



Evaluating the true performance of HPC systems has never been quite as simple as tracking incremental improvements across processor generations, but is increasingly focused on how these tweaks affect the entire stack–and whether such gains are even useful from a memory or I/O perspective. The processor is just one component of actual performance, especially as the needs of memory-bound and data movement oriented workloads in HPC and large-scale analytics grow. For this expanding set of applications, all the FLOPS in the world won’t mean as much as striking the right architectural balance.
Focusing on memory bandwidth and integer performance over the standard floating point-based metrics much of the HPC world revolves around will, however, require a bit more thought on the part of those who follow supercomputing a bit more casually (think in terms of how politicians consider large investments in HPC centers or how the mainstream press can easily represent a “we are number one, they are number two”). Even still, this emphasis is where the largest national labs and supercomputing sites are focusing their energy as they look ahead to pre-exascale systems.
These were all topics on the table today during a conversation with the man who coined the term “exascale” in favor of the more floating point-oriented “exaflop computing” moniker Department of Energy was coming up with its vision for the next waves of system performance improvements. During a sit-down with The Next Platform today, IBM’s Vice President of Technical Computing and Open Power, Dave Turek, said that when the attention is finally directed at the ability of the largest, fastest systems on the planet to actually run at their true peak against real applications, the way large HPC sites consider the value per dollar of these multi-million dollar machines will start to shift.
To be fair, this change is already happening. The move away from the single metric of system value via the LINPACK benchmark (the sole benchmark for the bi-annual Top 500 supercomputer list) started a few years ago with key system owners at major DoE labs refusing publish LINPACK results for the Top 500 list—instead choosing to showcase system success by touting application-specific benchmarks.
And to be fair as well, there are many systems that we will never see on the Top 500. Additionally, these are the users of large-scale HPC that are increasingly less compelled by sheer floating point performance and far more engaged with watching where both applications and the resulting data movement demands are heading. These users are dialing their performance requirements around a balance of data movement, storage, and compute. In short, architecting for reality—even if the vendor world might still be propelled by metrics the market has outgrown.
“When we were certifying the Sequoia system at Livermore, the application they wanted us to certify on show a much greater correlation of performance to memory bandwidth and integer performance versus floating point—and this true across a range of application in weather, fluid dynamics, and others. When we did Sequoia from a redesign perspective we were basically doing BlueGene all over again but with amplified integer performance and memory bandwidth without touching anything related to floating point. They had a 3X advantage over X86 in memory bandwidth alone. Then if you look at NVlink and GPUs and the work we’re doing there, there are even bigger memory bandwidth implications,” Turek explained.
“If you take a Power8 chip and look at its floating point content next to Haswell, you’ll see it’s not even close—so how are we able to run applications 2X faster? It’s our architectural approach. They might have a fair amount of floating point advantage but it doesn’t yield. But the point is, the question about floating point is irrelevant.”
The move away from floating point performance is being actively addressed by one of the creators of the LINPACK benchmark, Jack Dongarra, and his teams. However, the new benchmarking effort, called HPCG, does not go far enough to address the problem with benchmarking for large HPC systems, Turek argued, noting that “it’s inconceivable that there could be a single metric to assign value to any system.”
But without well-known benchmarks, how will the industry wrap their heads around valuation of systems? By application-specific benchmarks, for starters. And besides, this is the direction many of the top commercial HPC centers have already been taking. Turek said that there are many machines that we will never see offering up listed benchmarks (the figure could be 10X the number of supercomputers on the Top 500 list he casually guessed, particularly in finance and government/intelligence).
“Besides,” said Turek, “benchmarks can always be gamed. If you look at something like Graph 500 for instance, we took three smart people, gave them three weeks, and we killed it. These are marketing artifacts that we think are unproductive at best and in many cases, harmful.” However, the problem for a company like IBM, which wants to keep pace with the procurement stories that are, for better or worse, still revolving around the LINPACK benchmark. Is that this is still a valid measure. The goal then is to create awareness around how it floating point performance benchmarks are a poor measure of how users will actually extract value from their investments.
To that end, IBM pointed us to a recent report that highlights how current architectures are not snapping in with the demands of existing HPC and large-scale analytics workload. While we’ll be talking more about this report in the coming weeks, there are a few charts that highlight Turek’s point, including the one below. While it’s the most general, notice the architectural-to-application imbalance:
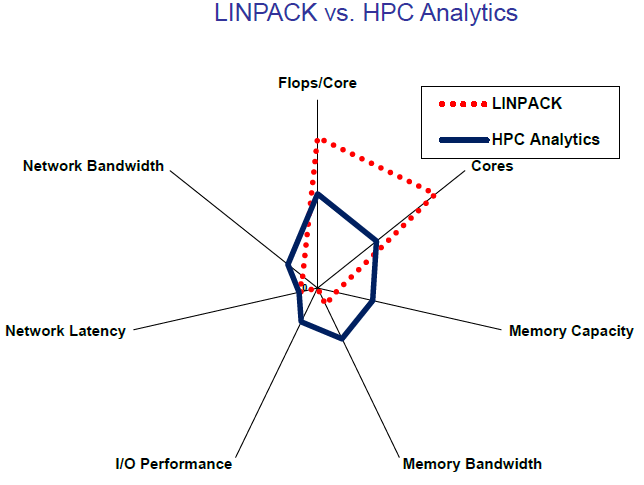
While much of the above stands on its own without much explanation, particularly on the memory bandwidth and I/O fronts (which LINPACK doesn’t adequately capture) take a look at how this plays out across some broader application sets common to HPC.
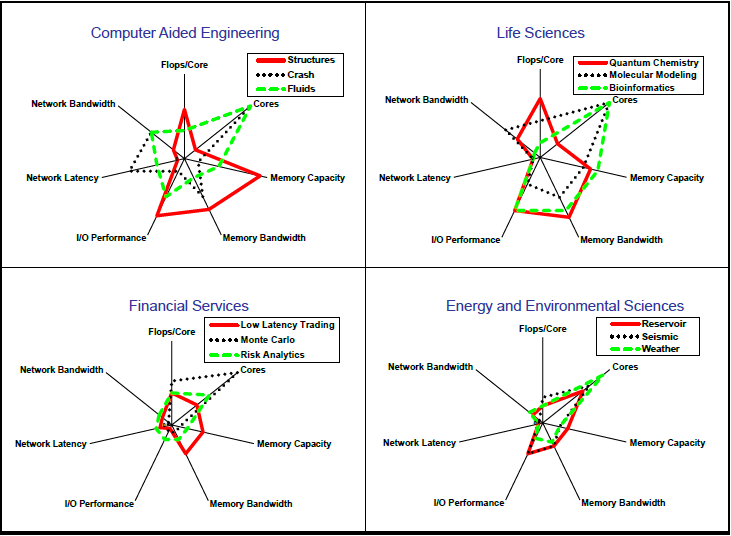
Turek says the really large companies they are talking to with massive HPC operations have already been looking past the floating point bridge. They are also, he says, projecting the crash of the commodity HPC market by around 2017 in favor of a shift toward more purpose-built, specialized systems (not so unlike Google’s approach if you’ll recall). The monolithic X86 culture will continue to thrive for a long time yet, but as applications are rerouted to take advantage of more cores, require far more memory, and an exponential increase in data movement potential, a new type of system entirely will emerge.
Whether that system will look like the type of Power9 and GPU machine connected with NVlink we’ll see in Summit and Sierra or another pairing of technologies from other vendor partnerships remains to be seen. But even if one looks at the largest of machines at the DoE for instance, there will need to be a balance. IBM will continue to invest in these types of systems, says Turek.
“The reason we do it is to get early insights into problems that will sprinkle down to the rest of the market. We don’t make much money from these kinds of things but the important thing is that we get our smartest people grasping these issues early and looking at them over a long period of time.”