


Server processor architectures are trying to break the ties between memory and compute to allow the capacities of each to scale independently of each other, but switching and routing giant Cisco Systems has already done this for a high-end switch chip that looks remarkably like a CPU tuned for network processing.
At the recent Hot Chips conference in Silicon Valley, Jamie Markevitch, a principal engineer at Cisco showed off the guts of an unnamed but currently shipping network processor, something that happens very rarely in the switching and routing racket. With the exception of the upstarts like Barefoot Networks with its Tofino chip, Innovium with its Teralynx, and Mellanox Technologies with its Spectrum-2, it is very rare to get details about the innards of a switch chip in a block diagram, and even rarer still to get die shots. Markevitch did not show up with die shots on the high-end, 6.5 Tb/sec switch and router chip, but he did get into the feeds and speeds and architecture of a 400 Gb/sec multi-core network processor, which is interesting in its own right and because it shows a kind of convergence between CPUs and NPUs.
By the way, this is not the CloudScale ASIC that Cisco launched in March 2016 that is deployed in the high-end Nexus 9500 core switches, which is implemented in 16 nanometer processes and that adheres to the 25G Ethernet standard promoted by Google and Microsoft. This particular NPU was implemented in earlier, but still pretty good, 22 nanometer processes and packs plenty of oomph just the same, and it is very likely the architectural foundation on which the CloudScale ASICs was built. This revealed ASIC was designed not for fixed port switches, but for modular devices that glue together multiple NPUs into a device with a single management domain (akin to NUMA clustering with CPUs, but not quite) across an internal fabric, and as such, the fabric interconnect that lashes them together is just as important as the circuits that present ports to the outside world. It looks very much like the NPU used in the first generation of Nexus 9000 core switches, in fact, but one that was shrunk down from 28 nanometers to 22 nanometers with the expected tweaks to the architecture for certain parts of the die and then left at 28 nanometers for other parts.
While Intel has been talking about hybrid chips that mix and match components for some time, Cisco has actually done this in a production chip, and apparently did it several years ago. The processor complex on this unnamed NPU has 672 processors, each with four threads per core. Here’s the basic block diagram:
This Cisco NPU has 9.2 billion transistors in total, which encompasses those cores and their 353 Mb of SRAM memory on those cores, which is implemented as L0 data and instruction cache for each thread (not core) as well as L1 instruction and data caches (for a cluster of sixteen cores). The cores have an eight stage, non-stalling pipeline, and there is a round robin algorithm to switch between threads on a cycle by cycle basis. The NPU has 42 of these processor clusters, which then link out to a four-way set associative L2 instruction cache that also has an on-chip interconnect that links the clusters and caches to each other as well as packet storage, accelerators, on-chip memories, and DRAM controllers together. This interconnect runs at 1 GHz and has more than 9 Tb/sec of aggregate bandwidth.
The processor complex is implemented in 22 nanometer processes and has 276 SERDES circuits for communication to the outside world. Some of those transistors are also used to implement various kinds of accelerators as well as buffers, MACs, and interface controllers.
Cisco did not say what instruction set this NPU supports, but it could be anything and is very likely a custom ISA aimed at networking and not an ARM, MIPS, Power, or X86 instruction set. These cores have what Markevitch called a “run to completion” model, which means a single thread on the processor complex owns a packet throughout its life in the chip, so there is no stalling or handing off of packet processor across threads. Because different packets require different features, either on the cores or on the accelerator complex, and have different sizes, the performance of the packet processing is not identical. This is in contrast to other NPU architectures, which have feature-pipelined architectures or are systolic arrays of cores connected by mesh networks. The interesting bit here is that this Cisco NPU supports a traditional software stack and is programmable in either assembly language or C, and every packet is stored, not just its headers that tell about what is in the packet and is used for control. This allows for more complex kinds of processing on a packet that is, however briefly, at rest instead of in flight; each packet is assigned a thread, and that means this NPU can chew on 2,688 packets at a time. The packets are stored off chip in the DRAM as they are being processed through the SRAM in real time, so accelerators can work on the DRAM copy while the cores are chewing on the “real” SRAM original.
This network processor is capable of 800 Gb/sec packet processing – that’s 400 Gb/sec at full duplex. The SERDES that wrap around the processor logic have an aggregate of 6.5 Tb/sec of I/O bandwidth, and as you might expect, a lot of that is used to link to DRAM memory used for buffering and Ternary Content Addressable Memory, or TCAM, a special kind of high speed and very expensive memory that is somewhere between SRAM and DRAM in speed and that is used typically to store access control lists (ACLs) in the control plane and is in this case is used to store large data structures of many types. That DRAM is also used for storing such structures when the TCAM runs out of space in addition to being used for packet buffering. Deep and wide buffers are important in high speed switches and routers, just like wide and deep L1, L2, and L3 caches are important for CPUs because both are, these days, throughout engines that need to have many cores and threads kept well fed. Most of the logic in this processor complex is running at 760 MHz or 1 GHz, which is not a barnburner speed for a CPU. The MACs can support ports running at anywhere from 10 Gb/sec to 100 Gb/sec.
“The chip is almost complete surrounded by SERDES,” Markevitch explained. “There is a little bit of test and debug, but all of the connection out to memories and everything else is via these SERDES.” He adds that about a quarter of the SERDES bandwidth is used for packets coming in and going out of the chip, and the other three quarters of the SERDES bandwidth is for talking to the DRAM and TCAM memory. The processor array is somewhere between a quarter and a third of the overall NPU die, Markevitch estimated, and the cores were placed by hand; other components were then done automagically using tools.
This Cisco NPU has an integrated traffic manager that is capable of managing 256,000 queues at a time and that can juggle the state of up to a half trillion objects per second (mostly packets, but sometimes structures inside the switch) to meet quality of service agreements in the network. Both the traffic manager and the processor complex have direct access to that DRAM to host their data as they do their work. The accelerators speed up special functions, such as IPv4 and IPv6 prefix look ups, IP range compressions and hashing, packet ordering, and statistics counters and rate monitors for QoS functions.
While the processing complex in this Cisco NPU is interesting, the serial-attached memory, which is external to the cores, is what is neat.
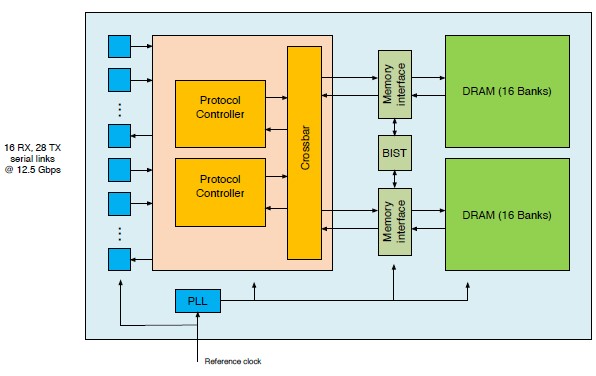
The outboard DRAM memory has 28 SERDES links running at 12.5 Gb/sec speeds, which is half the rate of the current 25 Gb/sec lanes that are being used for PCI-Express 4.0, NVLink 2.0, OpenCAPI 1.0, and other interconnection links in modern processors as well as the half the lane speed of the 25G Ethernet standard. The SERDES use a proprietary serial protocol for memory accesses that is optimized for networking and that is capable of processing more than 1 billion random accesses per second and supporting more than 300 Gb/sec data transfer rates (about 37.5 GB/sec). That’s not too shabby for a mere two memory controllers. Modern CPUs have more memory bandwidth by having more controllers running at higher speeds, and GPUs do it by having very wide memory accesses and also high speeds. It takes hundreds of nanoseconds to access that DRAM over the SERDES, which is definitely not as fast as DDR4 memory on a CPU, which is an order of magnitude faster.
Here is what the Cisco NPU package looks like:

There is a parallel I/O interface between the logic die and the DRAM die that runs at 0.85 volts at 1,250 Mb/sec speeds. The SERDES, protocol controller, and built-in self test (BIST) unit of this memory subsystem are implemented in 28 nanometer processes, the DRAM is implemented in 30 nanometer processes, and the processor complex is implemented in 22 nanometers, all mixed on the same package.
“We looked at what types of transactions that we really do, and we optimized for high random access rates,” said Markevitch. “You can either use this device like a pure packet buffer, where the number of reads is approximately equal to the number of writes – and I say approximately because there are multicast operations, or table lookups where you don’t tend to update them very often – maybe you update them a hundred thousand times a second but you read them at hundreds of millions of times a second. We designed this chip so it could be used in either type of application.”