


Wide area networks and datacenter interconnects, or DCIs, as we have known them for the past decade or so are nowhere beefy enough or fast enough to take on the job of scaling AI training workloads across multiple datacenters. And so Nvidia, Broadcom, and now Cisco Systems have created a new category of networking called the scale across network.
For a bunch of different reasons, this scale across network is absolutely vital to the scalability of AI workloads, as much as the scale up network that is inside the rackscale systems and that link together the memories of GPUs and XPUs (and sometimes CPUs) into a memory area network. The scale up network makes a bigger computational/memory node, the scale out network connects thousands of these rackscale nodes together using Ethernet or InfiniBand (increasingly Ethernet), and then the scale across network allows for multiple datacenters to be interlinked so they can share work as one giant cluster.
Broadcom fired the first salvo in the fight for scale across network market share back in the middle of August with the “Jericho 4” StrataDNX switch/router chips, which started sampling at that time and that offer 51.2 Tb/sec of aggregate bandwidth backed up by an unknown amount and type of HBM memory to act as a deep packet buffer to help with congestion.
Nvidia unveiled its Spectrum-XGS scale across network two weeks later, with CoreWeave as its anchor first customer. This is a cheeky name given that Broadcom’s “Trident” and “Tomahawk” switch ASICs are called the StrataXGS family. Nvidia did not provide much in the way of details about the Spectrum-XGS ASICs, which is why we have not dived into it yet.
And now Cisco is rolling out the components for its scale across network – which we cannot call a SAN because that acronym has been used for storage area network for the past three decades – with its “Dark Pyramid” P200 router chips and 8223 series of scale across interconnect routers.
Why DCI Is Not Scale Across
Before we get into the speeds and feeds, some definitions are in order. We also feel that it is important to note the inevitability of this scale across network for AI workloads, which the hyperscalers and cloud builders have been cobbling together for Web infrastructure workloads and which is insufficient to meet the needs of the ever-embiggening AI training jobs among the model builders.
Here is how Rakesh Chopra, who has spent 27 years at Cisco in various roles, who became a Cisco Fellow in 2018, and who has spearheaded the development of the Silicon One merchant ASICs for switching and routing to take on Broadcom and, to a lesser extent then and to a greater extent now, Nvidia/Mellanox, sees the delineations in the datacenter network:
“DCI, I think, is basically connecting datacenters to the end users, and that’s typically over sort of a traditional wide area network. What we are talking about today, and what other people in the industry have been talking about in the last month or so, is the notion of a scale across network connecting to scale out networks across datacenters. This is about taking the high bandwidth scale out network and bridging the datacenter so it has massively higher bandwidth than a datacenter interconnect.”
“Different people have different views around how long of a distance the scale out network needs to be in order to sort of solve the power challenges and scaling challenges of AI. What we are saying is that you need to do that with the buffers and security, because you are leaving the confines of the datacenter. Unlike others in the industry, who are taking what I would call an “either/or” approach – half the people are saying they are going to do proactive congestion control, and I’m going to use traditional switches to connect datacenters together, and you have other people out there are saying you don’t need advanced congestion control and just put a deep buffer router in between the datacenters.”
“Our view is that you actually need both because the one thing that you can’t solve with advanced congestion control algorithms is the notion of pre-determining your path through your network. Because AI workloads are deterministic, the failure conditions cause a reactive congestion control, which has to kick in and over those distances you need the deep buffers.”
“So in a funny way, this whole notion of scale across is almost the nirvana moment for Silicon One, which you and I have talked about over the years and which involves bringing these two disjointed worlds together –you have got to get the capabilities of routing at the switching efficiency.”

With that out of the way, the question is this: Why not just build a datacenter the size of Manhattan – the one in New York, but it might be located in the one in Kansas for latency reasons in the United States – and take Ultra Ethernet gear and put 10 million XPUs on a single network? The hyperscalers did this for data analytics, putting 50,000 or 100,000 CPUs in a single datacenter and then used container systems to wrap up the modules of applications and place them on this raw compute at any scale they wanted. Right?
Yes, but the difference is that web infrastructure and its related data analytics that drove the hyperscaler businesses burned 15 kilowatts per rack and maybe reached up to 30 kilowatts per rack in recent years. We are at around 140 kilowatts per rack for rackscale GPU infrastructure from Nvidia, and we are going to 1 megawatt per rack before the end of the decade. So powering up 10 million XPUs in one place is problematic because getting all of the power there – even if it is electric generators burning natural gas – is a big problem.
So is the price of electricity, which varies widely by region around the globe. Here is what the cost per kilowatts-hour looks like in the United States:
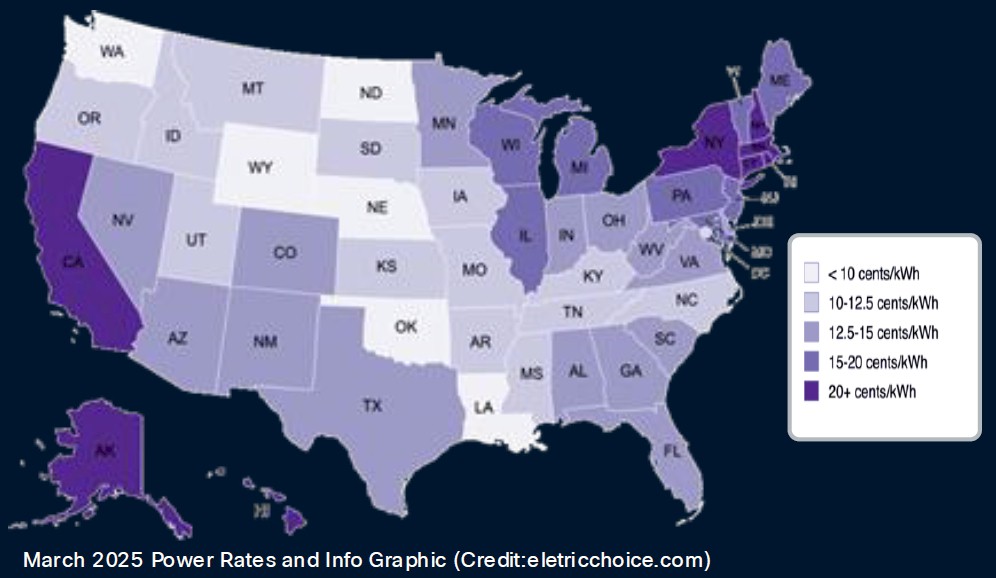
Large datacenters are like big animals on the African savannah: They follow the water, but they also follow the food, which in this case is electricity, not grass or meat, depending. And so, the hyperscalers and clouds have been spreading themselves out, and the AI datacenters will have to do it for sure given their power density and the absolute draw they have for any given datacenter.
But more importantly, even without these power constraints, a scale across network would have been necessary because you can only interconnect a room that is so big in a way that can be expanded. It is easier – and perhaps only technically and economically feasible – to build eight datacenters and scale the AI processing capacity across them over time (and therefore space) rather than try to build it all at once. Just like the compute socket is moving to chiplets to improve yield and lower cost, the datacenter is being broken up into pieces and interconnected. How fractal this is all becoming. Datacenters look like chip sockets, as we have pointed out before. The scale across network, then, is like Infinity Fabric writ large. Very large, as it turns out.
Chopra walked us through the scale of GPU clusters and then various networks inside and across the datacenters as we crest above the 50,000 GPU barrier of a datacenter. Here is the evolution of the GPT models from OpenAI, which shows the exponential ramp in compute that the model builders are all wrestling with:

Clearly, a 20 watt brain that can get an A on the Measuring Massive Multitask Language Understanding (MMLU) benchmark test that used to be used to rate AI models is pretty impressive. But putting that aside for the moment, one only need think about GPT-6, whatever that might be – 200,000 GPUs and 1×1027 exaflops of performance perhaps – to see how multi-datacenter clusters are going to be necessary.
The GPT-5 model started breaking the walls of the datacenter, and others surely are doing it, too.

Look at how much more bandwidth is in the front end network to connect to compute and storage compared to the old WAN/DCI for webscale stuff – about 7X higher. Scale up bandwidth for linking (O)100 GPUs in a rackscale system is 504X more than the WAN. (That shared memory across XPUs comes at a huge bandwidth cost.) And even the scale out bandwidth to link rackscale nodes together is 56X greater than the WAN/DCI interconnect.

At the low end of the scale across network, which will be necessary to connect 1 million XPUs together across what is probably on the order of 20 datacenters, you need around 14X the bandwidth of the WAN/DCI network, which weighs in at around 914 Tb/sec and when you do the math, the scale out network that Chopra says Cisco can build with its new Dark Pyramid P200 ASIC delivers around 12.8 Pb/sec. (The charts round up to 13 Tb/sec.)
It takes hundreds of planes in dozens of modular chasses of routers (or a similar number of devices in a lead/spine network) to aggregate the nearly 1 Pb/sec of WAN/DCI interconnect; that takes around 2,000 ports exposed to the datacenter. The scale across network, says Chopra, would require thousands of planes using 51.2 Tb/sec ASICs in modular chassis to deliver the 16,000 ports running at 800 Gb/sec to hit 12.8 Pb/sec of aggregate bandwidth. But you can’t really build a modular switch that big and have it look like one big switch.
This can only be done practically with a leaf/spine network, and specifically, you need 512 leaves with 64 ports running at 800 Gb/sec and 256 spines interlinking them to get to 13.1 Pb/sec. (That is full-duplex routing, so the actual bandwidth is twice that rate, which only measures one direction.)
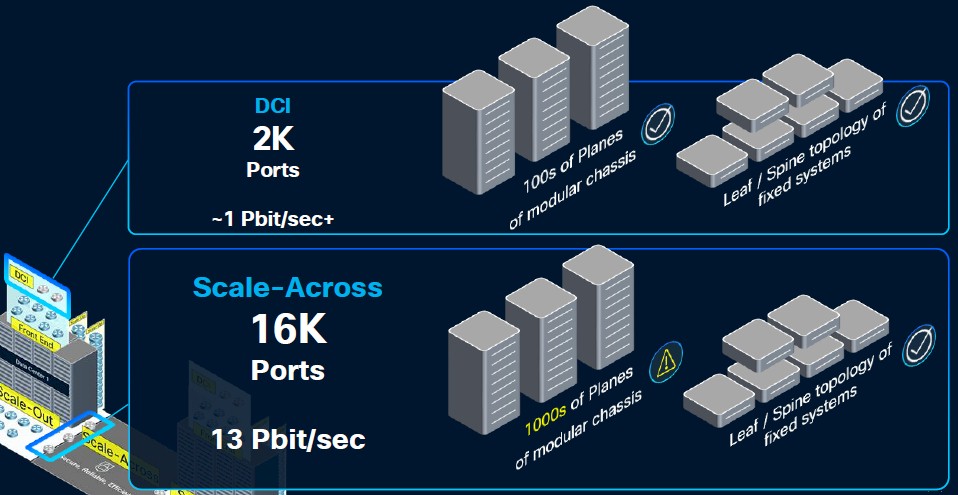
If you want to do a three tier aggregate/spine/leaf network, you can drive 3,355 Pb/sec of aggregate bandwidth across the scale across network using the P200 devices. So there is plenty of bandwidth headroom here if you want to pay the extra two hops. (Datacenter operators may have no choice but to do that until the P300 or P400 or P500 router chip comes along with higher radix and bandwidth.)
The Dark Pyramid – is that the one on the US dollar? Or the one buried in Alaska? – ASIC has 51.2 Tb/sec of aggregate bandwidth across its 64 ports. The P200 has 64 ports running at 800 Gb/sec speeds, and it comes with two stacks of HBM3 memory that add up to a total of 16 GB of deep packet buffer. The chip can process over 20 billion packets per second and do over 430 billion routing lookups per second.

The P200 ASIC is available to customers who want to build their own scale across routers, but Cisco is selling its own as well, and they are sampling now just as the ASICs are to several hyperscalers. The “Mustang” 8223-64EF switch is a 3U switch that has OSFP800 optics, and the “Titan” 8223-64E is a similar switch that has QSFP-DD800 optics.

These routers run the Cisco IOS-XR network operating system as well as the open source SONiC network operating system. Chopra tells The Next Platform that eventually Nexus 9000 switches with deep buffers will also be based on the P200 and that the Cisco NX-OS network operating system will be ported to run on these devices.
These devices are coming along just in time. Take a look at what it took to build a modular chassis with 51.2 Tb/sec of bandwidth only two years ago compared to today with a single Dark Pyramid chip and a single chassis:

If you can wait a year or two for the next generation of networks, clearly it always pays off. Sometimes you just can’t wait, however. Which is why money keeps coming into Cisco, Nvidia, Broadcom/Arista, and others.