



Custom accelerators for neural network training have garnered plenty of attention in the last couple of years, but without significant software footwork, many are still difficult to program and could leave efficiencies on the table. This can be addressed through various model optimizations, but as some argue, the efficiency and utilization gaps can also be addressed with a tailored compiler.
Eugenio Culurciello, an electrical engineer at Purdue University, argues that getting full computational efficiency out of custom deep learning accelerators is difficult. This prompted his team at Purdue to build an FPGA based accelerator that could be agnostic to CNN workloads and could eke maximum utilization and efficiencies on a range of deep learning tasks, including ResNet and AlexNet.
Snowflake is a scalable and programmable, low-power accelerator for deep learning with a RISC based custom instruction set. It implements a control pipeline for a custom instruction set via a custom compiler that generates instructions and handles data in main memory. The software structure drills into the high level model representation from Torch7, which feeds into an instruction stream that runs on Snowflake. The Snowball software framework provides hardware usability and utilization.
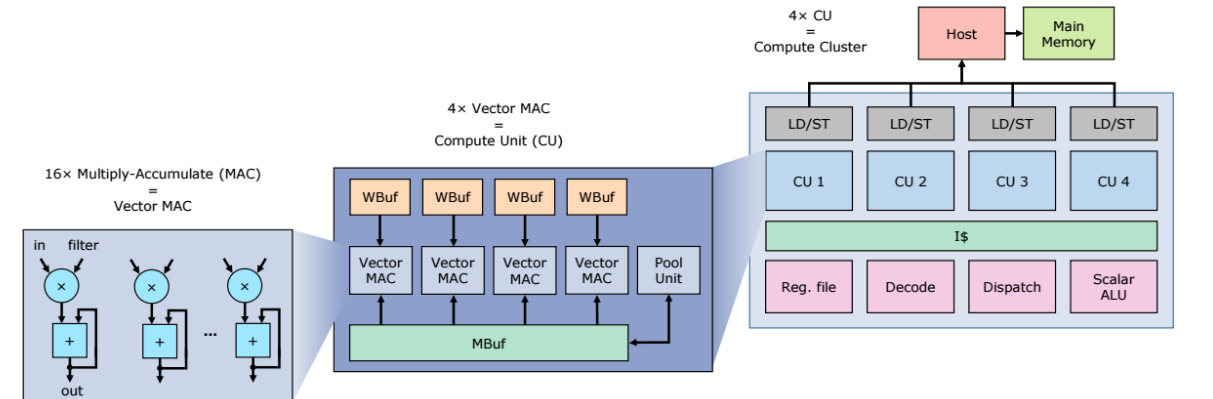
“The architecture was designed to provide high performance given optimal sequence of instructions. But, manually crafting assembly-like instructions can be cumbersome and error prone, especially when a model is comprised of several layers like in ResNet,” the creators explain. “Even if one was patient enough to manually write code for some state of the art deep learning models, further customization on both sides: the hardware and software would require modifying thousands of lines of assembly code, preventing experimentation on custom systems for deep learning.”
“Snowflake is able to achieve a computational efficiency of over 91% on entire modern CNN models, and 99% on some individual layers,” Culurciello says. “Implemented on a Xilinx Zynq XC7Z045 SoC is capable of achieving a peak throughput of 128 G-ops/s and a measured throughput of 100 frames per second and 120 G- ops/s on the AlexNet CNN model, 36 frames per second and 116 G-ops/s on the GoogLeNet CNN model and 17 frames per second and 122G-ops/s on the ResNet-50 CNN model. To the best of our knowledge, Snowflake is the only implemented system capable of achieving over 91% efficiency on modern CNNs and the only implemented system with GoogLeNet and ResNet as part of the benchmark suite.”
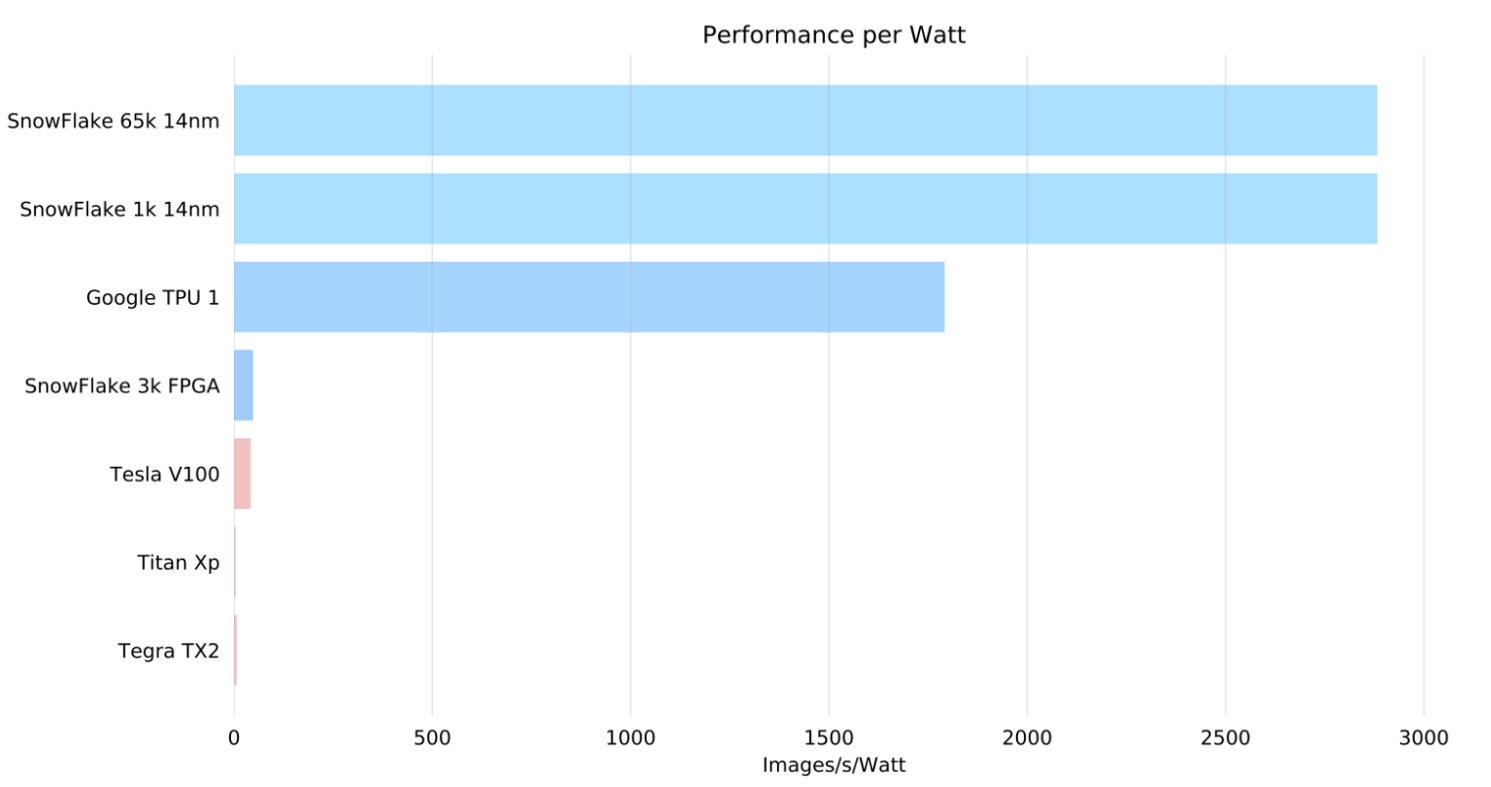
Culurciello concludes that Snowflake and the Snowball framework address some of the key software design points that lead many hardware accelerators to leave efficiency gaps. These include model structure parsing, workload breakdown, loop rearrangement, and memory access balancing. These have been tested out with positive results on their own Snowflake accelerator, but the team is confident these can apply to other custom accelerators. An in depth description of both the Snowflake architecture and Snowball software framework can be found here.
The technical issues with custom accelerators represent one challenge; the other, larger issue on the horizon is how much traction these custom chips will get as larger companies work to integrate valuable features for deep learning frameworks on standard chips (as Intel is doing with its Knights family of processors, for instance). With wider-ranging deep learning features in familiar software environments, the need and use for custom accelerators for these workloads might begin to disappear. However, work to make FPGAs move closer to that starting line is interesting in that it adds to the architectural mix.
Note about comparisons used the highest available performance numbers and lowest power numbers from these sources:
Google TPU: https://arxiv.org/abs/1704.04760
For NVIDIA V100 used: https://www.nvidia.com/en-us/data-center/tesla-v100/, power 300W, Deep Learning performance: 120 Tflops
For NVIDIA Titan Xp: https://www.nvidia.com/en-us/geforce/products/10series/titan-xp/, power 250 W, single precision FP32 performance: 12.1 Tflops — FP16 performs worse than FP32 so have not used it
For NVIDIA Tegra X2: https://en.wikipedia.org/wiki/Tegra#Tegra_X2, power: 7.5 W, performance: 1.5 Tflops