


As we pointed out a year ago when some key silicon experts were hired from Intel and Broadcom to come work for Meta Platforms, the company formerly known as Facebook was always the most obvious place to do custom silicon. Of the largest eight Internet companies in the world, who are also the eight largest buyers of IT gear in the world, Meta Platforms is the only one that is a pure hyperscaler and that does not sell infrastructure capacity on a cloud.
And as such, Meta Platforms owns its software stacks, top to bottom, and can do whatever it wants to create the hardware that drives it. And, it is rich enough to do so and spends enough money on silicon and people to tune software for it that it could no doubt save a lot of money by taking control of more of its chippery.
Meta Platforms is unveiling homegrown AI inference and video encoding chips at its AI Infra @ Scale event today, as well as talking about the deployment of its Research Super Computer, new datacenter designs to accommodate heavy AI workloads, and the evolution of its AI frameworks. We will be drilling down into all of this content over the next several days, as well as doing a Q&A with Alexis Black Bjorlin, vice president of infrastructure at Meta Platforms and one of the key executives added to the custom silicon team at the company a year ago. But for now, we are going to focus on the Meta Training and Inference Accelerator, or MTIA v1 for short.
For all of you companies who thought you were going to be selling a lot of GPUs or NNPs to Facebook, well, as we say in New York City, fogettaboutit.
And over the long haul, CPUs, DPUs, and switch and routing ASICs might be added to that list of semiconductor components that are not going to be bought by Meta Platforms. And if Meta Platforms really wants to create a lot of havoc, it could sell its own silicon to others. . . . Stranger things have happened. Like the pet rock craze of 1975, just to give one example.
NNP And GPU Can’t Handle The Load With Good TCO
The MTIA AI inference engine got its start back in 2020, just as the coronavirus pandemic was causing everything to go haywire and AI had moved beyond image recognition and speech to text translation to the generative capabilities of large language models, which seem to know how to do many things they were not intended to do. Deep learning recommendation models, or DLRMs, are an even hairier computational and memory problem than LLMs because of their reliance on embeddings – a kind of graphical representation of context for a dataset – that have to be stored in the main memory of the computational devices running the neural networks. LLMs do not have embeddings, but DLRMs do, and that memory is why host CPU memory capacity and the fast, high bandwidth connections between the CPUs and the accelerators matters to DLRMs more than it does for LLMs.
Joel Coburn, a software engineer at Meta Platforms, showed this chart as part of the AI Infra @ Scale event that illustrates how the DLRM inference models at the company have been growing in size and computational demand in the past three years and how the company expects them to grow in the next eighteen months:

Keep in mind, this is for inference, not training. These models absolutely blasted through the relatively small amount of low precision compute that on-chip vector engines in most CPUs supply, and on-chip matrix math engines such as those now on Intel Xeon SP v4 and IBM Power10 chips and coming to AMD Epycs soon may not be enough.
Anyway, this is the kind of chart we see all the time, although we have not seen them for DLRMs. This is a scary chart, but not terrifying like this one:
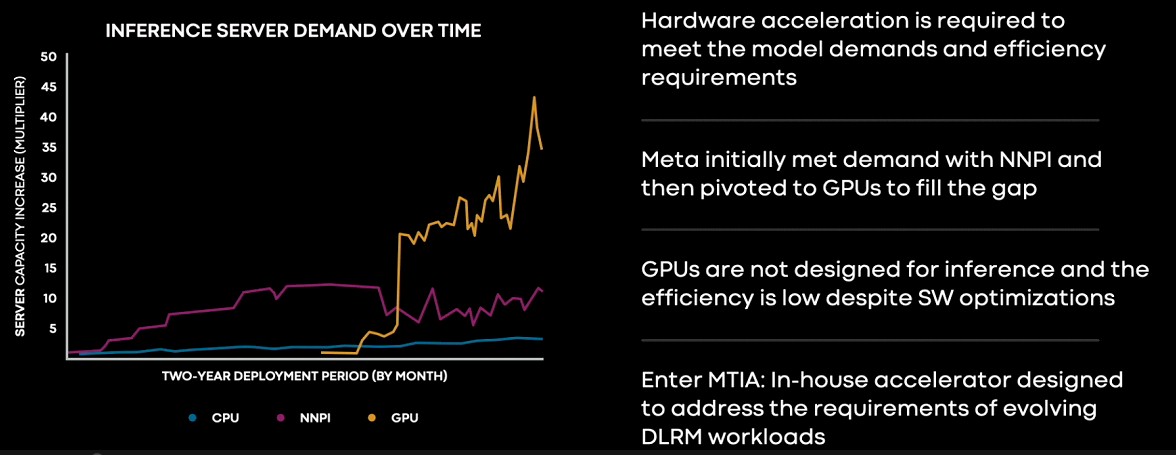
On the left side of the chart, Meta Platforms is replacing CPU-based inference with neural network processors for inference, or NNPIs, in the “Yosemite” microserver platforms we talked about way back in 2019. The CPU-based inferencing is still going on, you see, but as the DLRM models have gotten fatter, they busted out beyond the confines of the NNPIs, then Meta Platforms had to bring in GPUs to do inferencing. We presume that these were not the same GPUs that were used to do AI training, but PCI-Express cards like the T4 and A40 from Nvidia, but Coburn was not specific. And then that started getting more and more expensive as more inferencing capacity was required.
“You can see the requirements for inference quickly outpaced the NPI capabilities and Meta pivoted to GPUs because they provide a greater compute power to meet the growing demand,” Coburn explained in the MTIA launch presentation. “But it turns out that while GPUs provide a lot of memory bandwidth and compute throughput, they were not designed with inference in mind and their efficiency is low for real models despite significant software optimizations. And this makes them challenging and expensive to deploy and practice.”
We strongly suspect that Nvidia would argue that Meta Platforms was using the wrong device for DLRMs, or it might have explained how the “Grace” CPU and “Hopper” GPU hybrid would save the day. None of that appears to have mattered because Meta Platforms wants to control its own fate in silicon just as it did back in 2011 when it launched the Open Compute Project to open source server and datacenter designs.
Which begs the question: Will Facebook open source the RTL and design specs for the MTIA device?
Banking On RISC-V For MTIA
Facebook has historically been strong proponents of open source software and hardware, and it would have been a big surprise if Meta Platforms did not embrace a RISC-V architecture for the MTIA accelerator. It is, of course, based on a dual-core RISC-V processing element, wrapped with a whole bunch of stuff but not so much that it won’t fit into a 25 watt chip and a 35 watt dual M.2 peripheral card.
Here are the basic specs of the MTIA v1 chip:

Because it is low frequency, the MTIA v1 chip is also burning a fairly low amount of power, and being implemented in 7 nanometer processes means the chip is small enough to run pretty cool without being on the most advanced processes from Taiwan Semiconductor Manufacturing Co, ranging from 5 nanometers down to 3 nanometers with a 4 nanometer stepping stone in between. Those are more expensive processes, too, and perhaps something to be saved for a later day – and a later generation of device for training and inference separately or together as Google does with its TPUs – when these processes are more mature and consequently cheaper.
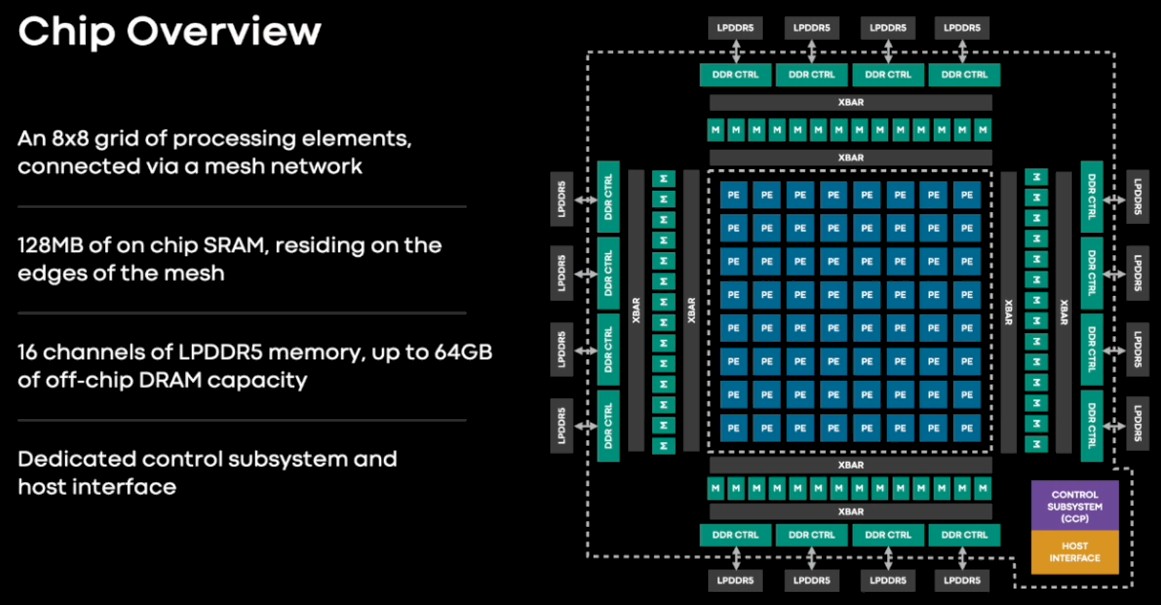
The MTIA v1 inference chip has a grid of 64 processing elements that have 128 MB of SRAM memory wrapped around them that can be used as primary storage or for cache memory that front ends sixteen low power DDR5 (LPDDR5) memory controllers. This LPDDR5 memory is used in laptops and is also being used in Nvidia’s impending Grace Arm server CPU. Those sixteen channels of LPDDR5 memory can provide up to 64 GB of external memory, suitable for holding those big fat embeddings that are necessary for DLRMs. (More on that in a moment.)
Those 64 processing elements are based on a pair of RISC-V cores, one plain vanilla and the other with vector math extensions. Each processing element has 128 KB of local memory and fixed function units to do FP16 and INT8 math, crank through non-linear functions, and move data.

Here is what the MTIA v1 board looks like:

There is no way that fan can be put atop the chip and have a dozen of these fit inside a Yosemite V3 server. Maybe that is just being shown for scale?
Here is the neat bit in the MTIA server design. There is a leaf/spine network of PCI-Express switches in the Yosemite server that not only lets the MTIAs connect to the host but also to each other and to the 96 GB of host DRAM that can store even larger embeddings if necessary. (Just like Nvidia is going to do with Grace-Hopper.) The whole shebang weighs in at 780 watts per system – or a bit more than the 700 watts a single Hopper SXM5 GPU comes in at when it is running full tilt boogie.
That Nvidia H100 can handle 2,000 teraops at INT8 precision within 700 watts for the device, but the Meta Platforms Yosemite inference platform can handle 1,230 teraops with 780 watts for the system. A DGX H100 is 10,200 watts with eight GPUs, and that is 16,000 teraops for 1.57 teraops per watt. The MTIA comes in at 1.58 teraops per watt, and is tuned to Meta Platform’s DLRM and PyTorch framework – and will be more highly tuned. We strongly suspect that a chassis of the MTIAs costs a lot less per unit of work than a DGX H100 system – or else Meta Platforms would not bring it up.
Raw feeds and speeds are not the best way to compare systems, of course. DLRMs have varying levels of complexity and model size, and not everything is good at everything. Here is how the DLRMs break down inside of Meta Platforms:
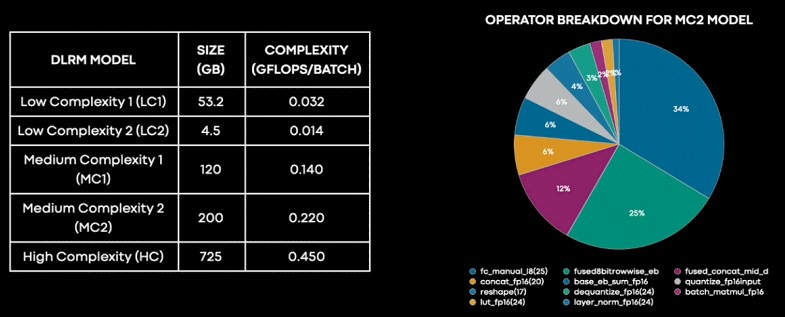
“We can see that the majority of the time is actually spent on fully connected layers, followed by embedded back layers, and then trailed by such longtail operations like concat, transpose, quantize, and dequantize, and others,” explained Roman Levenstein, engineering director at Meta Platforms. “The breakdown gives us also insight into where and how MTIA is more efficient. MTIA can reach up to two times better performance per watt on fully connected layers compared to GPUs.”
Here is how the performance per watt stacks up on low complexity, medium, and high complexity models:
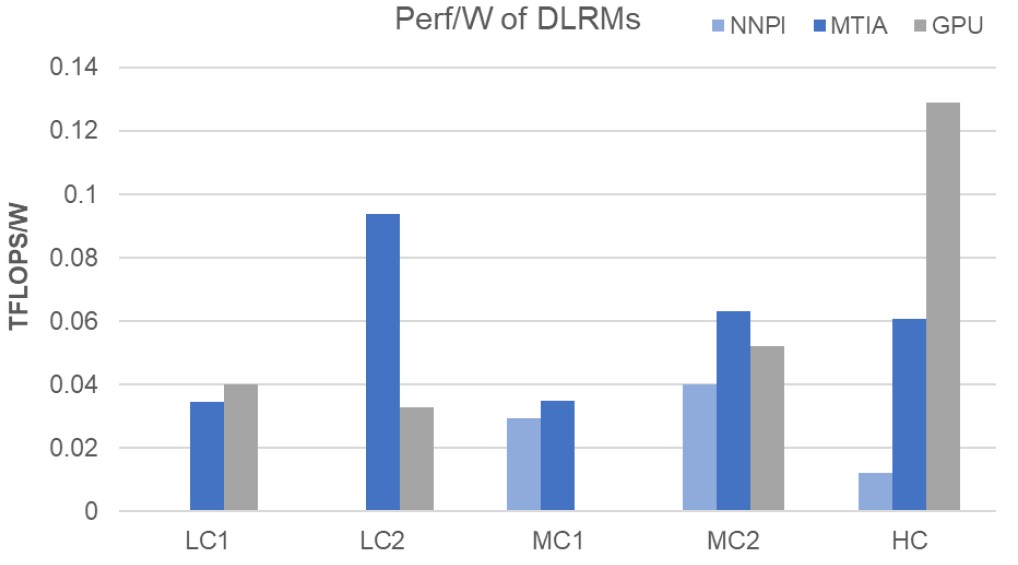
Levenstein cautioned that the MTIA device was not yet optimized for DLRM inference on models with high complexity.
We are going to try to find out which NNPIs and GPUs were tested here and do a little price/performance analysis. We will also contemplate how an AI training device could be crafted from this foundational chip. Stay tuned.