


Video has taken over the Internet, with almost 80 percent or so of the traffic being video. Datacenters over the past several years have increasingly relied on GPU accelerators to transcode the massive amount of video traffic running over networks, offloading much of the work from CPUs in hopes of lower latency, costs, and power consumed.
And it is only getting more challenging as the nature of the video is transforming. The prevailing model in the past has been a one-to-many on-demand environment driven by such companies as Netflix or events like the live broadcast of sporting competitions, where the video feed starts in a single place runs through cloud datacenters, content delivery networks (CDNs), and edge servers before landing in enterprises offices or the homes of consumers.
It always comes with a little bit of a delay, given the amount of processing and computing that needs to be done in the datacenter to ensure good quality or because broadcasters are looking for a few seconds of delay for editing purposes. Such delays aren’t a huge problem for such scenarios.
But video is becoming increasingly interactive, and it’s not just consumer applications like the Twitch video game live streaming service but, in large part because of the COVID-19 pandemic, enterprise tools like video conferencing for the enlarged work-from-home crowd. In December 2019, Zoom had 10 million daily participants. By June 2020, as the pandemic enveloped the world, that number was 300 million. Other services, like Teams from Microsoft and Webex from Cisco Systems, saw similar growth.
This interactive video environment put even greater pressure on datacenter resources to reduce latency and get rid of delays. In 2021, 70 percent of the video market was interactive video.
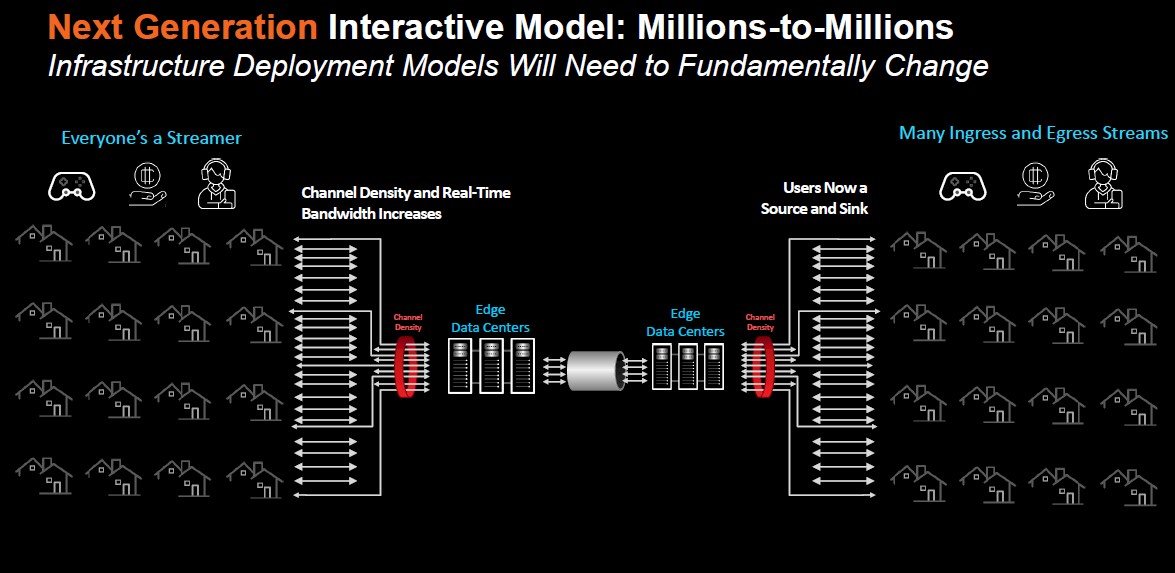
“It’s starting to put a strain on the infrastructure when it comes to the networking pipe and also in terms of processing on the server side,” Vincent Fung, senior product marketing manager at AMD, tells The Next Platform. “The previous traditional [infrastructure] model starts to not make much economical sense. It becomes a harder model to keep up to address these use cases.”
Such use cases were what AMD CEO Lisa Su and other executives had in mind when the company bought programmable chip maker Xilinx early last year for $35 billion. Through its Zen microarchitecture, Epyc server CPUs, and Radeon GPUs – and helped by Intel’s various stumbles – AMD over the past several years has made a remarkable return to the datacenter, collecting more than 25 percent of the datacenter CPU market while seeing growth in it the GPU space.
Pulling Xilinx into the fold gave AMD an even larger presence in the datacenter, not only through field-programmable gate arrays (FPGAs) but also AI engines, adaptive systems-on-a-chip (SoCs), and software for such fields as networking and the edge. Xilinx also is the foundation of the company’s Adaptive and Embedded Computing Group, bringing with it a line of dedicated video encoding cards.
That included the Alveo U30 media accelerator that Xilinx introduced in 2020 and aimed at live streaming workloads. It’s used for live video transcoding via the cloud through Amazon Web Services EC2 VT1 instances or on premises in preconfigured appliances. Fung says AMD has “been anticipating the growth of interactive media, so we have the first generation, which is the U30.” Now the company is sampling the card’s successor, the Alveo MA35D, a datacenter media accelerator and dedicated video encoding card that offers significant improvements over the U30.

The shift to more live video streaming has “drastically increased in terms of traffic,” Fung says. “There’s a lot more processing that needs to be done from a video perspective when we look at these interactive use cases when one-to-many becomes many-to-many. You eliminate the compromises you have to make to address these very demanding interactive use cases. You have a lot of people using it, you need high performance because you have a lot of people using it. You want to minimize bandwidth costs because the uptake is large. Power consumption all becomes part of the expense.”
Like the Alveo U30, the MA35D is made for real-time interactive video encoding but is the first from a post-Xilinx AMD. It includes two 5nm ASIC video processing units (VPUs) that offers four times the number of simultaneous video streams – up to 32 1080p60 channels – and includes support for 8K and AV1 resolution encoding, the latest standard which Fung says is more compute-intensive.
It’s being used by a lot of big names, including Meta, Microsoft, and Cisco, as well as such services at Google’s YouTube, Netflix, and Roku, according to Sean Gardner, head of video strategy and development at AMD.
“It is out there, but it has been limited,” Gardner tells The Next Platform. “Every new standard, its theoretical goal is to achieve 50 percent compression efficiency over the previous standard. If we locked to a visual quality, how many bits does it take me to achieve to that quality? Each new standard strives to achieve that quality using 50 percent less bandwidth, but each step it tends to spend on the encode side because that’s where the differentiation is. Make the decode cheap because that’s the high volume – or used to be, because that’s starting to change – but it incurs a penalty of around 5 to 7x each new codec implementation.”
Latency is key, he says.
“Netflix doesn’t have a latency [issue],” Gardner says. “They can take 10 hours – and they do – to process one hour of video and they can use it in off-hours when they excess capacity. But live needs to happen in 16 milliseconds or you’re behind real time, at 60 frames a second. If you think about this scenario, where you could have Zoom or Teams or Webex, it could have billions of people using it concurrently. Or someone like Twitch, which has hundreds of thousands of ingest streams. The other aspect is, with live [streaming], you can’t use a caching CDN-like architecture because you can’t afford the latency. This is why acceleration is needed.”
Along with four times the channel density, testing shows that the MA35D, which will go into production in the third quarter and carry an MSRP of $1,595, has twice two times lower cost-per-channel, 1.8 times the compression, and four times lower latency. It also scales, from 32 streams with the card to 256 streams in a server format holding eight cards. It then scales to the rack or datacenter level. It offers up to a 52 percent reduction in the bitrate to save on bandwidth.
Beyond the VPUs, the accelerator also includes encoder and decoders, adaptive bitrate scalers, a compositor engine for immersive computing, and a visual quality engine and “Look-Ahead” to analyze motion and content as well as efficient compression. An AI processor to optimize the quality of the visuals.
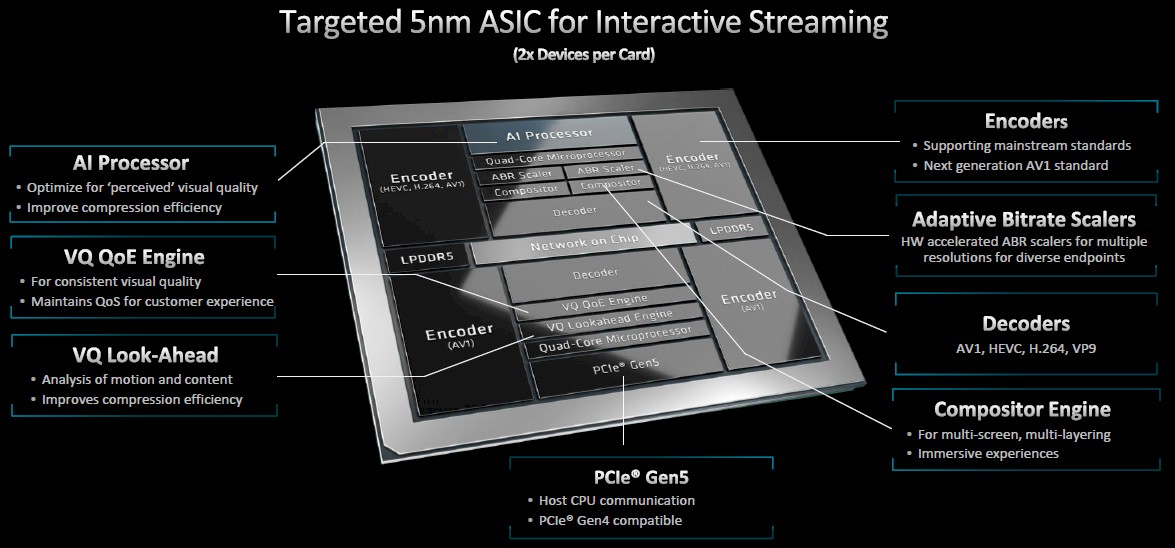
Host CPU communication comes via the PCI-Express 5.0 bus, which is backward compatible to Gen4.
“The accelerator is the whole video pipeline,” Fung says. “The goal here is to not have to go out and put any of those tasks outside of the chip so we can maintain a consistent performance level. What we can deliver won’t be affected by near-live use cases. Everything is in here, hardened. We have an AI block here, typical encoding, decoding is there, but we also have the base optimization.”
In the video world, AMD is looking to break away from the GPU strategies of Nvidia, with its T4 Tensor Core primarily aimed at AI inference and L4 for graphics, and Intel and its GPU Flex Series for datacenter media streaming. When the volume of streaming video began to rise, the only real game in town was Nvidia’s GPUs, Gardner says.
Now everyone is seeing that the two key applications for these sorts of accelerators are video and AI. Video is huge now, but AI is on the rise. Strategies are being designed for these two use cases.
“Things have started to open up,” he says. “Intel and Nvidia continue to drive at it from the GPU – or Intel is attempting to – with big AI and a little video. Intel is coming at it with a sort of medium video, medium AI. We’re coming at it from 99 percent video and we have added some small AI, but we’re not trying to get into smart cities and surveillance. The AI is specially targeted at in-line, pixel-level processing.”