


Sponsored Feature: Training an AI model takes an enormous amount of compute capacity coupled with high bandwidth memory. Because the model training can be parallelized, with data chopped up into relatively small pieces and chewed on by high numbers of fairly modest floating point math units, a GPU was arguably the natural device on which the AI revolution could start.
While there are some custom ASICs that can do massive amounts of the required matrix math, with various kinds of SRAM or DRAM memory, the GPU is still the preferred AI training device. In part because GPUs are ubiquitous and their computational frameworks are well developed and easily accessible, there is no reason to doubt that for most companies (most of the time), the GPU will remain the compute engine of choice for AI training.
It doesn’t hurt that GPU acceleration has become common for HPC simulation and modeling workloads. Or that other workloads in the datacenter – virtual desktop infrastructure, data analytics and database management systems for example – can also be accelerated on exactly the same iron used to perform AI training.
But AI inference, where the relatively complex AI model is boiled down to a set of weights to make predictive calculations about new data that was not part of the original training set, is a different matter entirely. For very sound technical and economic reasons, in a lot of cases AI inference should remain – and will remain – on the same server CPUs where applications run today and are being augmented with AI algorithms.
It’s Hard To Beat Free AI Inference
There are a lot of arguments why inference should stay on the CPU and not move off to an accelerator inside the server chassis, or across the network into banks of GPU or custom ASICs running as inference accelerators.
First, external inference engines add complexity (there are more things to buy that can break) and potentially add security risks because there are more attack surfaces between the application and its inference engine. And no matter what, external inference engines add latency, and particularly for those workloads, running across the network, which many hyperscalers and cloud builders do.
Admittedly, with prior generations of server CPUs, the inference throughput using mixed precision integer or floating point data. Pushing them through integrated vector math units didn’t require much bandwidth, even though it may have been perfectly fine for the inference rates required by many applications. And hence, that is still why 70 percent of inference in the datacenter, including the hyperscalers and cloud builders as well as other kinds of enterprises, is still running on Intel Xeon CPUs. But for heavy inferencing jobs, the throughput of a server-class CPU could not compete with a GPU or custom ASIC.
Until now.
As we have previously discussed, with the “Sapphire Rapids” 4th Gen Intel® Xeon® processors, the Intel Advanced Matrix Extensions (AMX) matrix math accelerators within each “Golden Cove” core significantly increase the performance for the low precision math operations that underpin AI inference (read more about the accelerators built-into Intel’s latest Xeon CPUs here).
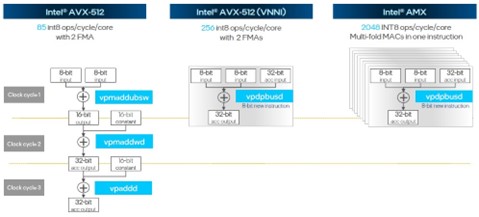
The AMX units can process 2,048 8-bit integer (INT8) operations per cycle per core. That’s 24X more throughput than the plain vanilla AVX-512 vector units used in the “Skylake” CPUs and 8X more on INT8 operations than the “Cascade Lake” and “Ice Lake” AVX-512 units that were augmented with much more efficient Vector Neural Network Instructions (VNNI). The Golden Cove cores support the use of both AVX-512 with VNNI and AMX units working concurrently, so that is 32X the INT8 throughput for inference workloads.
The trick with the AMX unit is that it is included in the Golden Cove core in each and every one of the 52 variations of the Sapphire Rapids CPUs in the SKU stack. Based on integer performance in those cores (and not including the AVX-512 and AMX performance), the price/performance of the Sapphire Rapids Xeons is the same or slightly better than for the prior generation of Xeon SP processors. Which is another way of saying that the AMX units are essentially free because they’re included in all of the CPUs and deliver additional performance with no incremental cost compared to Ice Lake. It is harder to get cheaper inference than free, particularly if the CPUs are necessary to running applications to begin with.
Stacking Up The Flops
Theoretical performance is one thing, but what matters is how actual AI inference applications can make use of the new AMX units in the Golden Cove cores.
Let’s take a longer view and look how inference performance has evolved since the “Broadwell” Xeon E7s in launched in June 2016 through the following four generations of Xeon SP processors. This particular chart shows the interplay of the throughput of the processors and the watts for each 1,000 images processed per second:
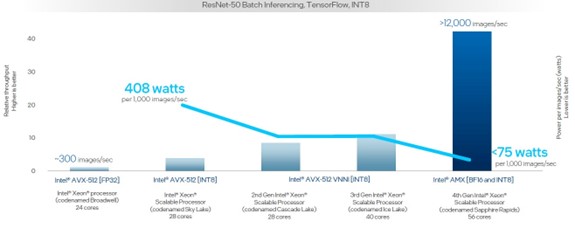
See [A17, A33] at https://edc.intel.com/content/www/us/en/products/performance/benchmarks/4th-generation-intel-xeon-scalable-processors/. Results may vary.
In this case, the tests that were run across the five generations of servers are doing image recognition using the ResNet-50 model atop the TensorFlow framework. Over the past nine years, the image processing throughput has increased from around 300 images per second to over 12,000 images per second, which is a more than 40X improvement.
And the heat generated for each 1,000 images per second processed has gone down even more than this chart shows. It would take three and a third 24-core Broadwell E7 processors at FP32 precision to hit a 1,000 images per second rate, and at 165 watts per chip that works out to 550 watts total allocated for this load. The Sapphire Rapids chips with the AMX units using a mix of BF16 and INT8 processing burn under 75 watts. So that is more than a factor of 7.3X better performance per watt in Sapphire Rapids compared to those previous five generations of Broadwell CPUs.
What about other workloads? Let’s take a look. This is how the 56-core Sapphire Rapids Xeon SP-8480+ CPUs running at 2GHz stack up against the prior generation 40-core Ice Lake Xeon SP-8380 CPUs running at 2.3GHz on image classification, natural language processing, image segmentation, transformer, and object detection models running atop the PyTorch framework:
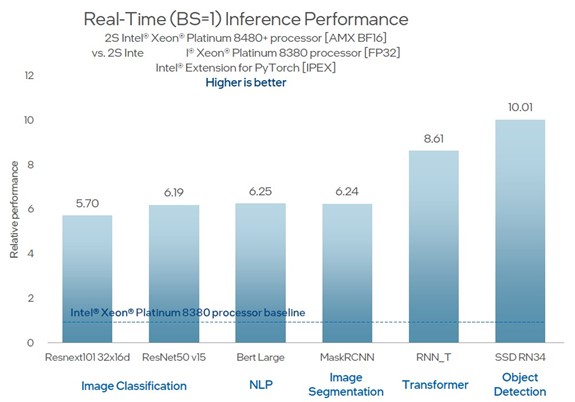
See [A17, A33] at https://edc.intel.com/content/www/us/en/products/performance/benchmarks/4th-generation-intel-xeon-scalable-processors/. Results may vary.
As the chart says, this is a comparison of doing FP32 processing on the AVX-512 units in the Ice Lake chip against doing BF16 processing on the AMX units. Just the halving of precision alone between the two platforms doubles the throughput between these two generations. The relative performance of these two chips (the compounding of the core counts and the clock speeds) yields another 21.7 percent more performance. The rest of the performance gains – which works out to 3.5X to 7.8X of the 5.7X to 10X shown above – come from using the AMX units.
Of course, the real test is how the inference oomph of the AMX units inherent in the Sapphire Rapids compare to using an outboard accelerator. So here’s how a two-socket server using the Xeon SP-8480+ processors stacks up compared to an Nvidia “Ampere” A10 GPU accelerator: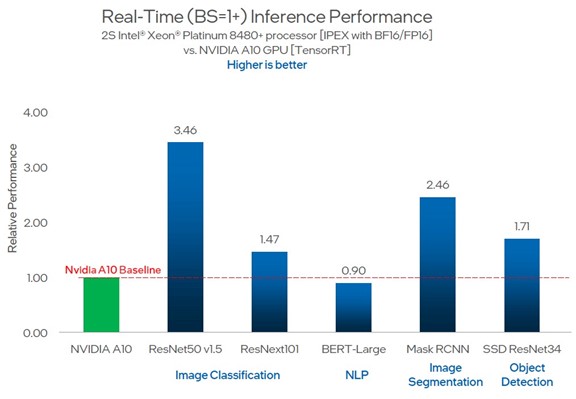
See [A218] at https://edc.intel.com/content/www/us/en/products/performance/benchmarks/4th-generation-intel-xeon-scalable-processors/. Results may vary.
The performance of the two Sapphire Rapids processors is 90 percent of the way to an A10 on natural language inference on a BERT-Large model, and beats the A10 by 1.5X to 3.5X on other workloads.
The A10 GPU accelerator probably costs in the order of $3,000 to $6,000 at this point, and is way out there either on the PCI-Express 4.0 bus or sitting even further away on the Ethernet or InfiniBand network in a dedicated inference server accessed over the network by a round trip from the application servers. And even if the new “Lovelace” L40 GPU accelerator from Nvidia can do a lot more work, the AMX units are built into the Sapphire Rapids CPUs by default and don’t need an add-on.
Sponsored by Intel.