


Once a hyperscaler or a cloud builder gets big enough, it can afford to design custom compute engines that more precisely match its needs. It is not clear that the companies that make custom CPUs and XPUs are saving money, but they are certainly gaining control and that is worth something.
Arm made a push based on the power-efficient nature its architecture, and Nvidia has become a key player in AI with its powerful GPUs and now its “Grace” Arm server CPUs. A reinvigorated AMD has given system makers an x86 alternative to an Intel that is still trying to find its footing after a few years of missteps and missed deadlines. And now, the community for RISC-V, the open, modular, and highly customizable architecture overseen by the RISC-V International collective, is looking to make inroads into datacenters.
It is still early days for RISC-V, much as it was for Arm in the datacenter back in 2010, but the RISC-V architecture is being embraced by a range of well-known tech vendors, from Intel, Western Digital, Google, Nvidia, Meta Platforms, and Qualcomm, and a growing number of pure-plays and startups, such as Andes Technology, SiFive, Microchip Technology, Ventana, and Lattice Semiconductor.
There also is money backing the effort. Most recently, the European Union continued its on-again, off-again courting of RISC-V for supercomputers and other HPC systems in the region with the launch in March of DARE – Digital Autonomy with RISC-V in Europe – to oversee a six-year, $260 million effort.
Condor Takes Flight
Andes is two decades old and, despite its name, is based in Taiwan, not in Colombia, Chile, Peru, or Argentina where the mountain range of that name is located on the western coast of South America. The company is a founding member of RISC-V International and a maker of efficient and low-power processor cores based on the architecture.
Mark Evans, director of business development at Andes and now its Condor Computing subsidiary that was established in Austin, Texas to get indigenous to the United States, gave an overview of the company in a session at the AI Infra Summit in Santa Clara last week. The week before that Ty Garibay, Condor’s founder and president, and Shashank Nemawarkar, Condor’s director of architecture, walked everyone through the “Cuzco” core that the company has created to begin its assault on the datacenter in earnest.

Evans says that Andes has shipped its intellectual property in over 17 billion RISC-V chips since 2005, and further that it has been growing sales at a compound annual growth rate of 29 percent between 2018 and now. Evans put some numbers on it, saying that Andes had $42 million in sales in 2024, and that its IP was present in 30 percent of RISC-V SoCs that were shipped last year.

The Andes customer base is pretty broad across various industry sectors, including MediaTek and Novatek in mobile devices, Phison in storage, and Meta Platforms and SK Telecom in AI compute engines.
Evans says that 39 percent of the revenue that Andes had in 2024 came from the AI sector, significantly including the MTIA v1 and MTIA v2 coprocessors from Meta.

That brings us to the “Cuzco” RISC-V core that Condor was showing off at the Hot Chips 2025 conference.
In July, Condor successfully did full hardware emulation of the Cuzco core, booting multiple operating systems, including Linux, with the first users expected to get the processor sometime in the last quarter. This high-performance RISC-V core has microarchitectural tweaks, including the way it issues instructions and organizes execution units, all with the aim of creating what Garibay said will be “the world’s highest performance licensable RISC-V CPU IP,” with a broad range of use cases.
“We’re entirely focused on bringing an innovative new microarchitecture to the RISC-V CPU market,” Garibay said during a presentation at Hot Chips. “We intend to demonstrate that RISC-V can be competitive in any high-performance computing application, from datacenters to handsets to automotive. … Our goal is to provide much better performance than other high-performance, licensable CPUs while operating at a similar power envelope.”

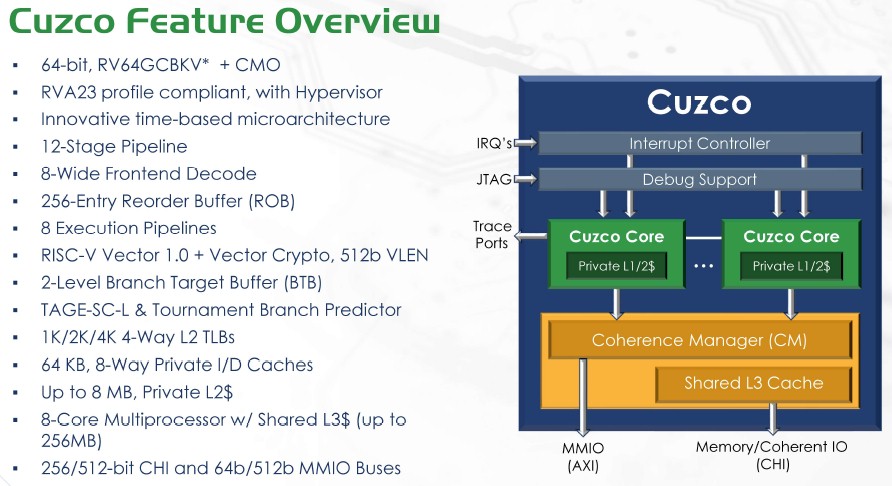
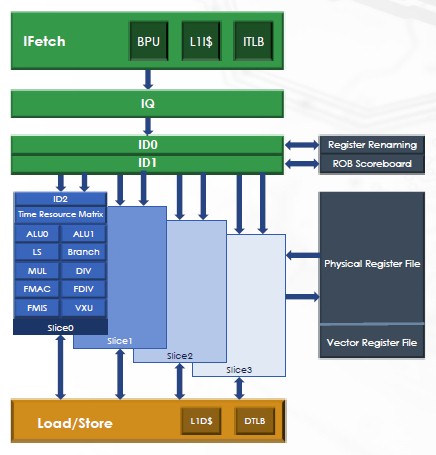
Cuzco is based on the latest RISC-V profile for datacenter computing – RVA-23 – so ensure high software compatibility, can support up to eight cores with up to 8 MB private L2 cache in a coherent cluster with a shared 256 MB L3 cache, and a 12-stage pipeline. There are functional units that execute through a pool after the eight-instruction dispatch. The CPU itself is standard, with fetch, instruction queue, and instruction decode, he said.
Below is a more detailed block diagram of the Cuzco core:
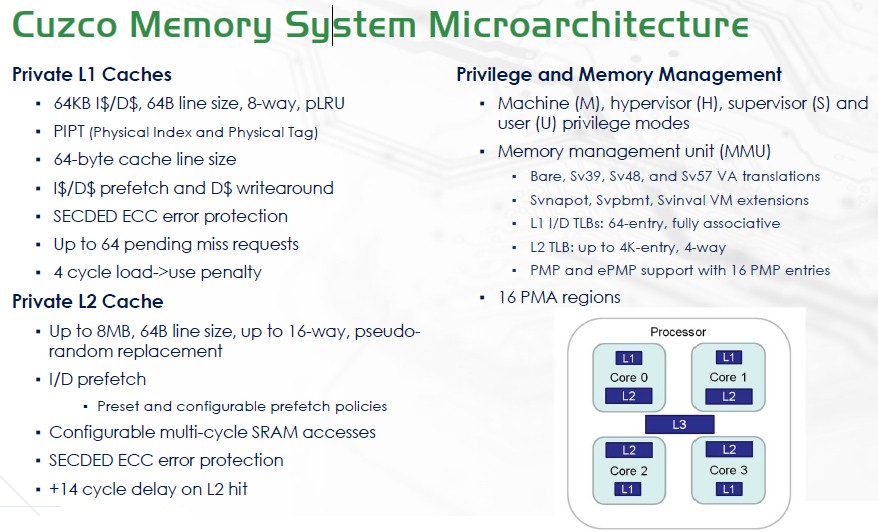
Here is the cache memory architecture:
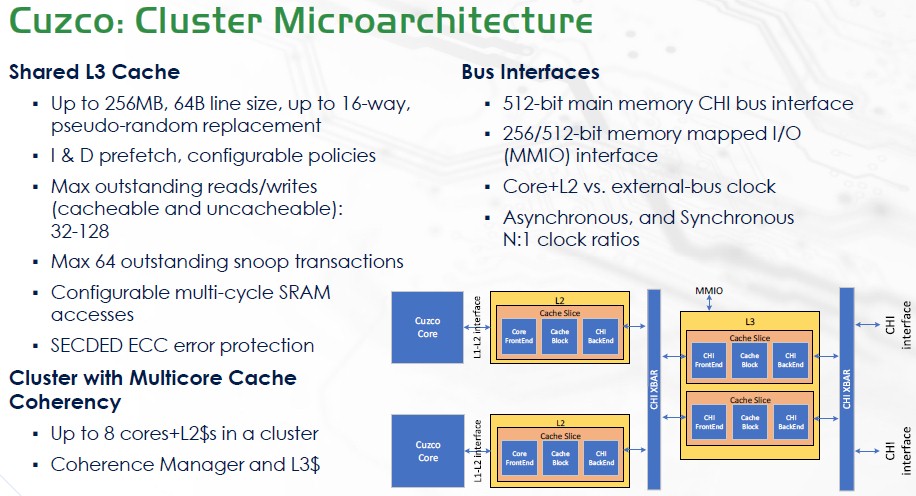
And here is the socket architecture:
The structure of the core is what is really interesting with Cuzco, so we are going to spend our time there.
One area Condor focused on was the structure of the execution units, which Garibay said are pair into two pipelines called a “slice,” with each of the four slices being identical and each having its own pipelines and resources.
“Each slice fully implements RISC-V compatibility,” he said. “The machine is scalable, in theory, down to one slice or pair of pipelines, although. practically probably, only anyone would ever implement is two slices. As a minimum machine, the overhead becomes unwieldy at that point. But it is scalable to six pipelines, three slices by default – eight pipelines, four slices – and then we will extend this architecture into the future, with added features as we grow the slice count.
The intent, he said, “was to ease the implementation of this in high-performance processes.”
Then comes the time-based architecture for instruction sequencing. The chip starts out with what Nemawarkar called “a standard pipeline for the out-of-order machines. Typically, this is a 12-log stage pipeline. The instruction fetch, nothing different than most of it you have seen.”
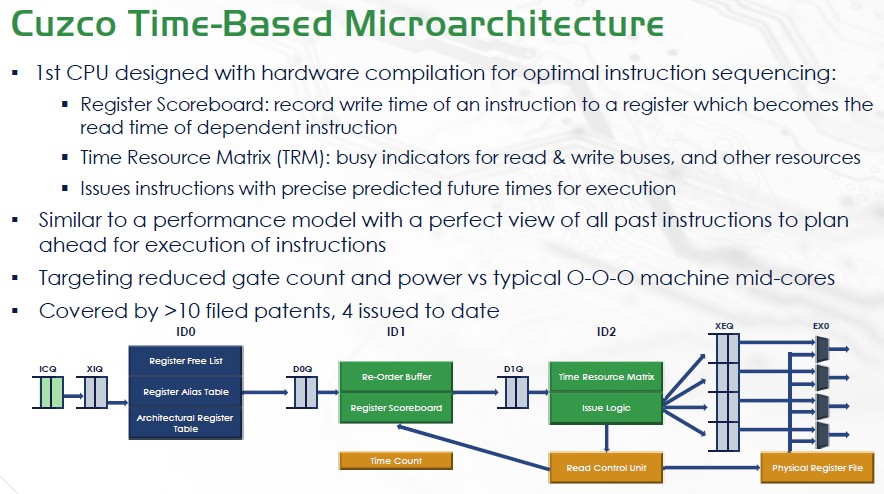
Changes come from the point of where instruction decode happens, Nemawarkar said. That’s where the time-based issuing logic kicks in. Most chips use Tomasulo’s algorithm, a process for the out-of-order scheduling of instructions. In these cases, the chips use content-addressable memories (CAMs) to point to instructions to send downstream. CAMs can eat up a lot of power, given the match-line switching and precharge cycles needed.
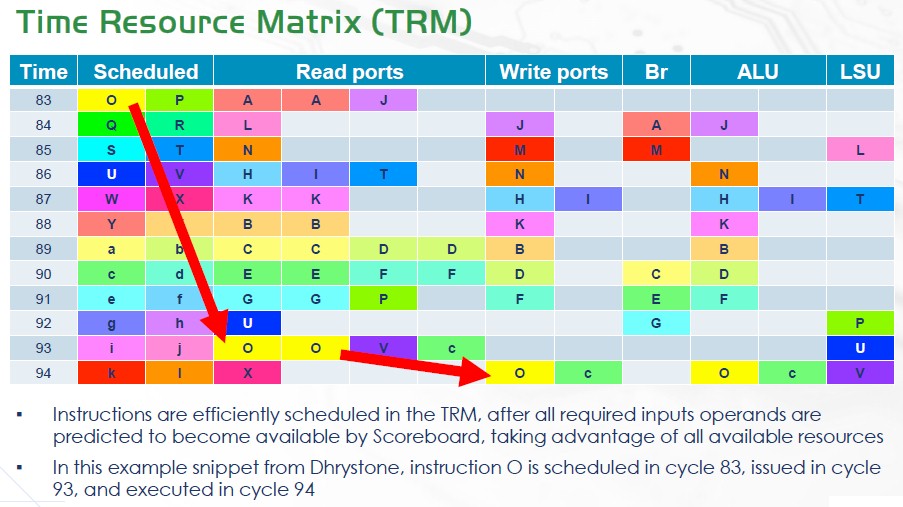
Cuzco uses its register scoreboard to record the write time of an instruction to a register, which then becomes the read time. The scoreboard says when the instruction is available for execution and tracks the future of write time of instructions. The chip’s time resource metrix (TRM) records the use of resources like arithmetic logic units (ALUs), buses, and load and store queues to help predict ahead of time what resource will be available, which enables predictive scheduling. Instructions can be issued with an understand of exact future cycles for operands and resources, according to Andes.
It also does away with the power-hungry CAMs.
“The reasoning behind that is this allows us to reduce the complexity, which typically happens in the global scheduling or a local scheduling or combination of that, when the machines start to become wider and wider,” Nemawarkar said. “Everybody knows that being a huge problem. Then essentially, with each execution unit, you need to start looking at which instructions are ready, how do I execute based on the priority for which instruction to be given, etc.”
It’s something that other implementations haven’t tried before, according to Garibay.
“It is a departure, and it’s a good departure in that we’re looking to reduce the overall power and area of what has become the most power-and-area-hungry part of these wide, out-of-order machines – instruction scheduling,” Garibay added.
Enterprises and HCP centers will be able to put Cuzco to the test by the end of the year so see how the new execution units and out-of-order instruction scheduling will work for them.