



Sometimes, a startup takes such a new and profound approach to a problem that it is hard to know where to begin to describe how radical of a change that company has made in developing its product. So it is with Vast Data, a storage company based in New York that is uncloaking from stealth mode today with an exascale class non-volatile storage clustering hardware and software that it claims can finally and forcefully make the disk drive extinct in the datacenter by using a clever mix of cheap QLC flash, 3D XPoint storage class memory, NVM-Express over Fabrics interconnects, and very clever software and algorithms.
Vast Data was founded back in early 2016 by Renen Hallak, the company’s chief executive officer, Shachar Fienblit, vice president of research and development, and Jeff Denworth, vice president of products. Hallak was formerly vice president of research and development at XtremIO, one of the hottest enterprise all flash array startups of the first wave of flash to enter the datacenter and a company that was acquired by EMC in May 2012 for $430 million as its product was still in development and an impending threat to other EMC disk and flash arrays. Fienblit was chief technology officer at Kaminario, which carved out a niche a few years earlier as a provider of very high performance all flash arrays. Denworth was in charge of product management at DataDirect Networks, a maker of parallel file systems aimed mostly at the HPC and media and entertainment sectors and a company that has also carved out a healthy niche for itself in a very competitive market. Other early employees of Vast Data hail from Isilon Systems, NetApp, Pure Storage, IBM, Cisco Systems, MapR Technologies, Google, and Amazon Web Services and, as you might expect, they have deep experience with flash media and scalable storage architectures.
Perhaps equally significant to this bench of technical expertise is the backing that Vast Data has attained from investors and early adopters. Vast Data has raised $80 million in two rounds of funding, with its Series B round announced today being led by TPG, a company that usually only makes late stage investments when it knows the company has a high chance of success; Goldman Sachs, Dell Technologies, Norwest Venture Partners, and 83North have also kicked in the funds to get Vast Data going.
“We have created a new type of storage architecture that breaks a whole slew of tradeoffs that existed in the storage industry for the past few decades,” says Denworth, throwing down the gauntlet to all of the other makers of all flash arrays aimed at the datacenter. “We have engineered a system that combines the performance of flash with the economics that people only would have ever expected to get from hard disks in a very scalable system architecture that’s essentially an exabyte-scale parallel file system. And we believe companies can use it for all of their applications, ranging from enterprise business applications to supercomputing to artificial intelligence to backup and more.”
Vast Data has had products in field trials since the end of 2017 and quietly launched Version 1.0 of its product back in November 2018, with General Dynamics, Ginko Bioworks, and Zebra Medical Vision being its first marquee customers. Denworth says that it has sold petabytes of capacity already and that it has multiple customers placing orders for multiple petabytes of capacity right out of the gate, and that gauged against some of the other historically fast growing infrastructure companies – NetApp network attached storage, Cisco Systems UCS blade servers, Nutanix hyperconverged storage, Pure Storage all flash arrays come to mind, but there are others – Vast Data has booked more revenue in its first 90 days of doing business than they did.
It is an impressive start, and to get one like that means that Vast Data is on to something, that it is brining the right mix of hardware and software to tackle a big problem and customers are responding to it.
Hallak tells The Next Platform that there was a certain amount of skepticism about what Vast Data was going to try to do, right from the beginning, which is also often a good sign when a company sets out to shake things up. And it is best at this point to let Hallak tell the story:
We are all about breaking tradeoffs and a lot of the legacy constraints and tradeoffs that existed over the last twenty years. In fact, when we set out to build a scale out file system and object store, everyone said: “You’re crazy. Everything you know from the block world is not relevant. This takes seven to eight years to build it right. And there is simply no way to do it faster than that.” And we didn’t listen to them. We did not talk to the people that had a lot of experience in file systems, although we had a couple on our team. But most of our team did not. And what we did was we looked at the new landscape that included very low cost flash, a new technology called NVM-Express over Fabrics, and a revolutionary storage class memory called 3D XPoint. This landscape was off in the future when we started at the beginning of 2016. These things did not exist but we saw them on the horizon and we designed a system as if they did exist. The end result was that most of the complications, most of the tradeoffs, that come with building a scale out filesystem do not exist when you build it on top of these mechanisms. They do not exist when you build it using our architecture. They do not exist when you build it in the way that we have with our metadata structures. And so we have the advantage of not having all of this baggage both from a legacy code perspective and from a mindset perspective. And after about a year, when we came out with our alpha product, I went back to those people we initially talked to and I asked them why did they say it would take seven or eight years? And they said because of locking, which is a complicated problem to solve, and because of small files, which is also complicated problem to solve because of metadata operations, because of large directories and large files that need to span the cluster. All of these things get solved inherently by our architecture in a much simpler way. And so we can break these tradeoffs, usually not by writing a lot of code but also by not needing to deal with the old problems.
The first major break that Vast Data did with storage cluster convention is to do away with the direct attached, shared nothing architecture, which is where storage hangs off of or is embedded in a controller that can see maybe dozens of devices. In the shared nothing architecture, each node is responsible for its part of the file system namespace – the list of where things are located. Vast Data’s Universal Storage has what Hallak calls a deep flash cluster architecture, and what is meant by that is that the physical storage is disaggregated and linked across the NVM-Express over Fabrics interconnect rather than directly attached to a storage cluster node, and the namespace, as controlled by metadata servers, is shared everything and completely separated in a higher tier away from the storage devices themselves. Like this:

Importantly, the compute dedicated to the control plane of the Universal Storage cluster can scale completely independently of the storage below it out on the NVM-Express over Fabrics interconnect. This kind of disaggregation is not new. Hyperscalers such as Google, Facebook, and Amazon Web Services have created vast arrays of disk and flash and linked them to compute over giant Clos networks spanning a 100,000 devices in an entire datacenter for a decade now. And Hallak gives them a tip of the hat for breaking new ground, and breaking up storage to create disaggregated architectures, but says that Vast Data has done a bunch of things a decade later that they could not do then because QLC flash, 3D XPoint, and NVM-Express over Fabrics did not exist back then.
“We are inspired by them, but I think we get not only to the next level, but four levels higher,” boasts Hallak. “I think their disaggregation was based on technologies that were available when they did it, and that worked to a certain extent, but we can do disaggregation without compromising performance. Specifically, NVM-Express over Fabrics and 3D XPoint enable us to disaggregate while still getting the same level of performance that you would get from a direct attached SSD. So I think we are taking it further than they have. We have definitely been inspired by those hyperscale architectures, but we are trying to bring that to the masses, not have it in the hands of just a few companies.”

In looking at those block diagrams of the Universal Storage cluster above, there are a couple of things to note. The bottom layer is called an HA enclosure by Vast Data, short for high availability presumably, and as the name and the diagram suggests, it is a JBOF that includes SSDs crammed with the new QLC flash, some 3D XPoint SSDs, and four NVM-Express over Fabrics ports that can be implemented atop 100 Gb/sec Ethernet or 100 Gb/sec InfiniBand, you choose. The architecture is to not only disaggregate compute from capacity, but to disaggregate logic from state in the storage cluster. To reach exabyte scale, you have to cluster up about 1,000 of these HA enclosures on an NVM-Express fabric. To actually control access to that capacity, you fire up nodes in what Vast Data calls the container layer, which creates the global namespace in Docker containers and which also shares data between container nodes over its own 50 Gb/sec Ethernet fabric.

The upshot is that the storage tier, which yields about 2 PB of usable capacity when data reduction techniques are used, is completely stateful, and all data is persistent because it is written down to 3D XPoint first and then, after a lot of complicated math and machinations, is shifted off to the QLC flash. The control plane that provides access to the data is stateless, ephemeral, and dynamically scalable such that as you put I/O demands on the system from applications, you can just scale up the compute in this container tier and rebalance the cluster to handle the job.
Vast Data is bringing its Universal Storage to market in three different ways. You can buy the HA enclosures for the storage and the server appliances running the containers from Vast Data, loaded up with its software and ready to go; you can just buy the HA enclosures for the storage and run the containers on the hardware of your choice; or you can build your own HA enclosures and container servers and just buy the Universal Storage software.
One of the secret sauces of the Vast Data storage is its shared everything namespace and the distributed namespace that implements it in those Docker containers. “Our metadata is structured in a way that it looks the same regardless of the directory restructure, the file sizes, and basically anything that the user can do. If you have a trillion tiny files or a 100 PB file, our metadata structure always looks the same, which is a wide, fan out tree which limits the number of accesses that we need to a constant. We can have a constant, and not just one or two, because storage class memory is so fast and the majority of the metadata will reside in the lower levels of the tree such that we can play with how many flash accesses we really need. In most cases we won’t need any flash accesses for metadata operations.”
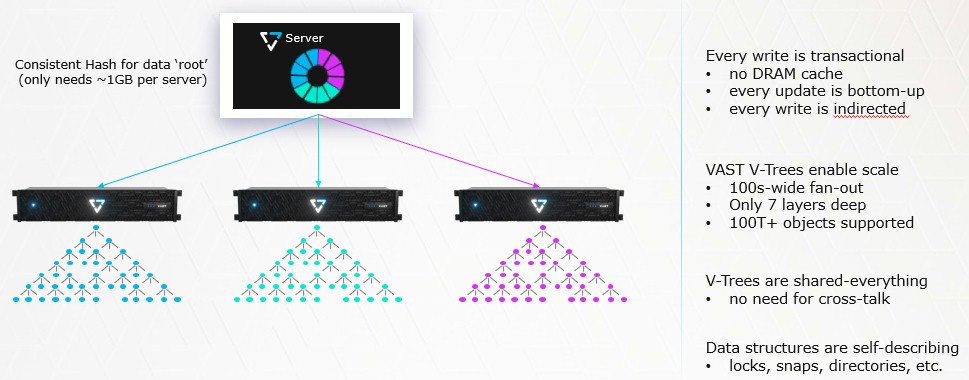
This distributed metadata is the key to scaling out the storage and providing the shared everything architecture that lets this scale happen directly, without having to cache any data in DRAM in a controller somewhere. It only takes seven layers of metadata trees to reach exabytes of persistent 3D XPoint and QLC flash storage.
“Storage class memory is used for two things,” Hallak explains. “It’s not an internal tier within the system. We are against tiers. That is our religion. We do not believe in tiering. We use storage class memory internally as a metadata store that enables all of the rich functionality that we provide and as a write buffer in order to overcome a lot of the deficiency of low cost flash as well as a way for us to have time – have compute time – to do more advanced processing of data after we have acknowledged writes to the application.”
The protocol layer, which rides atop this metadata, currently consists of NFS v3 file system and S3 object storage protocol access to data, and these rides atop a data store that implements superset of object, block, and file storage such that Vast Data can expose data in the store in any protocol that customers need in the future. Hallak says that the SMB block access commonly used with Microsoft’s Windows Server is probably the next protocol that it will implement, and that it probably will not do the HDFS file system that underpins Hadoop.
“The key takeaway for the protocols is that we will add what customers ask us to,” says Hallak. “But the more interesting point is that the different protocols also stem from these historic storage tradeoffs. The reason you have a block interface is because it’s faster than anything else. The reason you have a file interface is because it’s more convenient. The reason you have objects is because it’s more scalable than what file and block can give. If we can in the same system provide you performance of block at the scale of objects, then the convenience of file is basically all you’ll ever want to use. We’re not saying to customers they have to change their applications. We will deliver the protocols that they want. But customers that are looking to change their applications because they hit a scale limit or that they had a performance limit don’t need to do so.”
So the number of storage access protocols that future applications will need might be smaller than we might think. These are native protocols, not gateway layers that run atop protocols, and the internal structure of the file system is called an element store, which provides the internal abstraction that gets expressed as a file, an object, a directory, an S3 bucket, and maybe even a volume when Vast Data exposes that SMB block interface.
Vast Data has created a set of data reduction and wear leveling techniques for flash that warrant much deeper analysis, but suffice it to say on announcement day that the toughest thing that Vast Data had to tackle was creating these techniques that can bring the cost of flash down to that of disk drives. Having accomplished this, Hallak says that Vast Data can deliver an all flash clustered storage system that is “orders of magnitude lower cost than any other flash system out there, and it is orders of magnitude higher performance than any other hard drive based system out there.”
We will also be exploring this in a future story. Stay tuned.