



Data scientists and deep and machine learning researchers rely on frameworks and libraries such as Torch, Caffe, TensorFlow, and Theano. Studies by Colfax Research and Kyoto University have found that existing open source packages such as Torch and Theano deliver significantly faster performance through the use of Intel Scalable System Framework (Intel SSF) technologies like the Intel compiler and performance libraries for Intel Math Kernel Library (Intel MKL), Intel MPI (Message Passing Interface), and Intel Threading Building Blocks (Intel TBB), and Intel Distribution for Python (Intel Python).
Andrey Vladimirov (Head of HPC Research, Colfax Research) noted that “new Intel SSF hardware and software in combination with code modernization delivered an observed 50x machine learning performance improvement in our case study”. In the Colfax Research and Kyoto case studies as well as general Python scientific computing benchmarks, results run up to two orders of magnitude (100x) faster as a result of using Intel SSF technologies.
New Intel Scalable System Framework hardware and software in combination with code modernization delivered an observed 50x machine learning performance improvement in our case study – Andrey Vladimirov, Head of HPC Research, Colfax Research
Python is a powerful and popular scripting language that provides fast and fundamental tools for machine learning and scientific computing through popular packages such as scikit-learn, NumPy and SciPy. Not just for developers, Intel Python packages offer support for advanced analytics, numerical computing, just-in-time compilation, profiling, parallelism, interactive visualization, collaboration and other analytic needs. Similarly, Python packages such as Theano make deep learning available to non-developers while also providing significant machine and deep learning speedups.
Intel Python is based on Continuum Analytics Anaconda distribution, allowing users to install Intel Python into their Anaconda environment as well as to use Intel Python with the Conda packages on Anaconda.org.. Michele Chambers, VP of Products and CMO at Continuum Analytics notes, “Python is the defacto data science language that everyone from elementary to graduate school is using because it’s so easy to get started and powerful enough to drive highly complex analytics.”
Python is the defacto data science language that everyone from elementary to graduate school is using because it’s so easy to get started and powerful enough to drive highly complex analytics – Michael Chambers VP and CMO at Continuum Analytics
Intel optimized versions of Python (both 2.7 and 3.5) are available for Windows, Linux, and Mac OS. The current Beta release delivers performance improvements for NumPy/SciPy through linking with performance libraries like Intel MKL, Intel MPI, and Intel TBB libraries.
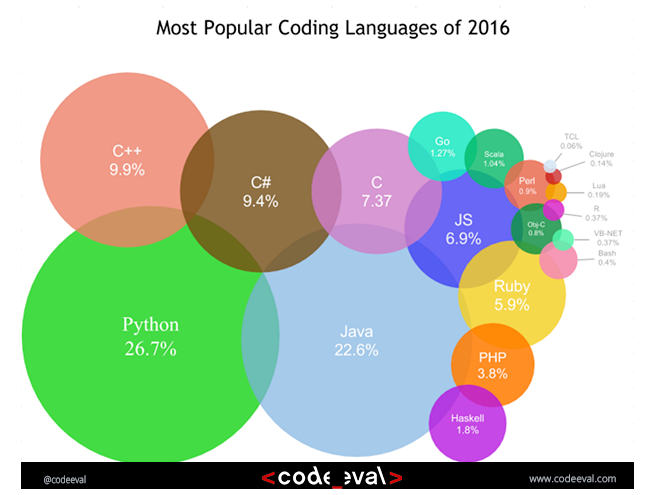
Figure 1: Popularity of coding languages in 2016 (Image courtesy codeeval.com)
The Colfax case study
Colfax research created a proof-of-concept implementation of a highly optimized machine learning application for Intel Architecture using the NeuralTalk2 example.
NeuralTalk2 uses machine learning to analyze real-life photographs of complex scenes and produce a verbal description of the objects in the scene and relationships between them (e.g., “a cat is sitting on a couch”, “woman is holding a cell phone in her hand”, “a horse-drawn carriage is moving through a field”, etc.) Written in Lua, it uses the Torch machine learning framework.
The optimizations Colfax Research performed included:
- Rebuilding the Torch library using the Intel compiler.
- Performing code modernization like batch GEMM operations and incorporating some algorithmic changes.
- Improving parallelization and pinning threads to cores.
- Taking advantage of Intel Xeon Phi processor high-speed memory.
In the case study, presented at ISC’16, Colfax observed performance improvements of over 50x on the Intel Xeon Phi processors and performance gains in excess of 25x on Intel Xeon processors v4 (Broadwell) as shown in figure 2.
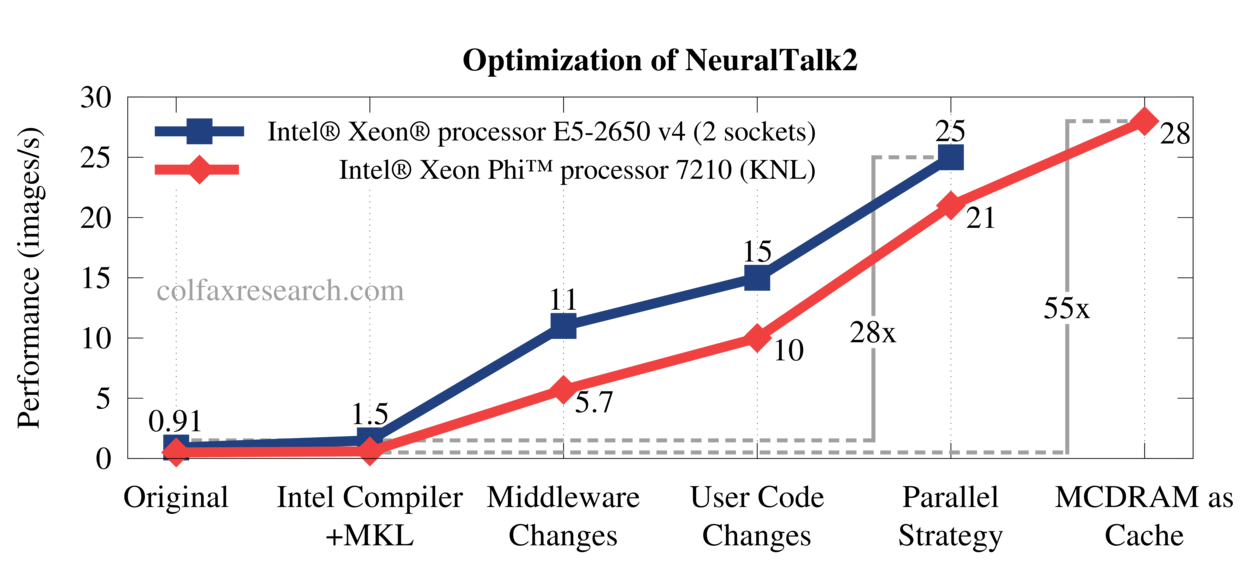
Figure 2: Speedups achieved by Colfax Research on NeuralTalk2 (Image courtesy Colfax Research)
The Kyoto experience
The Kyoto University Graduate School of Medicine is applying various machine learning and deep learning algorithms to problems in life sciences including drug discovery, medicine, and health care. They recognized that the performance of the open source Theano C++ multi-core code could be significantly improved. Theano is a Python library that lets researchers transparently run deep learning models on CPUs and GPUs. It does so by generating C++ code from the Python script for both CPU and GPU architectures. Intel has optimized the popular Theano deep learning framework which Kyoto uses to perform computational drug discovery and machine-learning based big data analytics.
Figure 3 shows the benchmark results for two DBN (Deep Belief Network) neural network configurations (e.g. architectures). The optimized code delivers an 8.78x performance improvement for the larger DBN containing 2,000 hidden neurons over the original open source implementation. These results also show that a dual-socket Intel Xeon processor E5-2699v3 (Haswell) delivers a 1.72x performance improvement over an NVIDIA K40 GPU using 16-bit arithmetic (which doubles GPU performance).
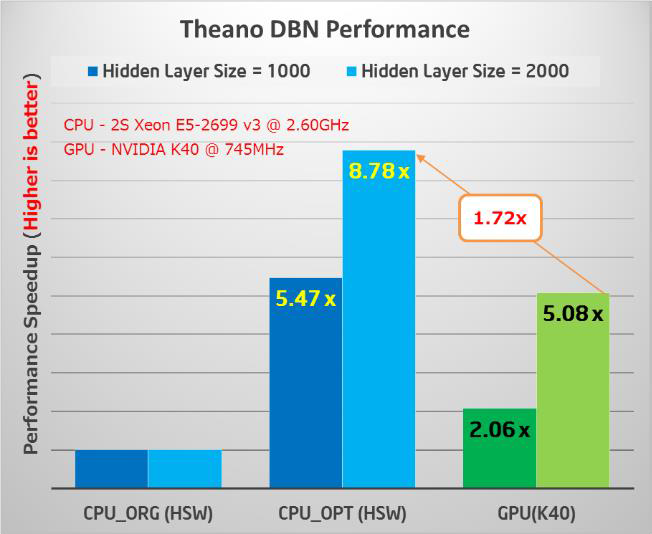
Figure 3: Original vs optimized performance relative to a GPU. The middle bar is the optimized performance (Higher is better) (Results courtesy Intel)
On the basis of the Intel Xeon benchmark results presented by Masatoshi Hamanaka (Research Fellow) at the 2015 Annual conference of the Japanese Society for Bioinformatics (JSBI 2015) and the consistency of the multi- and many-core runtime environment, GPUs were eliminated from consideration as they added needless cost, complexity, and memory limitations without delivering a deep learning performance benefit.
Up to two orders of magnitude faster scientific Python
Heavily used in machine learning, scientific and commercial applications, Python source code can be interpreted or compiled. Traditionally, high performance can be achieved by calling optimized native libraries such as Intel MKL. Continuum Analytics, for example, notes that customers have experienced up to 100x performance increases with Anaconda through the use of optimized libraries and just in time compilation.
Example Intel Xeon processor performance results
As can be seen in figure 4, pure interpreted Python is slow relative to an implementation that calls a native library, in this case NumPy. This graphic also displays the additional performance boost that the multithreaded Intel Python distribution can provide. And figure 5 shows that the performance benefits of Intel Python distribution for a wide range of algorithms by leveraging SIMD and multicore.
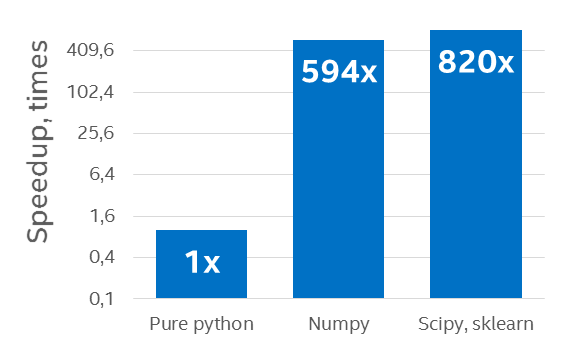
Figure 4: Speedup on a 96-core (with Hyperthreading ON) Intel Xeon processor E5-4657L v2 2.40 GHz over a pure Python example using the default Python distribution (Results courtesy Intel)[i]
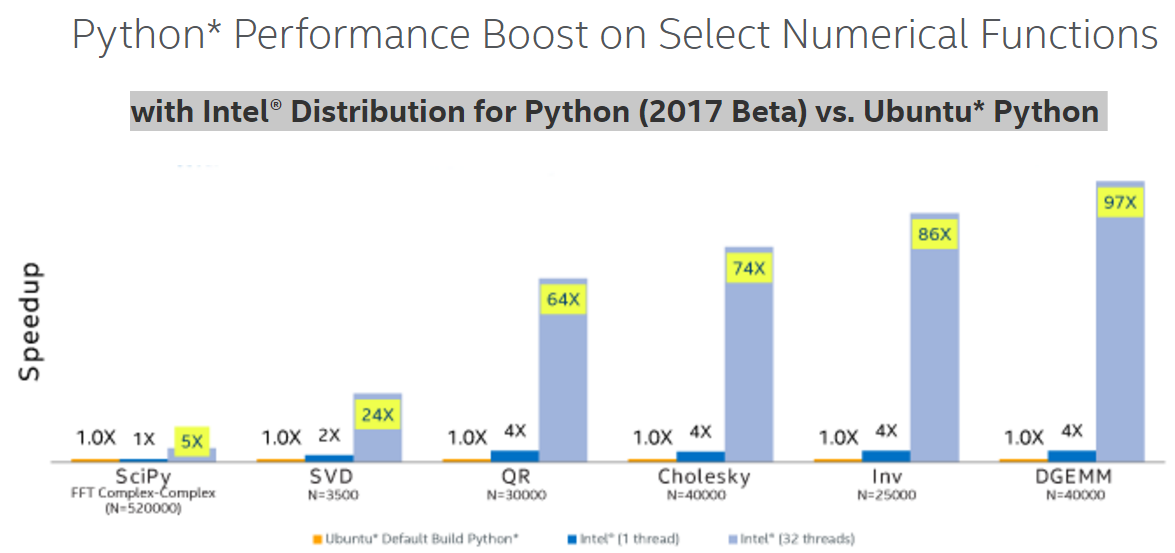
Figure 5: Python performance increase on several numerical algorithms (Image courtesy Intel)[ii]
Intel Xeon Phi processor performance and benefits
In a separate study, Colfax Research has provided benchmark results showing up to a 154x speedup over standard Python when running on the latest Intel Xeon Phi processors.
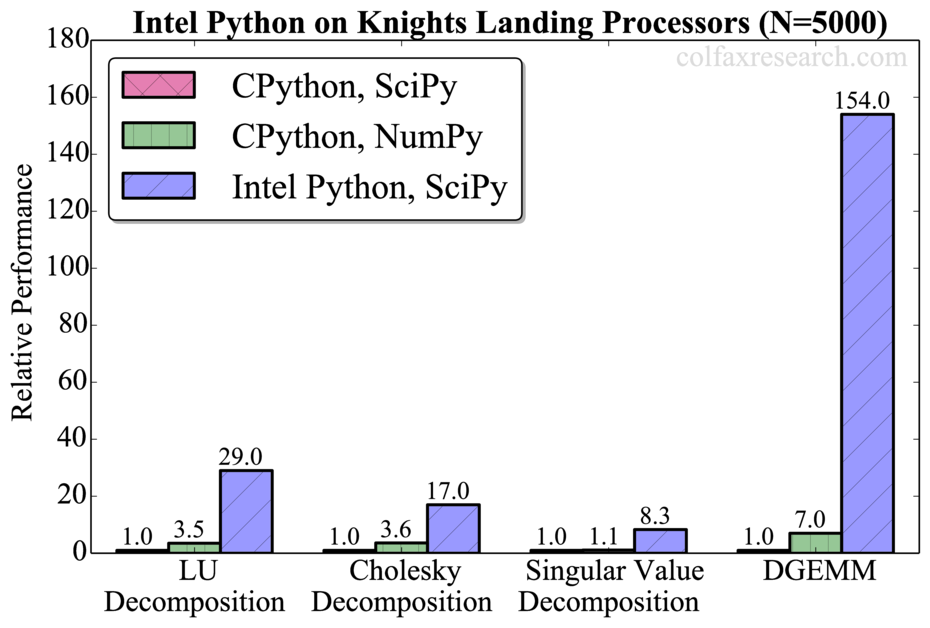
Figure 6: Speedup through the use of MKL and MCDRAM on a 2nd generation Intel Xeon Phi (Image courtesy Colfax Research)
The speedup was achieved using default settings without any special tuning. Thus the performance corresponds to what a normal Python user would experience with one exception: the entire application was placed in the high-speed near-memory (also called MCDRAM or High-bandwidth memory) on the 64-core Intel Xeon Phi processor 7210. The Intel Xeon Phi processor near-memory was used in flat mode, i.e., exposed to the programmer as addressable memory in a separate NUMA node, which simply required placing a numactl command in-front of the executable Python script. (See MCDRAM as High-Bandwidth Memory in Knights Landing Processors: Developer’s Guide for more information about Intel Xeon Phi memory modes.)
$ numactl -m 1 benchmark-script.py
Figure 7: Command to run in high-bandwidth memory on the Intel Xeon Phi
This Python benchmark achieved 1.85 TFlop/s double-precision performance. This high flop-rate reflects 70% of the theoretical peak 64-bit arithmetic performance for the Intel Xeon Phi processor 7210. Colfax notes that during profiling they say that the vector capability of the Intel Xeon Phi processor is fast enough that the MKL time to perform the computation actually took less time than the Python call to the MKL library for many smaller problems.
The performance on traditionally memory unfriendly algorithms such as LU decomposition, Cholesky Decomposition, and SVD (Singular Value Decomposition) are shown in the three examples in figure 8. Performance speedups for the Intel optimized Python range from 7x – 29x.
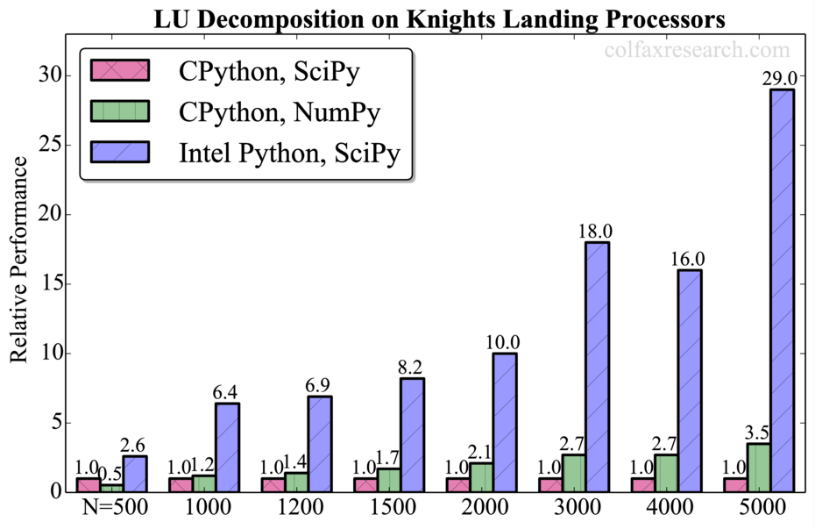
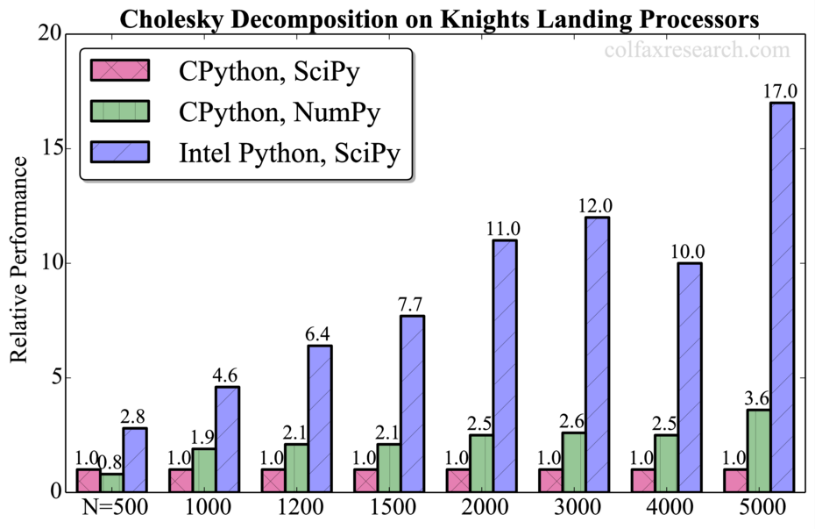
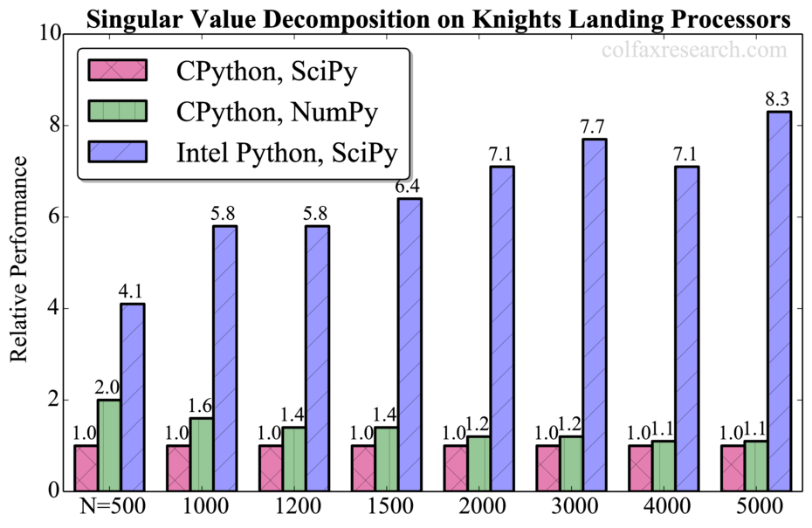
Figure 8: Speedup on a 64-core Intel Xeon Phi processor 7210 (Image courtesy Colfax Research)
Optimized threading for Python using Intel TBB
The Intel optimized Python also utilizes Intel TBB to provide a more efficient threading model for multi-core processors.
It’s quite easy to try. Simply pass the –m TBB argument to Python:
$ python -m TBB <your>.py
Figure 9: Python command-line invocation that will use Intel TBB
Intel TBB can accelerate programs by avoiding inefficient threads allocation (called oversubscription) when there are more software threads utilized than available hardware resources. Intel also provides Python examples that run 50% faster depending on Intel Xeon processor configuration and number of processors.
Optimized MPI for Python using Intel MPI
MPI (Message Passing Interface) is the de facto standard distributed communications framework for scientific and commercial parallel distributed computing. The Intel MPI implementation provides programmers a “drop-in” MPICH replacement library that can deliver the performance benefits of the Intel Omni-Path Architecture (Intel OPA) communications fabric plus high core count Intel Xeon and Intel Xeon Phi processors.
The Intel MPI team has spent a significant amount of time tuning the Intel MPI library to different processor families plus network types and topologies. For example, shared memory is particularly important on high core count processors as data can be shared between cores without the need for a copy operation. DMA mapped memory and RDMA (Remote Direct Memory Access) operations are also utilized to prevent excess data movement. Only when required are optimized memory copy operations utilized depending on the processor uArch. Special support is also provided for the latest Intel Xeon Phi processor 7200 series (formerly codenamed “Knights Landing”).
Intel SSF technologies are changing the performance landscape for CPU-based computing in machine learning. Current benchmark results also indicate it is well worth trying the Beta version of the optimized Intel Python distribution.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology that he applies at national labs and commercial organizations throughout the world. He can be reached at info@techenablement.com.
[i] Configuration Info: – Fedora* built Python*: Python 2.7.10 (default, Sep 8 2015), NumPy 1.9.2, SciPy 0.14.1, multiprocessing 0.70a1 built with gcc 5.1.1; Hardware: 96 CPUs (HT ON), 4 sockets (12 cores/socket), 1 NUMA node, Intel(R) Xeon(R) E5-4657L v2@2.40GHz, RAM 64GB, Operating System: Fedora release 23 (Twenty Three)
[ii] Configuration Info: Versions Intel Distribution for Python 2.7.11.2017 Beta (Mar 08, 2016), Ubuntu built Python 2.7.11, NumPy 1.10.4, SciPy 0.17.0 built with gcc 4.8.4; Hardware: Intel Xeon CPU E5-2698 v3 @ 2.3 GHz (2 sockets, 16 cores each, HT=OFF), 64 GB RAM, 8 DIMMS of 8GB@2133MHz; Operating System: Ubuntu 14.04 LTS; MKL version 11.3.2 for Intel Distribution for Python 2017, Beta
Benchmark disclosure: http://www.intel.com/content/www/us/en/benchmarks/benchmark.html
Optimization Notice: https://software.intel.com/en-us/node/528854