


When you get to the place where Intel is at in datacenter compute, you cannot dictate terms to customers. You have to listen very carefully and deliver what customers need or one of myriad different competitors will steal your milk money, eat your lunch, and send you to bed without dinner.
With this in mind, and looking at the past decade and a half of increasing diversification of compute engines at Intel (and in the market at large) and the end of Moore’s Law, it is no surprise that Intel bought FPGA maker Altera, bought neural network processor makers Nervana Systems and Habana Labs, and has started up a discrete GPU compute engine business for the second or third time, depending on how you want to count the “Knights” family of many-cored X86 processors from the middle 2010s that spun out of its canceled “Larrabee” GPU project, which had a short life between early 2008 and late 2009. (You could think of Larrabee as a “software-defined” GPU running on X86 cores with 512-bit vector co-processors, with a lot of the GPU functions implemented in software.)
From the outside, considering all of the threats there are to Intel’s hegemony in datacenter compute, it may seem like Intel is overcompensating with variety in its compute engines, trying to block the advances of each and every competitor to the vaunted Xeon SP CPU that still dominates the compute in the datacenters of the world. But we don’t think the situation is that simple. We think that Intel is listening to customers, while at the same time trying very hard not to get burned as it di with the $16.7 billion acquisition of Altera, which was done because Intel’s CPU core business was threatened by the addition of FPGA-based SmartNICs to servers at Microsoft Azure and to the rise of SmartNICs more generally and now the broader compute devices known as Data Processing Units, or DPUs, which are in essence whole servers in their own right that are having big chunks of the storage, networking, and security functions formerly performed on server CPUs offloaded to them.
There is a certain amount of shoot at anything that moves going on, but we also think that Intel is listening very carefully to what customers are asking for and has come to a realization (which many of us have been talking about for a long time) that the era of general-purpose computing solely on the X86 CPU is over. AMD buying FPGA maker Xilinx for $49 billion and soon thereafter buying DPU maker Pensando for $1.9 billion just makes our point.
What customers are no doubt telling Intel and AMD is that they want highly tuned pieces of hardware co-designed with very precise workloads, and that they will want them at much lower volumes for each multi-motor configuration than chip makers and system builders are used to. Therefore, these compute engine complexes we call servers will carry higher unit costs than chip makers and system builders are used to, but not necessarily with higher profits. In fact, quite possibly with lower profits, if you can believe it.
This is why Intel is taking a third whack at discrete GPUs with its Xe architecture and significantly with the “Ponte Vecchio” Xe HPC GPU accelerator that is at the “Aurora” supercomputer at Argonne National Laboratory. And this time the architecture of the GPUs is a superset of the integrated GPUs for its laptops and desktops, not some Frankenstein X86 architecture that is not really tuned for graphics even if it could be used as a massively parallel compute engine in a way that GPUs have been transformed from Nvidia and AMD. The Xe architecture will be leveraged for graphics and compute, spanning from small GOUs integrated with Core CPUs for client devices, to discrete devices for PCs and servers for graphics and compute respectively, to hybrid devices like the future “Falcon Shores” family of chiplet complexes that Intel first talked about in February and talked a little bit more about at the recent ISC 2022 supercomputing conference.
At ISC 2022, Intel’s Jeff McVeigh, general manager of its Super Compute Group, not only raised the curtain a little more on Falcon Shores XPU hybrid chip packages but also provided a bit of a teaser extension to the roadmap for the discrete GPU line that starts with the Ponte Vecchio GPU.
Intel has had a rough go with discrete GPUs, and the tarnish is still not off the die with the Ponte Vecchio device, which crams over 100 billion transistors in 47 chiplets using a mix of Intel 7 processes and 5 nanometer and 7 nanometer processes from Taiwan Semiconductor Manufacturing Co to make those chiplets. The point of supercomputing is to push technologies, and this includes architecture, manufacturing, and packaging, and without question, the reconceived Aurora machine (in the wake of the killing off of the Knights family of chips in 2018 and causing a four-year delay in the delivery of the Aurora supercomputer) is pushing boundaries. One of them is energy consumption, with a 2 exaflops machine kissing 60 megawatts of power consumption. That is around 2X the power per unit of performance of the current “Frontier” supercomputer at Oak Ridge National Laboratory, which is comprised of 9,248 nodes, each with a hybrid AMD compute complex comprised of a single “Trento” Epyc 7003 CPU and four “Aldebaran” Instinct MI250X GPUs, which is expected to burn 29 megawatts at its full 2 exaflops peak.
Perhaps it can do better on the energy efficiency front with the follow-on to the Ponte Vecchio GPU accelerator while also pushing the performance envelope some. We will contemplate that in a minute. But let’s start with the updated Intel roadmap for HPC and AI engines:
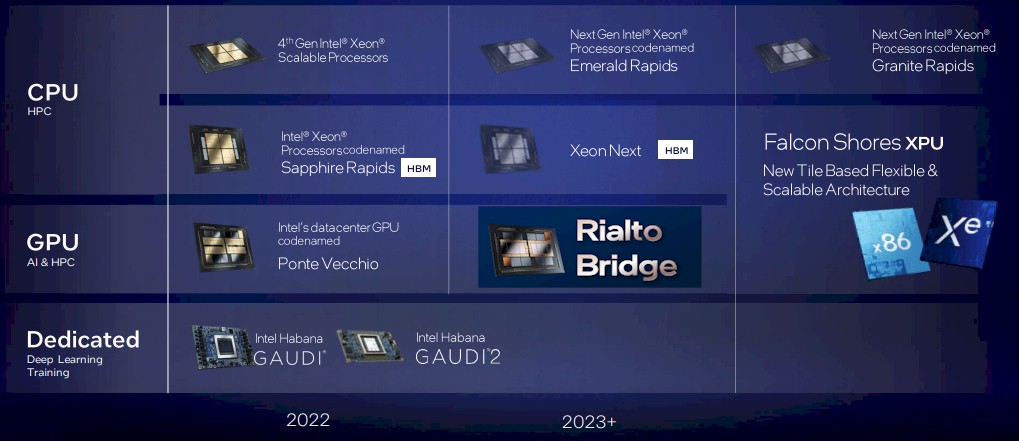
The CPU in the upper left corner is a “Sapphire Rapids” Xeon SP, although it does not say that, and as you can see, there are versions of the CPUs that use DDR main memory across the top row and then those that have HBM memory in the next row down. It is not clear why Intel is being cagey on this roadmap about “Xeon Next” with HBM coming in 2023, but this is almost certainly a socket-compatible “Emerald Rapids” CPU with DDR5 memory swapped out to HBM3 memory.
We see the “Granite Rapids” CPUs with DDR memory coming in 2024 as expected, but below that there is not a Granite Rapids chip with HBM3 support. Which is odd.
Rather, we see the Falcon Shores package, which promises to have “extreme bandwidth shared memory” across the compute chiplets on the package, with 5X the memory capacity and bandwidth “relative to current platforms in February 2022.”

All of those 5X metrics are not very precise or very satisfying either as statistics or descriptions. We will have to wait to see what it all means.
What is interesting, as we have discussed, is that Intel will offer Falcon Shores packages that support all X86 chiplets (very likely the P-core high performance cores that are used in the Xeon SP family of chips), all Xe chiplets, and a mix of X86 and Xe chiplets. Like this:

Intel warns that these diagrams are for illustrative purposes only, but given the chiplets that Intel has made thus far, a quad of compute chiplets fitting into a single package and sharing a single socket looks about right. The reason to put these on the same package it to get the CPU and GPU very close to each other, and sharing the same on package, high bandwidth memory, for workloads that are sensitive to that and that do not perform as well on discrete CPUs and discrete GPUs linked to each other with cache coherent memory across the interconnect.
We are intrigued about the sockets for all of the possible variations of discrete GPUs and the Falcon Shores hybrid compute engines, and whether they would be on a two generation socket cadence as has been the case with Xeon and Xeon SP processors for many years. ODMs and OEMs do not want to change a socket every generation, and three generations is too long to intercept memory and I/O technologies that are on a two year to three year cadence these days. McVeigh confirmed that a Falcon Shores socket would be compatible with its kicker, whenever that might come to market (probably 2026, but maybe sooner).
With the GPU-only version of Falcon Shores being available in an Open Compute Accelerator Module (OAM) form factor just like the impending Ponte Vecchio and future “Rialto Vecchio” kicker discrete GPU in 2023, we wondered about the possibility of a unified OAM socket for both CPUs and GPUs, which would please Facebook and Microsoft no end since they invented the OAM socket as an open alternative to Nvidia’s SXM socket.
“Good question,” McVeigh said with a smile. “As for will we have one socket across all of those, I am going to leave ourselves a little bit of flexibility on that because the GPU-only variation will typically be found in a PCI-Express or OAM module – that is sort of the unit of sale. As for using OAM for CPUs, that’s still open.”
Well, McVeigh didn’t say no. Which means it might be a good idea to have a single socket for those who want to plug CPUs and GPUs or hybrid compute engines mixing the two into a single chassis with maybe four or eight sockets and a unified memory architecture. If there is high bandwidth memory available to all classes of compute, then a unified socket makes sense along with unified memory, right?
That is certainly happening with the Rialto Bridge kicker to Ponte Vecchio. (We guess Intel didn’t want to say Rialto Vecchio in Italian and split the difference with half Italian and half English for this code name.) Here are the eight-way OAM 2.0 sockets for both discrete compute GPUs from Intel:

Which leads us across Rialto Bridge, the discrete GPU named after the oldest bridge spanning the Grand Canal in Venice.

With this kicker to Ponte Vecchio, which will start sampling sometime in 2023, Intel will boost the number of working Xe cores from 128 cores in Ponte Vecchio to 160 cores. At the same clock frequency, that would result in a 25 percent boost in GPU floating point performance, but we think with refinements in the chips and tweaks in the interconnects, Intel will try to do better than that. All that we know for sure is that Intel is promising more flops and more I/O bandwidth, and we presume more memory capacity and more memory bandwidth to balance it all out.