

The best kinds of research are those that test new ideas and that also lead to practical innovations in real products. It takes a keen eye to differentiate science projects, which can be fun but which can also lead nowhere, from useful stuff.
At Nvidia, the job of steering research without veering off into science projects is done by Bill Dally, the legendary expert on networking who is an adjunct professor of computer science and electrical engineering at Stanford University as well as chief scientist and senior vice president of research at the GPU, networking, and soon CPU chip designer.
At every GPU Technical Conference, Dally gives an update on some of the neat research that Nvidia is engaged in, and did so again last week at the 2023 Spring GTC. His presentation this time around, which you can see here, talked about some things we don’t care too much about like autonomous vehicles or 3D image generation or even vision transformers. These are endpoint use cases, and we live in the datacenter and only sometimes wander out to the edge. But when Dally talked about machine learning inference hardware that Nvidia Research was playing around with, that got our attention.
One interesting thing that Dally talked about was how Nvidia Research, which has over 300 PhDs thinking big thoughts, is organized. Dally explained that there is a “supply side,” which creates technologies that go into GPUs to make them better, and a “demand side” that is charged with coming up with a wider and wider array of applications to compel companies to buy more and more GPU accelerators. The supply side includes circuit and chip design, chip process and manufacturing, chip architecture, networking for interconnects between the GPUs and other things, programming environments to leverage the GPUs, and storage systems to keep them fed. On the demand side, there are AI labs in Toronto, Tel Aviv, and Taipei as well as teams that work on graphics and autonomous vehicles scattered around Nvidia facilities.
Every once in a while, there is a “moonshot” group formed at Nvidia that is pulled from both sides of research to help work with the day-to-day engineers on a project, such as the technologies that all came together to make the “Volta” GPU launched in May 2017 or the ray tracing RT cores in the “Turing” GPUs launched in gaming GPUs in the summer of 2018 and delivered in the T4 accelerator in September of that year.
And every now and again something neat that Nvidia Research is working on gets ripped out of the lab and has a product name and number slapped on it and it is sent to market because the Nvidia product people can’t wait another second longer. For instance, the cuDNN distributed neural network was created by Nvidia Research after reading the ground-breaking paper on unsupervised learning published by Google in December 2011 that allowed a cluster of 1,000 machines with 16,000 cores to be able to identify cats on the Internet. Using what would become cuDNN, Nvidia was able to replicate and accelerate that job on a mere 48 GPUs of the time. This rapid productization of research also happened with NVSwitch, the NUMA-like memory interconnect that came out a year after the Volta GPUs in March 2018 to link sixteen of them into one giant virtual GPU.
We strongly suspect that the same thing is going to happen with two technologies, called VS-Quant and Octav, that Nvidia Research has put into a test chip for AI inference and that Dally explained at length.
Before diving into these, Dally gave some perspectives on the inference performance improvements between the “Kepler” and “Hopper” GPU generations that span a decade and how the interplay of mixed precision, ever more complex instructions, and chip process had driven up inference performance by a factor of more than 1,000X over that time:

Only about 2.5X of that 1,000X of performance improvement came from process shrinks and clock speed hikes, and the remaining 400X improvement came from complex instructions, architecture, and shrinking precision. Precision was 4X of that, moving from FP32 to FP8, so that means 100X of that performance was from architecture boffinry.
After all of that work, Nvidia has been able to get the Hopper to have an efficiency of about 10 teraops per watt. But the test chip using VS-Quant and Octav technologies does 10X better than that, at close to 100 teraops per watt.
“One thing that we are constantly doing is looking at how can we do better than this,” Dally explained. “And one way is to try to continue to get gains from number representation. But if we just go from INT8 to INT4 or even from FP8 to FP4, what we find is we are actually giving something up – our accuracy will drop precipitously. So we need to be a little bit more clever about how to do our quantization – how we quantize from a higher precision number representation to a lower precision number representation.”
That is what VS-Quant – short for Per-Vector Scaled Quantization – is all about:
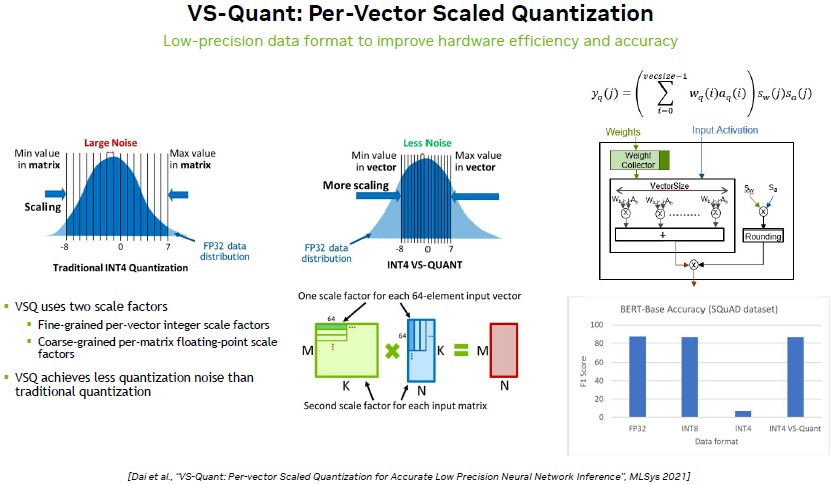
What VS-Quant does is a much tighter quantization as raw FP32 data is quantized – pixelated to use a visual metaphor – down to an INT4 or FP4 format. In the chart above, FP32 data is transposed down to INT4 formats, and instead of taking the full FP32 data distribution, the high and lows of the distribution are cut off and only the center part is kept. And as you can see from the two bell curves, the one using VS-Quant has a much lower noise-to-signal ratio, which means when you use it, the accuracy of results is akin to what you get with INT8 and native FP32 formats. (This is harder than it sounds.) There is one scale factor for each 64-element input vector and a second scale factor for each input matrix, and the VS-Quant circuits multiply them together and quantize down to INT4 with the VS-Quant magic and as you can see in the embedded bar chart in the lower right of the chart above, real INT4 “falls off a cliff” as Dally put it, and the doctored INT4 provides the same accuracy on the BERT-Base model as FP32 and INT8.
So there is another 2X right there, or 20 teraops per watt. Now you need another 5X on top of that, and this comes through a feature called Optimally Clipped Tensors and Vectors, or Octav for short:
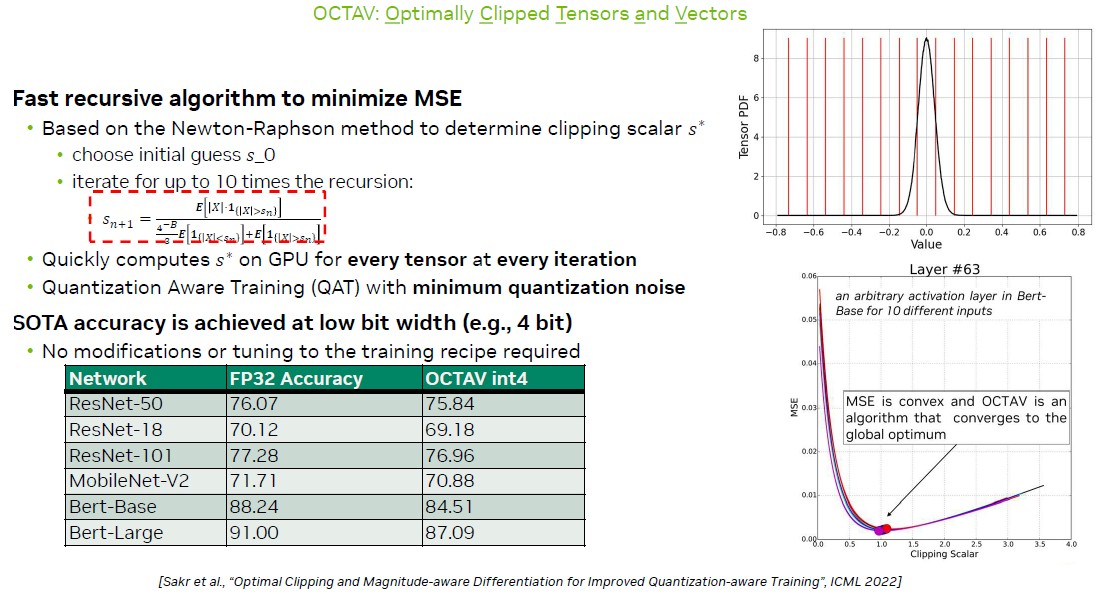
With Octav, you don’t tighten the range for the vector and then do funky math in circuits to quantize it, but clip off the high and low ends of the vector and then quantize it. With just Octav running on INT4 data, as you can see in the chart above, on BERT models the accuracy of INT4 for various image processing neural networks is virtually the same.
Dally explains.
“We get clipping noise because we have inaccurately represented these outlying weights, but there weren’t very many of those and we trade that off against quantization noise. Our quantization noise is much smaller now. And it turns out, you can pose this as an optimization problem, where if the goal is to minimize the mean squared error in representing your weights, what you want to do is say what value should I use as the clipping scaler. Say my weights are distributed out to 3.5 – here I could choose 3.5 as my clipping scale, in which case there’s no clipping and lots of quantization noise. And then as I moved my clipping scaler down – not throwing away some of these big weights but rounding them down – the clipping scaler trading off basically making the quantization was less with the clipping noise more to the point where the two are about equal when this is my minimum error of representation. And then if I try to clip more bass, my clipping noise goes up very rapidly as I’m starting to clip the large number of weights. And my quantization noise isn’t getting much better.”
Calculating precisely where to clip the vector is computationally intense, but there is an iterative Newton Raphson method that estimates mean squared error without too much overhead. Octav circuits do this iterative calculation to come up with the optimal clipping scalar. The performance numbers shown in the chart above, which is an 8X factor of throughout performance at essentially the same accuracy, are for the Octav clipping scalar trick only.
To test these ideas out, Dally and his team put both VS-Quant and Octav on the same test chip called Magnetic BERT, which looks like this conceptually:
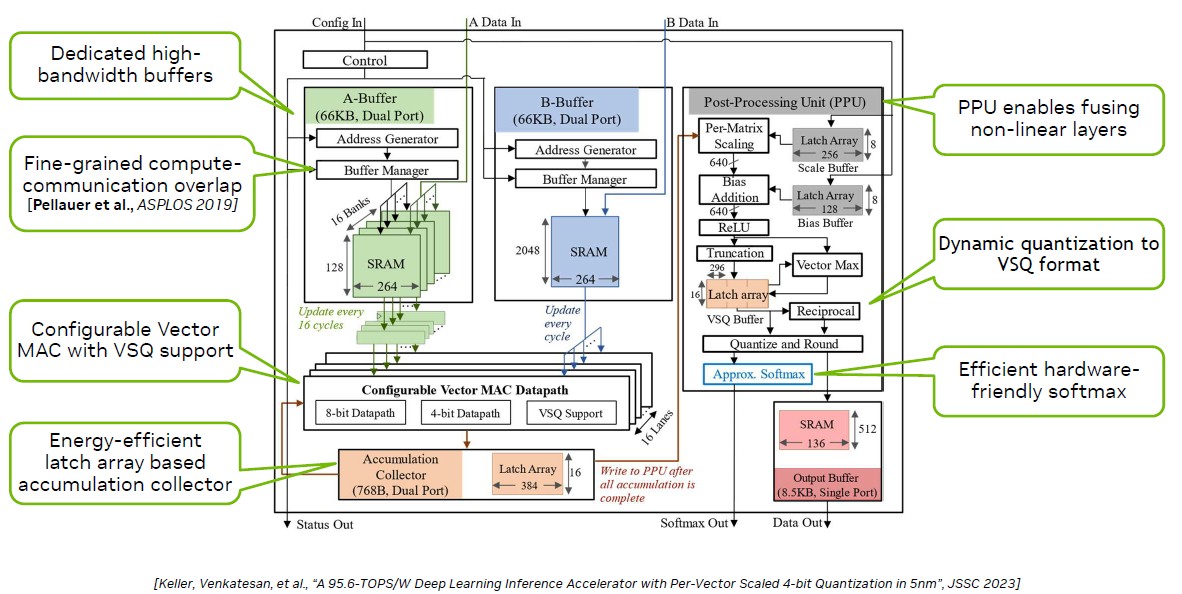
The Magnetic BERT chip was implemented in 5 nanometer processes from Taiwan Semiconductor Manufacturing Corp in a chip with a mere 0.153 millimeters squared of area and was capable of performing 1,024 4-bit multiply-accumulates (MACs) per cycle at a frequency that ranged from 152 MHz to 1.76 GHz. With 50 percent dense 4-bit input matrices, this Magnetic BERT chippy could drive 95.6 teraops per watt.
I know what you are thinking. It should have been 16X better than Hopper’s 10 teraops per watt with both VS-Quant and Octav running at the same time, but it was only just shy of 10X. Nope, I don’t know why either, but maybe there is something that still needs to be worked out as VS-Quant and Octav work together on the clipping and quantizing.

AMD’s Instinct GPU Business Is Coiled To Spring
Timing is a funny thing. The summer of 2006 when AMD bought GPU maker ATI Technologies for $5.6 billion and took on both Intel in CPUs and Nvidia in GPUs was the same summer when researchers first started figuring out how to offload single-precision floating point math operations from CPUs …
Nvidia Gets Certifiable About Systems
If the emergence of Nvidia in datacenter compute shows anything, it is the value of controlling the software stack as you come to dominate the compute – and the revenue and profits – in the hardware stack. When it comes to AI, the combination of open source frameworks from the …

Economics And The Inevitability Of The DPU
The advent of the Data Processing Unit or the I/O Processing Unit, or whatever you want to call it, was driven as much by economics as it was by architectural necessity. The fact that chips are pressing up against reticle limits and CPU processing for network and storage functions is …
Interesting stuff, and hard to argue with 300 PhD’s, simultaneously! This looks like dynamically adaptive quantization, lossy functional compression (keeps its “effect” through biased matrix-vector mult. & activation function); it may have broader utility in adaptive ADCs (FP32 being a pseudo analog input, and INT4 the digital out). Our sensory nerves essentially do something “similar” (I think), converting analog inputs from the environment into spike trains of varying frequencies and relative amplitudes. Sameer B. Shah (former colleague, now at UCSD) did some nifty visualizations of the underlying cargo transport, inside axons, in real-time. Here though, the INT4 might efficiently (computationally) encode spike-train characteristics, producing artificial neurons that have some correspondence with biological ones (?). Anyhow, the improved performance and efficiency is quite welcome!
Are you sure you are not a Connection Machine, Hu?
HA!
Very interesting.
That is so funny. I was just thinking about the hypercube connectionist idea a week ago. I do not think many would get that.
Thanks (I think)! Hopefully this won’t get my hypercube to overheat, while exercising the ol’ connectome, in celebration of the 10th anniversaries of the U.S. BRAIN Initiative and the EU Human Brain Project — esp. as they might help us figure out why we’re so gullible to LLMs (and other sophistry) as a species…
Also notice that the PPU is more important. Why only bytes and nibbles on the front end? Who is using the term latch array?