


The history of computing teaches us that software always and necessarily lags hardware, and unfortunately that lag can stretch for many years when it comes to wringing the best performance out of iron by tweaking algorithms.
This will remain true as long as human beings are in the loop, but one can imagine generative AI systems being fed full system specifications for an as-yet unbuilt machine and using adversarial algorithms to come up with the best adaptations of application and system software even before the hardware is etched at the foundry and composed into that system.
But those days are not here yet, and it takes people time and effort to tune the software for the ever-improving hardware.
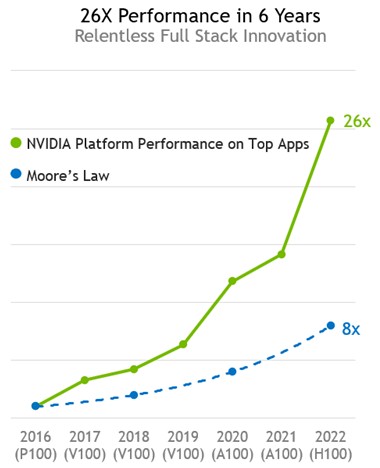
In the AI sector, if the performance improvement for hardware has been steady and in excess of simple Moore’s Law transistor shrinkage as hardware gets more capacious through better compute and more of it, and equally dramatic rate of change in performance is coming from software. This chart from the prior generations of Nvidia GPU accelerators – the “Pascal” P100 versus the “Volta” V100 and the “Ampere” A100 when it was new in 2020 – illustrates the principle well:
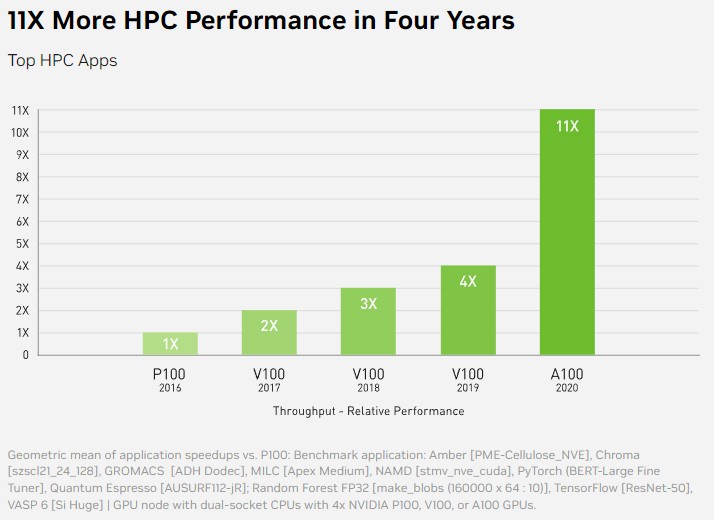
When the V100 was launched in 2017, it offered roughly 2X the performance on a mix of AI and HPC workloads. A year later, after much tuning, the performance of the V100 systems was boosted by 50 percent just through software optimizations, and a year later that V100 performance was boosted to 4X compared to the P100 with half coming from hardware and half coming from software. This chart doesn’t show it, but further software performance improvements were made even after the A100 was launched, and many of these tweaks helped applications running on V100s as well. The larger oomph capacity does not all come through increasingly reduced precision or embiggening matrix math engines as well more of them, but through better algorithms.
This will be the case for the current “Hopper” H100 GPU accelerator generation, too, which debuted in 2022 and which is still ramping up to meet demand. In fact, we don’t think Nvidia will be meeting H100 demand when it launched a successor GPU engine in the spring of next year, as it is slated to do based on its two-year product cadence. If history is any guide, then the H100 offers about 3X more performance across a mix of HPC and AI applications (and AI gets double that boost again as it dropped down to FP8 precision) and then another 6X will come through algorithm changes that are already underway.
Nvidia has just announced one set of algorithm tunings for AI inference, specifically with some tweaks for doing inference for large language models on its TensorRT inference stack. The modifications, called TensorRT-LLM, add an open source modular API for Python, which Nvidia says in the blog post announcing the software tweaks allows for “defining, optimizing, and executing new architectures and enhancements as LLMs evolve,” and adds that it “can be customized easily.” Features for goosing the performance of LLM inference include token streaming, in-flight batching, paged attention, and quantization, and the tweaks can boost LLM inference by quite a bit – basically, on par with what we would expect given that software developers, even inside of Nvidia, need time to refactor or refine their software for the H100s.
Take a look at the inference boost seen for a text summarization workload running on the GPT-J LLM with 6 billion parameters:
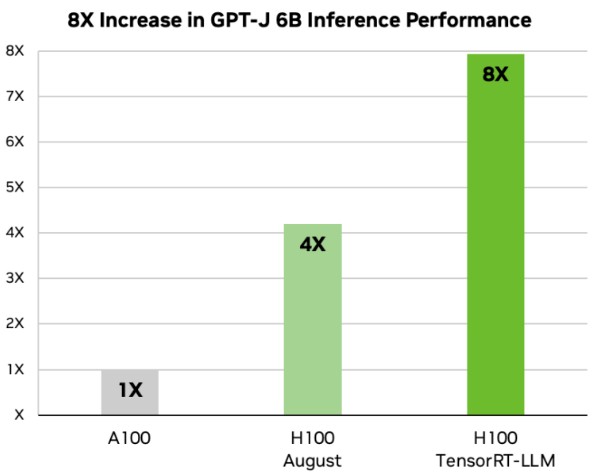
The chart says there was a little more than a 4X boost moving from the A100 running the plain vanilla TensorRT inference engine to the H100 running the same TensorRT stack when tests were done in August. And now, with the Tensor RT-LLM tweaks, the performance of the H100 is now just a tiny bit shy of an 8X performance boost over the A100. That means the performance boost from the TensorRT-LLM tweaks is just a little bit less than 2X – which is still nothing to sneeze at. In-flight batching is apparently one of the big drivers of the performance boost.
This particular benchmark, by the way is text summarization done by GPT-J with variable length I/O and using the CNN/DailyMail dataset. The A100 is using FP16 data resolution with PyTorch working in eager mode, and the H100 is exploiting FP8 data resolution and in-flight batching. In general, batching up of inference requests boosts the throughput of any short, in-flight batching allows for parts of a new batch to be started before all of the current batch is completely finished. (Which sort of makes it not precisely batching anymore, right?) This increases the overall throughput of the GPU as it is doing text generation to be increased. In this case, by a factor of by about a little less than 2X.
Here is how the Llama-2 LLM with 70 billion parameters, which is the top-end model from Meta Platforms at this point, does with text summaries using the same variable length I/O and the same CNN/DailyMail dataset:
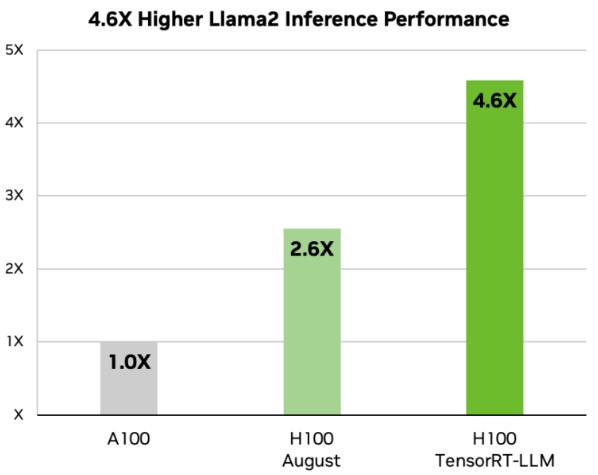
If you do the math (specifically, 4.6X divided by 2.6X), then the addition of the TensorRT-LLM tweaks boosts the performance of the inference on Llama-2 by 1.8X, which is a little bit less of a boost than is seen with the GPT-J model above. What is also interesting is that the jump from the A100 to the H100 using the plain vanilla TensorRT was only 2.6X, which probably speaks to the fact that the Llama-2 model has 11.7X times as many parameters to hold in memory to do the text summarization.
The TensorRT-LLM code is now available for selected early access customers and “will soon be integrated” into its NeMO framework, which in turn is part of the AI Enterprise software stack from Nvidia. Developers and researchers will have access to this TensorRT-LLM code through the Nvidia GPU Cloud or through Nvidia’s source code repository on GitHub. You have to be part of Nvidia’s Developer Program to get early access to TensorRT-LLM.