

Startup Cerebras Systems has unveiled the world’s largest microprocessor, a waferscale chip custom-built for machine learning. The 1.2 trillion transistor silicon wafer incorporates 400,000 cores, 18 GB of SRAM memory, and a network fabric with over 100 Pb/sec of aggregate bandwidth. And yes, those numbers are correct.
Integrated together, those components provide what is essentially a giant ML compute cluster on a chip. And giant it is. A single device is 215 millimeters, or about 8.5 inches, on each side. In total area, that’s about 56 times as large as Nvidia’s GV100 GPU, the current gold standard for training neural networks. As a result, the Cerebras chip has 78 times as many cores as a the GV100, although to be fair, all cores are not equal.

The startup joins a multitude of companies that are designing custom silicon for machine learning. But of this bunch, Cerebras is the first and only one that is employing waferscale integration. In fact, it’s the only company we know of doing any sort of chip with this technology.
True to its name, the waferscale techniques that Cerebras has invented uses most of an entire wafer to lay down all the desired elements of the clustered system. This is in contrast to conventional chip manufacturing, where the wafer is used to etch multiple copies of a processor, which are subsequently cut out and used as individual processors in systems. Up until now, the waferscale technology has mostly been an area for academic research, but every once in a while an enterprising company attempts to build a product with it.
One of the big advantages of waferscale integration is the potential savings achieved in fabrication and packaging, which can be up to half the cost of a chip. The other big advantage is the potential for much better performance, particularly in those cases where high levels of computational intensity are desired, which was the main motivation for the Cerebras designers. Training neural networks is one of the most computationally demanding workloads in the datacenter these days. And according to Cerebras co-founder and chief hardware architect Sean Lie, it’s also “the most important computational workload of our time.”
At this point, most training is being accelerated on GPUs, with Nvidia’s Tesla V100 accelerator as the processor to beat. That V100 chip relies on its customized Tensor Cores within the graphic processor to provide nearly all of this acceleration. However, purely custom-built ML processors are making their way into the market now. This includes early IPU silicon from Graphcore and Habana’s Gaudi chip, as well as the just-unveiled Intel NNP-T processor.
Cerebras’s Lie certainly agrees that developing custom accelerators for training is the answer. “Our industry has shown time and time again that special applications need special accelerators,” he said, noting that DSPs (signal processing), switch chips (network packet processing), and GPUs (graphics) all came about to serve their particular high-volume application markets.
Where Cerebras part ways with the Intels and Nvidias of the world is that training needs a much higher level of integration than conventional chips can provide and the way to deliver that is through waferscale integration. In particular, by putting hundreds of thousands of cores, multiple gigabytes of SRAM (not DRAM) memory, and a high-speed fabric on the chip, Cerebras is claiming orders of magnitude better performance can be delivered. Chip-level integration also makes it easier to custom-design the processors, memory, and network for training.
Here’s a case in point: The on-chip network takes advantage of the fact the communication in neural network training is mostly local, with one layer generally chatting with the next layer. For this, a 2D mesh topology is just fine and delivers the bandwidth and short-wire latency that is optimal for this layer-to-layer cross-talk. In this application space, something like a 6D Tofu interconnect would have been overkill and certainly would have taken up a lot more chip real estate and power.
But the real advantage here is that you don’t need an external interconnect, like Tofu, Slingshot, or InfiniBand to glue together hundreds of thousands of cores. It’s all done on the wafer. Lie says Cerebras took advantage of the unused lines between the individual processor dies (known as scribe lines) that are used as guides when the dies are cut from the wafer. In this case, the space is used to lay down the wiring for the 2D mesh fabric.
The customization applies to memory as well, said Lie. Most neural networks use local memory for weights, activation, and tensor arithmetic, with little data reuse. That makes caching or other types of memory hierarchies less necessary. Here the 18 GB of memory, in the form of SRAM, is distributed across the cores. Assuming that distribution is uniform, that works out to about 22 MB of local memory per core. It’s unclear whether memory can be shared between cores. It’s also unclear if the chip can access any sort of external memory, which given the limitation of the 18 GB on-chip capacity would seem to be necessary.
Lie explained that the advantage of having embedded memory is that it’s just one clock cycle from the core, which is orders of magnitude faster than off-chip memory. Aggregate memory bandwidth for the whole chip is on the order of 9 PB/sec. “It allows the ML to be done the way that ML wants to be done,” said Lie.
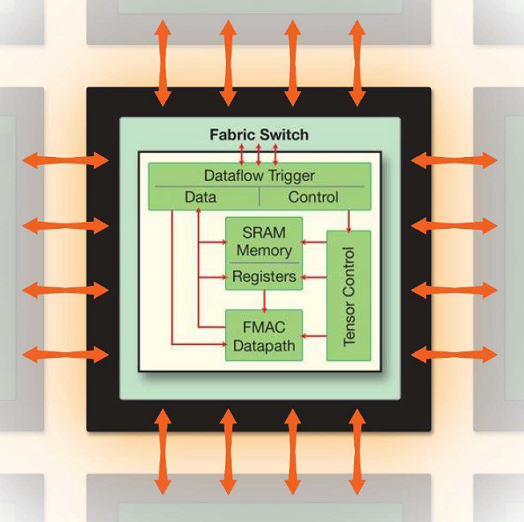
As you might suspect, the cores themselves are specially designed as well. Among other things, that means that the tensors, the basic data currency of machine learning, is provided its own operand format. The cores are also optimized to deal with sparse networks, which is common to most types of ML models. Here, each core uses a hardware dataflow scheduler that is able to filter out unused (zero) elements of a network, which means no time or energy is wasted processing empty space.
Although the native arithmetic naturally supports tensor processing, the cores also include general-purpose operations, like loads and stores, as well as logic and branching operations. That suggests no host processor would be needed in a system containing the Cerebras chip, although as we said, access to external memory (or storage) associated with a host would probably have to be accommodated in some manner.
That said, the general idea is to train a machine learning model in its entirely without having to go off-processor. “Because the chip is so large, instead of running one layer at a time, you can map the entire neural network onto the chip at once,” explained Lie. “And since there is only one instance of the neural network, you don’t have to increase batch size to get cluster-scale performance.”
Understandably, Cerebras has some work to do on the software side, which Lie said was co-designed during the development effort. Apparently, the system software is able to extract the neural network from frameworks such as TensorFlow and PyTorch and map them to the Cerebras compute fabric. The size of the network layers determines how much compute resources are provided, with larger layers getting more resources, smaller layers getting less.
So why isn’t everyone building waferscale processors? Well, because it’s extremely tricky. The current-state-of-the-art in semiconductor manufacturing means you have to incorporate redundancy into the design to get around the inevitable chip defects. In this case, that meant Cerebras included extra copies of both cores and fabric links on the wafer. According to Lie, this redundancy enables them to obtain “incredibly high yields.”
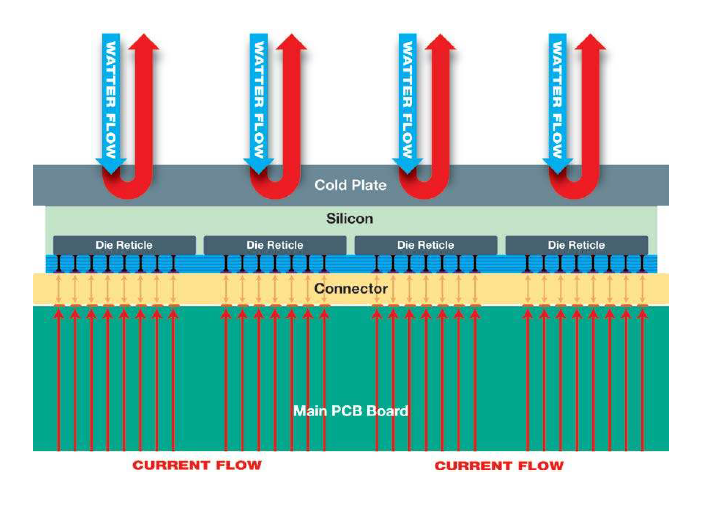
One of the other significant challenges with these big wafers is power and cooling. Thermal stress, in particular, is a problem since silicon expands at different rates from the PCB substrate when heated. This would cause the chip to crack the chip if it got too hot. To get around this, Cerebras used a custom connector layer between the PCB board and the wafer that is designed to absorb the temperature variation. In addition, a water-cooled cold plate sits on top of the silicon to maintain the proper operating temperature. Power is supplied to the wafer by multiple wires that travel from the PCB board, up through the connector to the silicon. Off the cuff, we estimated that this chip would run at around 500 MHz and would generate at least 10 kilowatts of heat, but we have heard rumors to the effect that it actually throws off 14 kilowatts. Cerebras will give us the feeds and speeds as it gets closer to shipping a commercial product.
There is no production chip yet. Although Lie said early customers are running workloads on pre-production silicon, he did not mention when the product would be generally available. As a result, he did not offer some of the more practical information that a potential customer might be interested in, such as wattage, clock rates, and reliability metrics. Oh, and he also left out pricing and performance. Give that this is 56 times larger than a state-of-the-art GPU, we think it’s safe to assume the chip will offer at least an order of magnitude better performance, but not cost an order of magnitude more money. It all depends on how much better – if at all – the waferscale cluster does on actual applications compared to a DGX-2 system that costs under $400,000 with 16 GPUs lashed together, sharing memory. Those are the numbers to beat.

The word “trillion”, as in “1.2 trillion transistor silicon wafer” is ambiguous as it can mean 10^9 or 10^18 (see https://en.wikipedia.org/wiki/Long_and_short_scales#Current_usage).
In this case I assume you mean 10^9 but why not use the unambiguous 10^9?
10^12 is a billion, no? Thousands=10^3, millions=10^6, billions=10^9, trillions=10^12.
may be 10^15 instead
I don’t see it. So you think they might use the long scale at Stanford, where the HotChips was held? From Wikipedia, “The traditional long scale is used by most Continental European countries and by most other countries whose languages derive from Continental Europe (with the notable exceptions of Albania, Greece, Romania,[55] and Brazil). These countries use a word similar to billion to mean 1012. Some use a word similar to milliard to mean 109, while others use a word or phrase equivalent to thousand millions.”