


The Association for Computing Machinery has just put out the finalists for the Gordon Bell Prize award that will be given out at the SC23 supercomputing conference in Denver, and as you might expect, some of the biggest iron assembled in the world are driving the advanced applications that have their eyes on the prize.
The ACM warns that the final system sizes and final results of the simulations and models run are not yet completed, but we have a look at one of them because the researchers in China’s National Supercomputing Center in Wuxi actually published a paper they will formally released in November ahead of the SC23 conference. That paper, Towards Exascale Computation for Turbomachinery Flows, was run on the “Oceanlite” supercomputing system, which we first wrote about way back in February 2021, that won a Gorden Bell prize in November 2021 for a quantum simulation across 41.9 million cores, and that we speculated the configuration of back in March 2022 when Alibaba Group, Tsinghua University, DAMO Academy, Zhejiang Lab, and Beijing Academy of Artificial Intelligence ran a pretrained machine learning model called BaGuaLu, across more than 37 million cores and 14.5 trillion parameters in the Oceanlite machine.
NASA tossed down a grand challenge nearly a decade ago to do a time-dependent simulation of a complete jet engine, with aerodynamic and heat transfer simulated, and the Wuxi team, with the help of engineering researchers at a number of universities in China, the United States, and the United Kingdom have picked up the gauntlet. What we found interesting about the paper is that it confirmed many of our speculations about the Oceanlite machine.
The system, write the paper’s authors, had over 100,000 of the custom SW26010-Pro processors designed by China’s National Research Center of Parallel Computer Engineering and Technology (known as NRCPC) for the Oceanlite system. The SW26010-Pro processor is etched using 14 nanometer processes from China’s national foundry, Semiconductor Manufacturing International Corp (SMIC), and looks like this:
The Sunway chip family is “inspired” by the 64-bit DEC Alpha 21164 processor, which is still one of the best CPUs ever made; the 16-core SW-1 chip debuted in China way back in 2006.
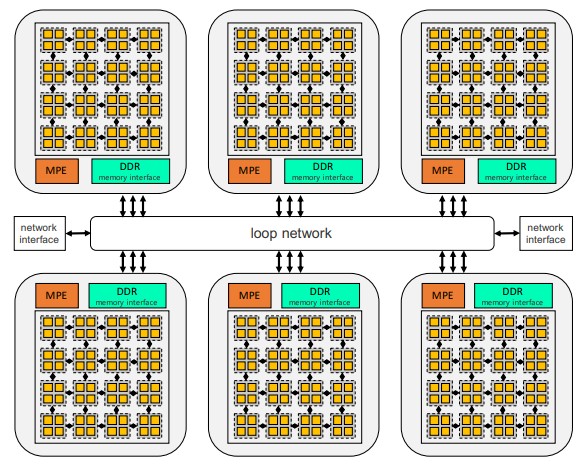
There are six blocks of core groups in the processor, with each core group having one fatter management processing element (MPE) for managing Linux threads and an eight by eight grid of cores comprising a compute processing element (CPE) with 256 KB of L2 cache. Each CPE has four logic blocks, which can support FP64 and FP32 math on one pair and FP16 and BF16 on another pair. Each of the core groups in the SW26010-Pro has a DDR4 memory controller and 16 GB of memory with 51.4 GB/sec of memory bandwidth, so the full device has 96 GB of main memory and 307.2 GB/sec of bandwidth. The six CPEs are linked by a ring interconnect and have two network interfaces that link them to the outside world using a proprietary interconnect, which we ave always thought was heavily inspired by the InfiniBand technology used in the original TaihuLight system. The SW26010-Pro chip is rated at 14.03 petaflops at either FP64 or FP32 precision and 55.3 petaflops at BF16 or FP16 precision.
The largest configuration of Oceanlite that we have heard of had 107,520 nodes (with one SW26010-Pro comprising a node) for a total of 41.93 million cores across 105 cabinets, and the paper just announced confirmed that the machine had a theoretical peak performance of 1.5 exaflops, which matches the performance we estimated (1.51 exaflops) and almost perfectly matches the clock speed (2.2 GHz) we estimated almost two years ago. As it turns out, the MPE cores run at 2.1 GHz and the CPE cores run at 2.25 GHz.
We still think that China may have built a bigger Oceanlite machine than this, or certainly could. At 120 cabinets, the machine would scale to 1.72 exaflops peak at FP64 percision, which is very slightly bigger than the 1.68 exaflops “Frontier” supercomputer at Oak Ridge National Laboratory, and at 160 cabinets, Oceanlite would have just under 2.3 exaflops peak at FP64. As noted in the comments below, the Wuxi team will be presenting the Oceanlite machine during a session at SC23 in November, and that session says the machine has 5 exaflops of mixed precision performance across 40 million cores. That implies a 2.5 exaflops peak performance at FP64 and FP32 precision and 5 exaflops at FP16 and FP8 precision. But that might now be the peak. If you assume the old rule of thumb that a machine tops out at 200 cabinets, then Oceanlite could be a machine that does a peak 3 exaflops at higher precision FP64 and FP32 and 6 exaflops peak at lower precision FP16 and FP8. That beast would weigh in at 202,933 nodes and 79.34 million cores.
Those latter numbers, if they turn out to be valid, are important if China wants to be a spoiler and try to put a machine in the field that bests the impending “El Capitan” machine at Lawrence Livermore National Laboratory, which is promised to have in excess of 2 exaflops of FP64 oomph.
For the latest Gordon Bell prize entry, the jet engine simulation was run on Oceanlite with approximately 58,333 nodes, which represents over 350,000 MPE cores and over 22.4 million CPE cores. That is a little bit more than half of the largest configuration of Oceanlite that has been reported in a paper. It is interesting that the sustained performance of the application was only 115.8 petaflops.
Another Gordon Bell finalist for 2023 is a team at the University of Michigan and the Indian Institute of Science who worked with the team at Oak Ridge on the Frontier system to use a hybrid machine learning and HPC simulation approach to combine density function theory and the quantum many body problem to do quantum particle simulations. With this work, the resulting software was able to scale across 60 percent of the Frontier system. Don’t assume that means this quantum simulation ran at a sustained 1 exaflops; it will probably be more like 650 petaflops, and perhaps a lot less depending on the computational and network efficiency of the Frontier box when it comes to this particular application.
The third finalist for the Gordon Bell prize consists of researchers at Penn State and the University of Illinois, who worked with teams at Argonne National Laboratory and Oak Ridge to simulate a nuclear reactor. (Way back in the day, we got our start in writing at the Penn State NukeE department, so kudos Lions.) This simulation, which included radiation transport with heat and fluid simulation inside of the reactor, and the ACM report says it ran on 8,192 nodes in the Frontier system, which is officially sized at 9,402 nodes and which have one “Trento” custom Epyc CPU per node and four “Aldebaran” Instinct MI250X GPU accelerators per node for a total of 37,608 GPUs.
Finalist number four for the 2023 Gordon Bell away is comprised of teams from KTH Royal Institute of Technology, Friedrich-Alexander-Universitat, Max Planck Computing and Data Facility, and Technische Universität Ilmenau who scale Neko, a high-fidelity spectral element code, across 16,384 GPUs on the “Lumi” supercomputer in Finland and the “Leonardo” supercomputer in Italy.
King Abdullah University of Science and Technology and Cerebras Systems teamed up to run seismic processing simulations for oil reservoirs on a cluster of 48 CS-2 wafer-scale systems from Cerebras that have a total of 35.8 million cores. This one is neat because it is bending an AI matrix math machine to do HPC work – something we have reported on frequently.
Number six of the 2023 finalists is a team from Harvard University, who used the “Perlmutter” hybrid CPU-GPU system at Lawerence Berkeley National Laboratory to simulate the atomic structure of an HIV virus capsid up to 44 million atoms and several nanoseconds of simulation. They were able to push strong scaling up to 100 million atoms.
This year, the ACM is also presenting its first Gordon Bell Prize for Climate modeling, and as we said we hoped would happen when in April of this year we covered the SCREAM variant of the Energy Exascale Earth System Model, also known as E3SM, developed and extended by Sandia National Laboratories, this extended resolution weather model is up for a prize. SCREAM is interesting is that is started from scratch for parts of the code, using C++ and the Kokkos library to parcel code out to CPUs and GPUs in systems, and in this case it was run on the Frontier machine at Oak Ridge, simulating 1.26 years per day for a practical cloud-resolving simulation.
The Sunway Oceanlite system is a finalist here, too, but this one simulated the effects of the underwater volcanic eruption off of Tonga in late 2021 and early 2022, including shock waves, earthquakes, tsunamis, and water and ash dispersal. The combination of simulations and models was able to simulate 400 billon particles and ran across 39 million cores in the Oceanlite system with 80 percent computational efficiency. (We want to see the paper on this one.)
The third Gordon Bell climate modeling finalist is a team of researchers in Japan who got their hands on 11,580 nodes in the “Fugaku” supercomputer at RIKEN lab – about 7 percent of the total nodes in the machine – and did a 1,000 ensemble, 500-meter resolution weather model with 30 second refresh for the 2021 Tokyo Olympics. This was a real use case, and over 75,248 weather forecasts distributed over a 30 day period and each 30 minute forecast was done in under three minutes.
So, basically, for the most part, this comes down to Froniter versus Oceanlite. Quelle surprise. . . .