



Over the last year, we have focused on the role burst buffer technology might play in bolstering the I/O capabilities on some of the world’s largest machines and have focused on use cases ranging from the initial target to more application-centric goals.
As we have described in discussions with the initial creator of the concept, Los Alamos National Lab’s, Gary Grider, the starting point for the technology was for moving the checkpoint and restart capabilities forward faster (detailed description of how this works here). However, as the concept developed over the years, some large supercomputing sites, including the National Energy Research Scientific Computing Center (NERSC), have added burst buffer capabilities and are using them to boost application performance as well as for speeding up checkpointing.
To be clear on our title, there are already burst buffers in use, but this marks the first time a burst buffer has been used at scale beyond a checkpoint and restart use case or benchmarks. The first users of the burst buffer on the 1,630 node Cori machine are using the burst buffer for application performance—something that has been highlighted in this detailed paper, which won an award for best paper at last week’s Cray User Group meeting.
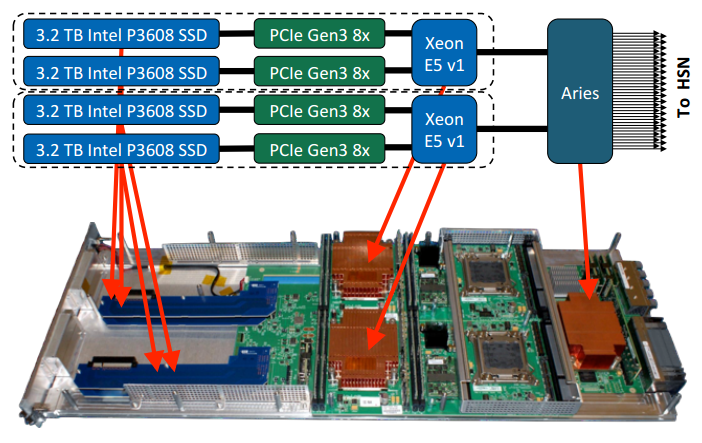
The Cori system is an Intel Haswell-based Cray XC machine selected for its ability to balance both compute and data-intensive high performance computing jobs. The second phase of the machine, when it arrives later this summer, will have the addition of Knights Landing cards for a greater performance boost. One of the key features, however, is the Cray DataWarp technology, which is the heart of the burst buffer performance described in the paper. The DataWarp features on the Cori machine consist of a flash-based burst buffer for accelerating I/O performance and a layer of NVRAM sandwiched between memory and disk. The current incarnation of the Cori system provides around 750 GB/sec of I/O performance and around 750 TB of storage.
As Debbie Bard, who is co-leading the burst buffer early user program at NERSC, tells The Next Platform, the early benchmarking efforts exceeded their expectations, but seeing how the burst buffer performs with actual applications has been most revealing. The DataWarp technology from Cray is being refined with help from NERSC in a co-development agreement, and Cray engineers on site have had the chance to solve problems with real workloads—something Bard says would have been impossible using benchmarks or tests.
In terms of lessons learned, teams found the burst buffer does provide high performance for large streaming I/O. This is not a surprise, especially since DataWarp was designed for this (which is the target for the checkpoint/restart use case for burst buffers) but this yielded similar benefits out of the box for workloads with I/O patterns similar to this (anytime users wrote out large data files). NERSC is using its burst buffer for checkpoint/restart purposes as well, but the real goal, Bard says, is to see how other goals might be met, including using the burst buffer against complex I/O patterns in things like workflow coupling.
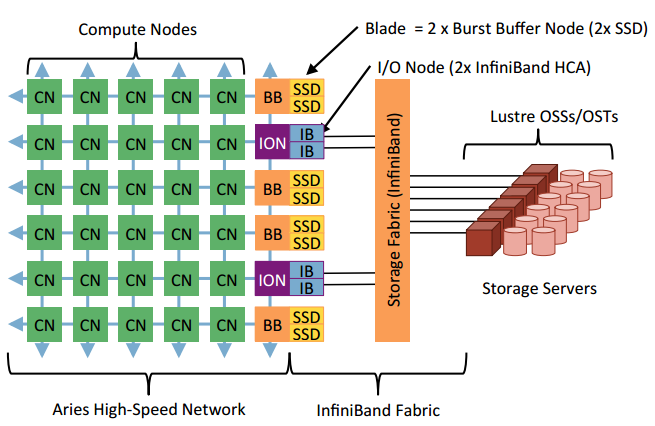
It turns out the above represents one of the more important (if not technically dense) use cases for achieving high levels of application performance with a burst buffer. In a nutshell, workflow coupling is important to NERSC’s mission to have systems that can handle both compute and data-intensive jobs simultaneously by allowing things like simulations and visualizations to be run concurrently. For one workflow cited in the paper, users would normally have to run their simulation, feed the data to the Lustre file system to be broken up and rewritten again to move to the next phase.
Instead of this more time-consuming process, with the burst buffer users can instead write their data files directly to the burst buffer and have the simulation continue and run a secondary job, independent of that simulation (but using its data) doing its own analysis. A more comprehensive description of this in real application context can be found in the paper’s description of the Chombo-Crunch/VisIT workflow. In essence, however, the burst buffer can act as a wingman for simulation data analysis—a very valuable thing when one considers the many reads and writes that would have needed to happen to move from simulation output, to creation of image files, to using those to create a movie to help scientists understand a particular phenomenon.
With this said, another lesson learned was that more challenging I/O patterns have mixed performance. The burst buffer does well with things that look like checkpoint/restart but there are many applications that are IOPS intensive, meaning users are reading in tens of thousands of small files and spitting out, say, hundreds of thousands of small files. This is not a good I/O pattern for anything, but flash can handle that more elegantly, says Bard. “With the burst buffer now, it’s not all the way configured for that kind of thing yet, but that’s where we’re making the most progress at the moment.” This is in conjunction with her team there at NERSC, and teams from Cray who are working to address these and other pressing issues as the DataWarp is tested at scale.
Among the other issues teams are working on is a more pressing problem from an HPC application perspective given the reliance on MPI. At its core, and this is illustrated in Figure 12 for those who want to give the full paper a read, there are some issues with MPI I/O that prevent collective I/O from performing well. This is a software-only issue, of course, and one that Cray is working with NERSC to resolve, but as Bard reminds, “developers have been optimizing MPI I/O to work well with Lustre for many years now whereas we have only had a couple of months of work under us to get MPI I/O to work well with DataWarp.” Bard remains confident this and other snags will be resolved.
Ultimately, there are a few applications with I/O patterns that are ready to make the burst buffer hum out of the box, but there is still a great deal of tuning to be done for others. This tuning can range from complex to relatively simple, but the performance make the effort worthwhile, Bard says.
As for Cori and NERSC’s future exploration of the burst buffer, the profiling work for key applications will continue. As the paper notes, “Considerable work is also underway at NERSC to provide multi-level I/O monitoring.” The next phase of the machine, which again, rolls out late this summer, will provide an additional 900 TB of storage to the burst buffer pool, and the DataWarp software will be available in its updated version, which will add transparent caching to the underlying Lustre file system.
Bard concludes that the burst buffer is performing even better than we expected and while there are some cases where Lustre alone outperforms the burst buffer, with the tuning and optimization footwork being done, a large number of critical scientific workflows will be getting a major analytics boost from the underlying Cray hardware and software DataWarp combination, especially with the upgrade this summer.