


If you are fairly new to the IT racket, you might be under the impression that the waves of integration and disaggregation in compute, networking, and storage that swept over the datacenter in recent decades were all new, that somehow the issues of complexity and cost did not plague systems of the past.
This is, of course, utterly ridiculous. The pendulum swings back and forth between integration and disaggregation all through the history of systems. When the economic allows for intense integration, either through chip process or packaging advancements, or both, then this is what happens because shortening the wires between blocks of circuits, whether they are compute or memory or networking, radically increases performance. But it also increases costs, and at some point a die with all kinds of compute, memory, and networking gets so expensive that a disaggregated approach becomes necessary and then the chips are all snapped into pieces, like breaking a graham cracker, and glued together with interconnects of some sort or another.
In some cases, the disaggregation is forced upon the system designer because there is not other way. A good case in point is the IBM System/360 mainframe, launched in April 1964 and quite literally creating the modern era in computing that we all benefit from. As we pointed out back in May 2017, when we pondered the increasingly large bites that Nvidia was taking out of the datacenter budget and which was long before Nvidia thought about buying Mellanox Technologies for its networking and SmartNICs, the central processing unit, or CPU, gets its name because there were other processing units, and the main frame was called that precisely because there were other frames, loaded up with all kinds of compute and acceleration in a system. The System/360 and follow-on System/370 mainframes were so big and important, and its customers on the bleeding edge of technology at the time, that money was not really an issue. The whole mainframe complex, complete with disk controllers and tape controllers and peripheral controllers, was incredibly expensive, but the value was so much more than the cost that the Global 2000 and then the Global 5000 quickly automated back office functions like never before. Think about it: They could do online transaction processing, in real time. That was the future when lots of stuff in the corporate world was still a bunch of punch cards walloping each other like a bunch of dealers at a blackjack table in Las Vegas.
With some system architectures, the galaxy of intelligent coprocessors wrapped around the central processors allows for a fairly modest CPU to appear to do a lot more work than it might otherwise be able to do. Two cases in point. The PDP-11 from Digital Equipment – that’s short for Programmed Data Processor – hails from the middle to late 1970s, and it had a very sophisticated bus that allowed everything – memory, peripherals, and smart terminals as opposed to IBM’s green-screen dumb ones for the mainframe – to hang off that bus. IBM took intelligent controllers a step further with the System/38 minicomputer in the late 1970s, and mainly because it was embedding a relational database management system as the file system in the machine, and pushed disaggregated, asymmetric computing to an extreme extent with the AS/400 minicomputers launched in 1988. In that machine, microcode that would have otherwise been run on the CPU was pushed off to what IBM called Intelligent I/O Processors, or IOPs, and they handled everything from terminals to printers to disk and tape data management and even some preprocessing for the database to boost response times.
When we sat down earlier this year to have a very long chat with Pradeep Sindhu, co-founder and chief executive officer at Fungible, an upstart data processing unit, or DPU, maker who also happened to cut his teeth at Xerox PARC and Sun Microsystems and then went on to be a co-founder and chief technology officer at Juniper Networks, we reminded him that we were well aware of the push and pull between integration and disaggregation throughout datacenter history. And having a bit of a flashback, we told Sindhu that we saw the rise of RISC/Unix gear in the 1990s as representing a wave of consolidation of circuitry that culminated in the relatively homogeneous X86 server in the datacenter, where the CPU complex has all of its memory and I/O controllers integrated and the CPU cores still handle a lot of the processing related to them as expected by the operating systems of the time.
So let’s get this straight. If Dennard Scaling didn’t peter out a decade ago and if Moore’s Law was not running out of gas in the next five to seven years or so, we would not be talking about DPUs at all. And if waferscale integration turns out to be an economical idea as Cerebras Systems thinks it might be – and we are not sure that it will pan out in a world where chiplets might be integrated at far lower cost even with higher latency because communications has to go off die – we might not be talking about DPUs for long. Maybe a decade or so.
But, here in 2020, the SmartNIC is morphing into the DPU, and everyone wants to get a piece of the action. And Nvidia, having just bought Mellanox for $6.9 billion and at the beginning of acquiring Arm Holdings for a stunning $40 billion, is probably going to have a bigger DPU business than it will have a CPU business for a while. We will see how this plays out when and if the Arm Holdings acquisition gets through the antitrust regulatory bodies in the United States, Europe, and China, but no matter what, Nvidia can have a very respectable DPU business and take away from money from Intel’s datacenter server compute monopoly.
A side note: Yes, Intel has a monopoly, and an unregulated one at that, with well north of 95 percent of datacenter servers and probably around 85 percent of revenues being on Xeon platforms. There is no law against monopolies, but they do require regulation if there is not going to be competition to keep them in check.
In a funny way, the re-emergence of AMD and the rise of the Arm server chip collective has helped Intel maintain its monopoly because it can argue it doesn’t own the whole server CPU pie. There are laws against using monopoly power to tie other product sales to the item that has a monopoly and there are laws against using that monopoly to keep competitors out. But we don’t think the antitrust regulators of the world have a stomach to regulate or bust up Intel – as they certainly wanted to do with IBM in 1952 relating to punch card machinery and again in 1969 with mainframes and minicomputers – and almost did. Were it not for IBM signing a consent decree governing its behavior in 1956, which was subsequently amended to cover mainframes and minicomputers, heaven only knows what the computer business might look like today. IBM was not released from that consent decree until 2000 for the AS/400 line and until 2001 for the mainframe line. So no one likes to be called a monopoly – including Microsoft in the 1990s or Google now – because they all know this cautionary tale. Nvidia might be building a complete systems hardware and software stack, but it is a long way from being a monopoly.
Which brings us in our roundabout way to the announcement of Nvidia’s DPU roadmap at the GTC 2020 fall conference, which is going on this week. No, you can’t really call it the GPU Technology Conference anymore, can you, Nvidia? You have DPUs and switch and adapter ASICs and if the Arm Holdings deal goes through, CPUs. Maybe it should be called the Green Eye Technology Conference? Anyway. . . .
I’ll Take My DPU With One Or Two Bumps In The Wire
If the network is indeed the computer, as Sun Microsystems posited a long time ago, and if we are moving into an era of disaggregation of and composability of functions expressed in all kinds of chiplets and software, then it follows that the CPU should become a sort of compute accelerator for the network. No one is talking about DPUs that way, but we think they will.
The block diagrams certainly are looking that way, as the one that Manuvir Das, the head of enterprise computing at Nvidia and formerly a researcher at Microsoft who helped build the Azure cloud and its programming model before moving to Dell for a few years, showed to press and analysts ahead of the GTC 2020 fall event. Take a look:
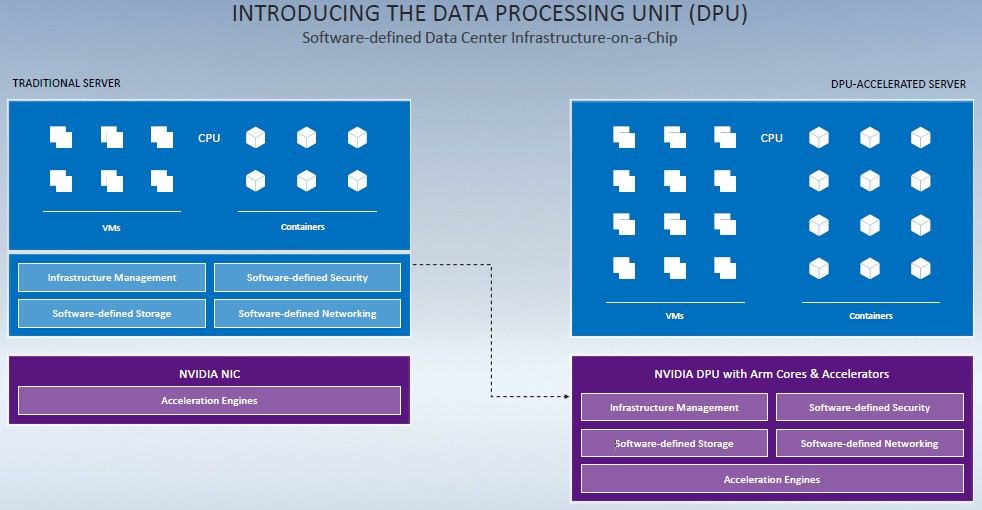
It’s a little bold for Nvidia to be saying it is introducing the concept of the DPU, with upstarts Fungible and Pensando laying claim to this. But, to be fair, Mellanox did buy EZchip, which owned the assets of multicore chip startup Tilera, for a whopping $811 million in September 2015 and created the “BlueField” line of Arm processors, aimed at accelerating network and storage. This was about the time that Amazon Web Services was starting down its path to abstract virtual compute, virtual storage, and virtual networking onto intelligent network interfaces, which are generally now called SmartNICs but which will soon be called DPUs. The thing about these SmartNIC and DPU motors is that they are computers in their own right and can be used as such, not just as offload engines for CPUs inside of servers.
As part of the GTC 2020 fall conference, Nvidia is rolling out the second generation of its DPUs, the BlueField-2, and is also providing a roadmap that goes out for the next several years that shows it is deadly serious about this DPU market.
After EZchip bought Tilera in July 2014 for $130 million, the company kept the SkyMesh 2D mesh interconnect that Tiera cooked up and that scaled to over 200 cores and replaced the Tilera cores with Arm Cortex-A53 cores. When Mellanox bought EZchip, it opted to go with the beefier Cortx-A72 cores to provide more oomph. The BlueField-1 chips had eight or sixteen cores and supported PCI-Express 3.0 or 4.0 links. Each of the cores has a pair of Arm NEON 128-bit vector engines, which are useful for all kinds of encryption and decryption work. The cores are paired up into a tile that shares a 1 MB L2 cache and a 6 MB segment of L3 cache. The BlueField SmartNIC was a pairing of this custom Arm processor with a ConnectX-4 ASIC, which had two ports running at either 25 Gb/sec or 100 Gb/sec and supporting either the Ethernet or InfiniBand protocols.
With the BlueField-2, Nvidia is sticking with eight Cortex-A72 cores and marrying this to a more modern ConnectX-6 Dx network interface ASIC. Like this:

Das says that the BlueField-2 is sampling now to early adopters for testing and will be generally available at the end of 2020. There are a number of differences between the BlueField-1 and the BlueField-2. There are actually fewer cores in the BlueField-2 than in the largest BlueField-1, which speaks to the workloads that Nvidia is envisioning running on these devices but also to the substantial amount of computing power that the ConnectX-6 Dx ASIC also has on it. The BlueField-2 has two out-of-band management ports, so it can be managed like any other lights out server, and comes with two 100 Gb/sec ports that support either InfiniBand or Ethernet. The BlueField-2 adapter only plugs into PCI-Express 4.0 slots.
Some of the modesty with regard to the Arm compute on the BlueField-2 ASIC also has to do with Nvidia’s desire to use GPU acceleration to do a lot of the heavy lifting on its DPU line. So instead of one bump in the wire, as they say in the accelerated networking world, there are going to be two bumps with the future BlueField-2X adapter, which is shown here:

In this case, an unspecified, PCI-Express version of the new “Ampere” GPU accelerator is being paired with the BlueField-2 GPU. It is very likely the new A40 accelerator that Nvidia is also rolling out this week. (We will cover that separately.)
There are two ports for connectivity on the BlueField-2X DPU that use what we presume is the ConnectX-6 Dx network interface chip; we also presume they are 100 Gb/sec ports supporting either InfiniBand or Ethernet protocols. There appears to be only one out-of-band management port on this device. There appears to be a hefty amount of HBM2 memory on the Ampere GPU accelerator, and the two chips link to each other using PCI-Express 4.0 lanes. We presume that the BlueField-2 chip does all of the talking out of the adapter card and that the Ampere GPU has to work through the BlueField-2 to reach the outside world. In other words, this is not a GPU that has a CPU accelerator. It would be interesting if there was coherence across the CPU and the GPU on this device, which Nvidia clearly knows how to do based on its work with IBM on the Power9 chip, and we think this is highly likely in future DPUs even if it does not come to pass with this generation.
The BlueField-2X DPU adapter card will be available “a few months after” the BlueField-2 DPU, according to Das, which probably means around March or April 2021 when we might expect the GTC 2021 spring conference to come around on the guitar. The GPU accelerator will be used to provide machine learning accelerator for various workloads, such as anomaly detection, traffic analysis, security, and analytics of data coming across the wire and into the server for further processing.
The saying in the IT sector, particularly among hyperscalers, cloud builders, large enterprises and sometimes HPC centers, is that they invest in roadmaps, not in any specific technology. And so, with existing SmartNIC competitors and emerging DPU competitors, Nvidia has rolled out the skeleton of a roadmap at the GTC event this week:
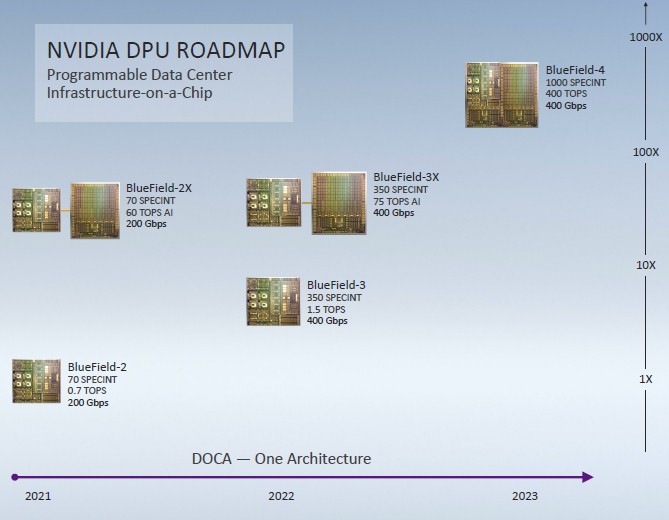
There are a lot of interesting things in this roadmap. First, the integer performance, expressed through the SPEC integer benchmark (presumably rate since it is multicore) is 70, and those integrated NEON SIMD units provide 700 gigaops for AI-style workloads. With the addition of the Ampere GPU to the DPU card, the performance of the machine learning functions increases by a factor of 86X, to 60 teraops.
Next year, with the third generation DPUs, Nvidia plans to boost the performance of the Arm CPU portion of the compute complex by 5X to 350 SPEC integer units and the integrated NEON SIMD units by a little more than 2X to 1.5 TOPS. This almost certainly will use Neoverse cores, probably the “Ares” N1 or “Perseus” N2 core and probably not the “Zeus” V1 cores with the Scalable Vector Extension (SVE) wide math units that was revealed last week. And that scale will come from more powerful cores and a larger number of them. The networking on the BlueField-3 DPU card will be doubled up to 400 Gb/sec, and presumably this is a pair of 200 Gb/sec ports. And the next iteration of the Ampere GPU accelerator for the DPU card will get a 25 percent boost to 75 TOPS in the BlueField-3X variant.
Looking farther out to the BlueField-4 in 2023, the ARM CPU and the Nvidia GPU will be integrated down to a single die. The Arm compute will rise by 2.9X to 1,000 SPEC integer units, and that GPU accelerator on the same die will see its performance rise by 5.3X to 400 TOPS.
These BlueField-3X and BlueField-4 DPU motors will be very powerful indeed, and we say that one server’s DPU is a complete datacenter for the edge.
So why are people so eager to use DPUs? First of all, it is more secure because the control plane can be separated from the dataplane within a system and across clusters of systems. The DPU also frees up capacity on the servers so they can get back to application computing. We are talking on the order of half of the cores on a system that has a lot of I/O and heavy virtualization, so the throughput goes up by 2X. So it is not just about counting the cost of the core, but also of the entire machine, including its memory and I/O and the amount of work this frees up. So, if a heavily loaded server costs $20,000, the DPU only has to cost $10,000 for it to be worth the money given the security and flexibility it affords – and particularly if all of the machine learning acceleration is buried in the system software so companies do not have to create this themselves.
That is the dream that Nvidia co-founder and chief executive officer Jensen Huang had that compelled him to push for Mellanox to be acquired, and that vision, with the datacenter as the unit of compute, is one reason why Nvidia is trying to buy Arm Holdings for $40 billion. The DPU is the lower hanging fruit, but it includes both CPUs and GPUs the way Nvidia is creating it. Which stands to reason.