of the latest, state-of-the-art techniques as well as enabling enterprises to build their own evaluations for skills that are important to them.”
That’s deployed with NeMo Guardrails to ensure the AI agent can stay on topic, remain focused, and avoid missteps around content, safety, and security.
“As we put these models back into production, we also have NeMo Retriever to ensure we maintain the highest accuracy and reduce the number of incorrect answers, but we do that in such a way that we can scale up and support many concurrent agents handling many concurrent employee or customer interactions,” he said.
Separation Of NeMO And NIM Duties
NeMo microservices and NIMs play different but complementary roles in the agentic AI world, Conway said.
“The way we think about it is NIMs [is used for] inference deployments – running the model, questions-in, responses-out,” he said. “NeMo is focused on how to improve that model: Data preparation, training techniques, evaluation. When NeMo is finished, that model is deployed back into a NIM.”
Nvidia also is unveiling a long list of high-profile companies like AT&T (which with Arize and Quantiphi built an AI agent to process a knowledge base of almost 10,000 documents that is reworked every week. Cisco’s Outshift emerging tech unit and Galileo are using the NeMo microservices to build a coding assistant that is has 10 times the response time of similar tools and reduces tool selection errors by 40 percent.
Multiple Model Support
The microservices support such open models as Meta’s Llama, Google Gemma, Mistral, and Microsoft’s Phi collection of small language models. It also supports Nvidia’s Llama Nemotron Ultra AI reasoning model.
Software makers like Cloudera, DataStax, Datadog and SuperAnnotate are support the NeMo microservices, while developers can use them in such AI frameworks as LangChain, LlamaIndex, and Deepset. Enterprises can use NeMo Retriever microservices and Nvidia AI Data Platform from storage companies like Hewlett Packard Enterprise, Dell Technologies, IBM, NetApp, and VAST Data.
Conway said he expects Nvidia’s efforts in this area to grow, both to add to what can be done and to push the industry along.
“With microservices, each are like a Docker container,” he said. “The orchestration today, we rely on things like Kubernetes, so we have additional features like Kubernetes Operators that help orchestrate it. We have some software today to help with the data preparation and curation. There will be a lot more coming there. This is a new domain that we’d love to see more activity in. There hasn’t been as much we had hoped, so I expect we will be helping out there as well, making sure partners are able to collect the right information and then we’re able to feed that back into the data flywheel.”