

Custom accelerators for neural network training have garnered plenty of attention in the last couple of years, but without significant software footwork, many are still difficult to program and could leave efficiencies on the table. This can be addressed through various model optimizations, but as some argue, the efficiency and utilization gaps can also be addressed with a tailored compiler.
Eugenio Culurciello, an electrical engineer at Purdue University, argues that getting full computational efficiency out of custom deep learning accelerators is difficult. This prompted his team at Purdue to build an FPGA based accelerator that could be agnostic to CNN workloads and could eke maximum utilization and efficiencies on a range of deep learning tasks, including ResNet and AlexNet.
Snowflake is a scalable and programmable, low-power accelerator for deep learning with a RISC based custom instruction set. It implements a control pipeline for a custom instruction set via a custom compiler that generates instructions and handles data in main memory. The software structure drills into the high level model representation from Torch7, which feeds into an instruction stream that runs on Snowflake. The Snowball software framework provides hardware usability and utilization.
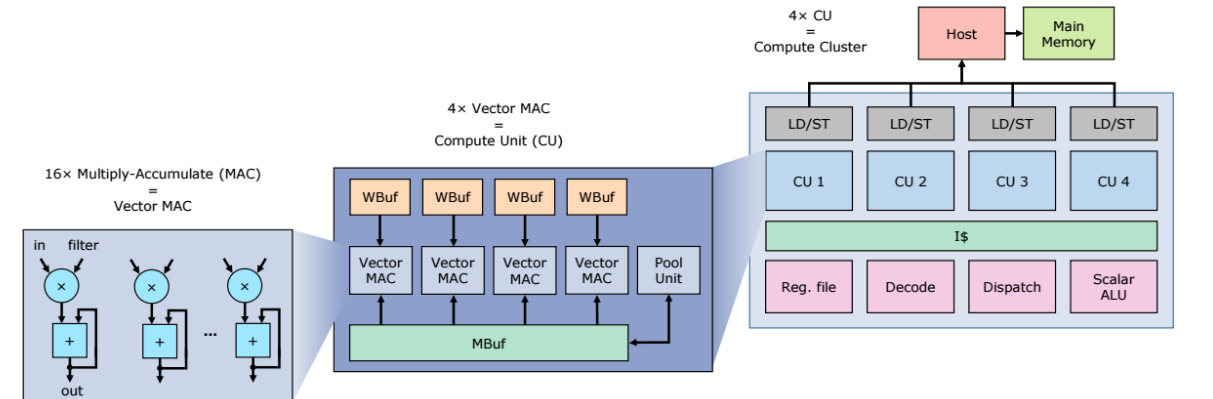
“The architecture was designed to provide high performance given optimal sequence of instructions. But, manually crafting assembly-like instructions can be cumbersome and error prone, especially when a model is comprised of several layers like in ResNet,” the creators explain. “Even if one was patient enough to manually write code for some state of the art deep learning models, further customization on both sides: the hardware and software would require modifying thousands of lines of assembly code, preventing experimentation on custom systems for deep learning.”
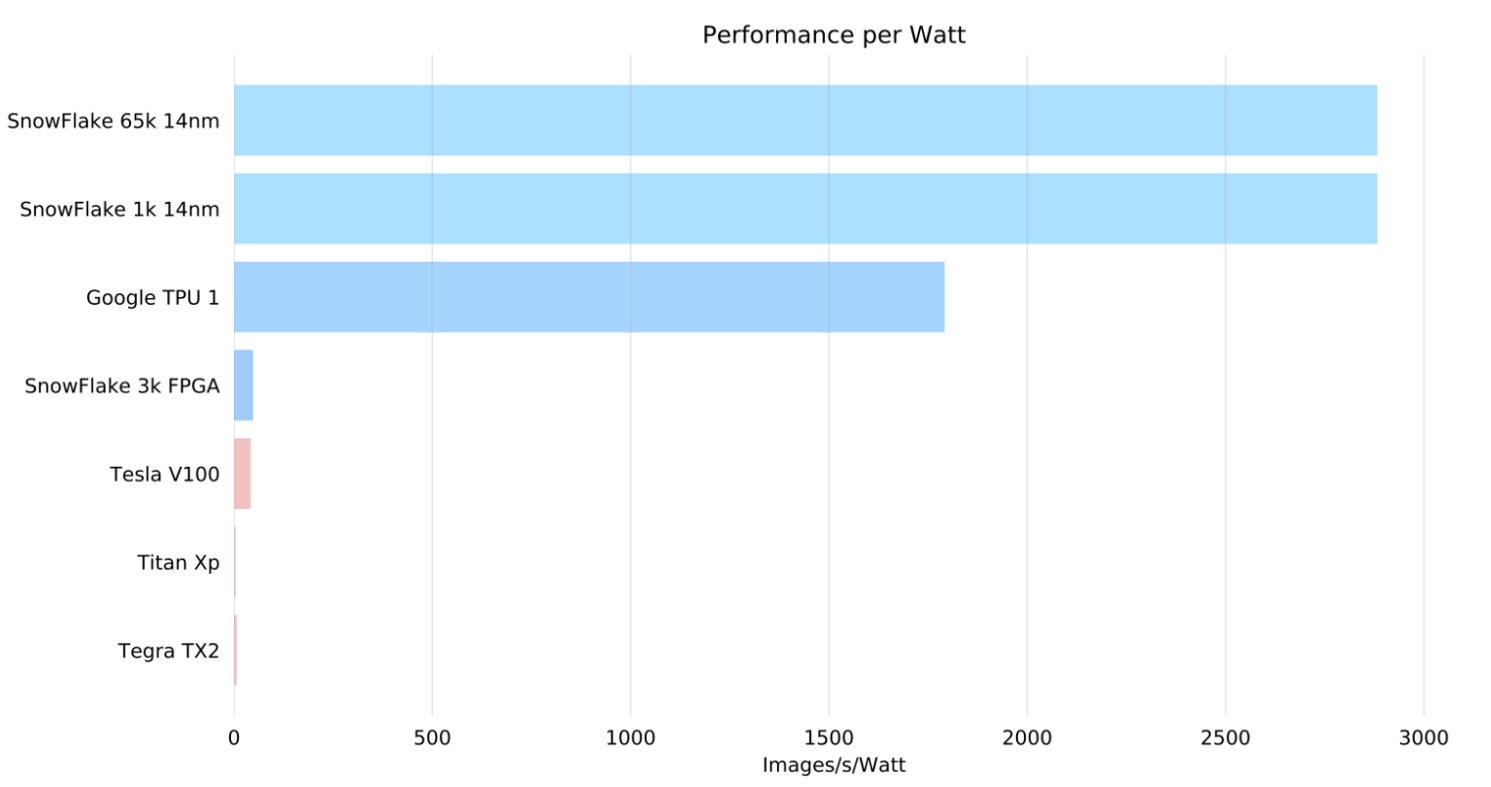
“Snowflake is able to achieve a computational efficiency of over 91% on entire modern CNN models, and 99% on some individual layers,” Culurciello says. “Implemented on a Xilinx Zynq XC7Z045 SoC is capable of achieving a peak throughput of 128 G-ops/s and a measured throughput of 100 frames per second and 120 G- ops/s on the AlexNet CNN model, 36 frames per second and 116 G-ops/s on the GoogLeNet CNN model and 17 frames per second and 122G-ops/s on the ResNet-50 CNN model. To the best of our knowledge, Snowflake is the only implemented system capable of achieving over 91% efficiency on modern CNNs and the only implemented system with GoogLeNet and ResNet as part of the benchmark suite.”
Culurciello concludes that Snowflake and the Snowball framework address some of the key software design points that lead many hardware accelerators to leave efficiency gaps. These include model structure parsing, workload breakdown, loop rearrangement, and memory access balancing. These have been tested out with positive results on their own Snowflake accelerator, but the team is confident these can apply to other custom accelerators. An in depth description of both the Snowflake architecture and Snowball software framework can be found here.
The technical issues with custom accelerators represent one challenge; the other, larger issue on the horizon is how much traction these custom chips will get as larger companies work to integrate valuable features for deep learning frameworks on standard chips (as Intel is doing with its Knights family of processors, for instance). With wider-ranging deep learning features in familiar software environments, the need and use for custom accelerators for these workloads might begin to disappear. However, work to make FPGAs move closer to that starting line is interesting in that it adds to the architectural mix.
Note about comparisons used the highest available performance numbers and lowest power numbers from these sources:
Google TPU: https://arxiv.org/abs/1704.04760
For NVIDIA V100 used: https://www.nvidia.com/en-us/data-center/tesla-v100/, power 300W, Deep Learning performance: 120 Tflops
For NVIDIA Titan Xp: https://www.nvidia.com/en-us/geforce/products/10series/titan-xp/, power 250 W, single precision FP32 performance: 12.1 Tflops — FP16 performs worse than FP32 so have not used it
For NVIDIA Tegra X2: https://en.wikipedia.org/wiki/Tegra#Tegra_X2, power: 7.5 W, performance: 1.5 Tflops


The Year Ahead In Datacenter Compute
For more than a decade, the pace of the server market was set by the rollout of Intel’s Xeon processors each year. To be sure, Intel did not always roll out new chips like clockwork, on a predictable and more or less annual cadence as the big datacenter operators like. …

How The FPGA Can Take On CPU And NPU Engines And Win
We made a joke – sort of – many years ago when we started this publication that the future compute engines would look more like a GPU card than they did a server as we knew it back then. And one of the central tenets of that belief is that, …

The Fourth Wave Of FPGA Compute
Ahead of The Next FPGA Platform event that we hosted recently in San Jose, we talked to Manoj Roge, vice president of product planning and business development at Achronix, about the three waves of FPGAs that have occurred over the past three decades, and in the course of our live …
There is huge market here for custom accelerators for this. In the automotive market especially if we are transitioning away from internal combustion engine to electric at the same time. A 100W compute board like Tegra X1 is not going to fly as it will limit seriously your range.
Also IoT edge devices where currently any nVidia solution is like 100-1000 to power hungry.
The tegra X1 pulls around 10 watt in high loads, if you really stress all the components itll do around 15 watts.
The tegra x2 runs at 7.5 watt peak at similar loads.
I don’t think he meant to be discussing the Tegra X1. I think he meant the full Drive PX2 system (which incidentally uses a Tegra X2 SoC not a Tegra X1) with the discrete GPUs. I’m not sure how he got from 100 watts to 1000 watts though.
That Drive PX2 system, however, is a development platform. It is to be replaced in production cars with the 20 W to 30 W Xavier. If an electric car has a 75 kWh battery then it would take about 104 days of continuous (24 hours a day) usage to run it down using only the 30 W Xavier. The Tesla Model 3 uses about 24,000 Wh for every 100 miles driven. During that time the Xavier will generally have used under 100 Wh, or less than one half of one percent of the energy. I don’t think that’s much of a concern.
Once the OpenCL to FPGA compilers begin to approach even 40% of the sophistication of the current compiler state of the art (it’s really just a matter of putting the effort in, and maybe a but of creativity;), the solution they produce to the multiobjective constrained optimization problem of mapping a skilled and aware programmer’s opencl to the hardware should improve rapidly.
We’ll know we’ve arrived when we can smash out code that looks like a (skilled and aware!) python one-liner that’s using zeromq, which instantiates some arbitrary network of kernels communicating asynchronously over infra and intER device pipes, and finishing in an hour or few our previous 72 hour runtime stochastic global nonconvex nonlinear constrained optim problem with ad-box ever changing by the day spaghetti-code objective function, which is run weekly now cuz it’s a fire hazard to bystanders, but which nevertheless brings home the bacon.