



The personal computer has been the driver of innovation in the IT sector in a lot of ways for the past three and a half decades, but perhaps one of the most important aspects of the PC business is that it gave chip maker Intel a means of perfecting each successive manufacturing technology at high volume before moving it over to more complex server processors that would otherwise have lower yields and be more costly if they were the only chips Intel made with each process.
That PC volume is what gave Intel datacenter prowess, in essence, and it is a key reason why Intel has on the order of 98 percent of server chip market share and system makers who use Intel chips have something north of 80 percent of the aggregate revenues.
With the PC market slowing and Intel not having high volume manufacturing for smartphones and tablets and acknowledging a slowdown in the rate of advances in chip making technology, it is reasonable to wonder what will become of the Xeon product line. Will Intel be able to keep innovating and delivering on something akin to the Moore’s Law curve we are used to?
During our conversations with Intel ahead of the launch of the “Broadwell” Xeon E5 v4 processors at the end of March, we posed such questions to Chris Gianos, the chip engineer who has led the design of the past several generations of Xeon processors, which are without question the most complex devices that Intel has ever made for volume use in the datacenter. (You could argue that the “Knights Landing” Xeon Phi processor is as complex as the new top-bin, 22-core Broadwell Xeon E5-2699 v4.) From where Gianos sits, Intel will be able to keep boosting the performance of the processors as it has been doing since the Xeon chips as we know them were introduced on the late 1990s.
Intel has a bunch of different dials that it can turn as it advances each Xeon generation, and with the acquisition of FPGA maker Altera, it has another set of functions it can add to the Xeon line with hybrid processors. But for the sake of argument, we are only considering how future Xeon processors as we know them might advance.
The first way to advance, of course, is through shrinking transistors, something that Intel has done marvelously and more or less along the Moore’s Law curve that the company’s co-founder, Gordon Moore, stipulated back in 1965 when mainframes were the hot new thing and Intel made controllers and memory, not processors as we know them. The idea is that every 18 to 24 months, process technologies advance enough that the cost of making a chip with a fixed set of functions falls exponentially. You can use some of the extra chip area to make a more complex device and hold the price about the same, too. Chip makers like Intel do both, as the widening and deepening of the Xeon server chip line over the past 15 years shows so well.
For a long time, shrinking transistors also meant that chip makers could crank up the clock speeds on their devices, and for a while back in the late 1990s, Intel and others thought they might be able to get clock speeds up to 10 GHz or higher on processors. But the thermal density of such a chip was way too high – about the same as the surface of the sun, as it turns out – and therefore clock speeds hit a ceiling of about 3 GHz or so for the Intel architecture around a decade ago. Having seen this coming, other chip makers started adding multiple processors to chips, which we called cores, and wrapping them with interconnects and other functions like memory and peripheral controllers or L3 cache that were previously out on motherboards. The result is that a Xeon processor today is essentially a system on a chip, although it is not called that in a formal sense.
Not all applications could spread their work over multiple cores, so it has taken decades to parallelize databases, middleware, and application runtimes so they can make use of multiple threads and multiple cores on machines with two, four, or eight sockets. Server virtualization helped drive adoption of multicore systems in the past decade because many workloads could be run unchanged, side-by-side, on beefier machines equipped with hypervisors. The Great Recession came along at just the time Intel and others got good at adding cores, when server virtualization from VMware, Microsoft, and Red Hat had matured enough to be useful, and when enterprises needed some way to cut costs in their infrastructure by driving up utilization on their systems.
Another important way that Intel has boosted performance is to improve the number of instructions per clock, or IPC level in the chip lingo, with each generation of Xeon chip. We do not have IPC ratings all the way back to the Pentium II Xeon, but here is a chart that Gianos put together to show how IPC has evolved over the past nine Xeon generations:
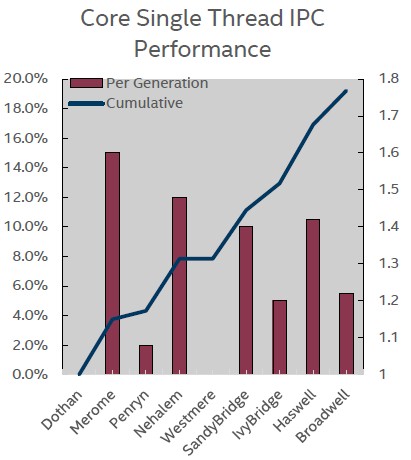
The upshot is that a Broadwell core in a Xeon running integer workloads has just under 1.8X the performance per clock as a Xeon had a little more than a decade ago with the “Dothan” cores.
To its credit, Intel has walked a lot of fine lines and wrestled with the laws of physics and thermodynamics to create Xeons that target workloads that need high single-threaded performance or can take advantage of lots of cores and threads or are somewhere in between in terms of performance and bang for the buck. We already analyzed the Xeon generations from the Nehalem Xeons launched in March 2009 through the Broadwell Xeons that just came out, seven years later. There are some fascinating trends in the data in the Xeon product lines that bear some review, so we encourage you to look at that.
The question now is whether Intel can keep this pace of performance improvements up. Gianos thinks so.
We asked Gianos how far can Intel push these levers, and observed that once the Xeon gets to a few dozen cores, Intel has to start to carve chips up into NUMA regions to squeeze the performance out of the cores on the die and wondered if core and cache expansions would run out of performance. We realize that Intel could put cores on a Xeon until the cows come home, but this is not the point. The real issue is how can customers effectively leverage the performance inherent in the cores on the die.
“With the increasing number of cores that we are putting on the die with each generation – and we do not see any let up in that trend – we are also putting on the features to enable us to manage the capabilities,” Gianos explained. “This comes in a variety of forms. There is resource contention that arises when you put too many things together and start sharing resources, and you see the response to the problems and the challenges that arise from resource contention and you are seeing features to mitigate that and to allow the processor to do what people want it to do in the presence of a lot of shared resources. You see this in various dimensions. We are continuously improving the interconnect. We had one ring and now we have two rings, and we will go to higher orders of connectivity and you are already seeing that with Knights Landing. We believe that there are legs here, and we are able to add bandwidth to basically feed larger numbers of cores and get the throughput we expect to get through these things.”
It took the industry a long time to be able to add two cores to a single die, but this seemed to be fairly easy given the experience the server makers and their chip partners had in putting multiple processors into a single system and having them share main memory. For systems, adding more processors gets increasingly difficult and offers diminishing returns due to the overhead of the interconnects that glue multiple sockets together, but Gianos said that at the chip level, the reverse has proven to be true.
“Honestly, as an architect that did a lot of this stuff, going from one to two is actually the big step,” Gianos explained. “You have to put on a thinking cap and get yourself to something that was not the number one. That was very hard. Then going from two to anything bigger than two required you to go back and find the places and rethink where you cheated because it wasn’t me it was the other guy. Once you get beyond numbers like four and eight to 16 or 18 or 22 or whatever, it is just more. But you are right, the architecture does get into a place where numbers like 32 or 64 could be a threshold, but at the hardware level, I have to say I have not seen a lot of that. For us, we moved from 32-bits to 64-bits for processing and memory a long time ago, and we are only up to 44-bits with addressing with the Xeons now, and maybe we will discover something as we approach the upper limit of 64-bits that will be difficult for us.”
Intel has said that it has good visibility into manufacturing processes from 10 nanometers down to 7 nanometers, and given the company’s track record at the forefront of process technology, there is no reason to believe that Intel can’t keep the Moore’s Law train going on silicon through several generations of Xeon processors using those 7 nanometer processors. If Intel goes with a “tick-tock-tock” model for its Xeons as it plans to do for its Core desktop processors, then there should be three generations of Xeons using its 14 nanometer, 10 nanometer, and 7 nanometer processors, which yields a total of eight future Xeon processors, possibly with an annual cadence, in the future.
What is not immediately obvious is that the improvements in IPC, which are just straight up circuit cleverness, are just as important as the process shrink and the core count and cache capacity increases that it engenders. It is a wonder, really, and we asked if Intel had anticipated that it would be able to keep up that IPC pace it has maintained, more or less consistently, over the past dozen years.
“I think that you will find different opinions on that,” Gianos said. “I know that many people on our core design team – and I am not on that team – thought there were ways to achieve this in the long run. Some of it is a cost/benefit tradeoff, just like Moore’s Law. With Westmere, we did a straight shrink. Here is the technology, we moved from four to six cores. We added transistors, but the IPC is exactly the same. We made a business decision on how much to invest. What you see from the chart is that we have a business model that yields relatively consistent behavior. I certainly think that the servers have benefitted from seeing this kind of improvement. You can only get so much out of a core count increase, and it is nice to get the single threaded improvement to go along with it. Everybody, even those running heavily threaded applications, still have some component of their software that is bound by single thread performance. And of course when the single thread performance goes up, multithreaded applications see benefits, too.”
As for Intel being able to keep that IPC increase going with future Xeon cores, Gianos said that “all evidence suggests that it can be.”
Intel could add more threads per core, too, if it wanted to boost throughput, but thus far as decided against this.
All of this brings us to the possible Xeon future driven by process technologies and IPC improvements. What might it look like? Gianos is not able to talk about that, just like anyone else at Intel can’t, but we can certainly speculate a little based on past trends. So, below is a table that shows the top bin parts in the Xeon product line dating back to January 1999 up through the current Broadwells, with some speculation about what the next several generations of Xeons might look like:
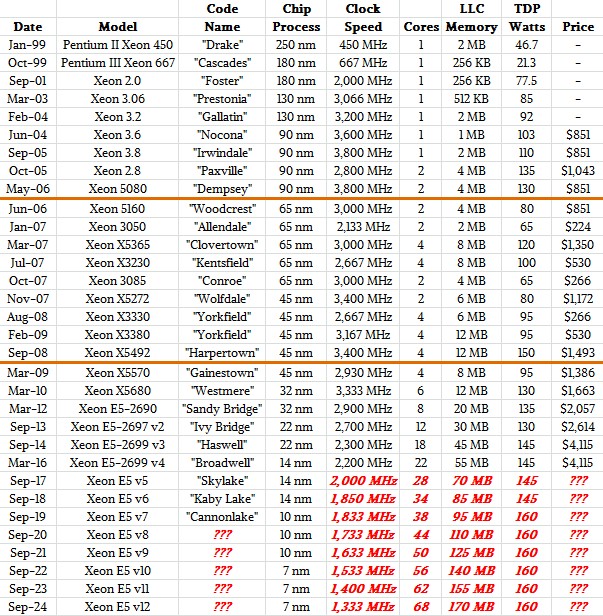
In the table above, the orange lines show the divisions where Intel moved to the Pentium M cores in 2006 and then to the Nehalem cores in 2009. We may be in for another big architecture jump in 2019 or 2020.
The future Xeon scenario shown in red in the table is based on the assumption that Intel keeps adding cores at a pretty consistent rate of about six per generation and that it can keep the IPC improvements at about 5 percent per generation. We also assume that Intel will put extra cores on the die and then turn off broken ones to improve yields, as it did with the high core count (HCC) variants of the Broadwell Xeons (two were latent) and with the Knights Landing Xeon Phi (four of its 76 cores are latent). In our model, the 14 nanometer parts have two latent cores and the 10 nanometer and 7 nanometer parts have four latent cores. We also assume that Intel stays with the same 2.5 MB per core for L3 cache on the die. Boosting the core counts and cache sizes means generating more heat, which should mean needing to cut back on the clock speeds for the top bin parts. The clock speeds will probably have to drop in baby steps each generation.
There are many possible scenarios, obviously. This is just a thought experiment, and we welcome your input.
Add up all of our assumptions, and by the Xeon E5 v12 generation in 2024, Intel has a top-bin part with 68 cores running at 1.3 GHz with 170 MB of L3 cache and maybe consuming 160 watts. The interesting bit is that this chip will have more than three times the cores as the top-bin Broadwell Xeon E5 v4 chip and even with a lower clock speed, be able to deliver about 2.4X the performance in terms of overall throughput – assuming that 5 percent IPC bump per generation holds up. If Intel can do more IPC, then it needs fewer cores to get the performance. Intel can have low core count (LCC) parts that have higher clock speeds and middle core count (MCC) parts that have slightly higher clocks and slightly lower core counts, too, much as it has done with Ivy Bridge, Haswell, and Broadwell Xeons.
But here is the big point: Moving from Nehalem to Broadwell, Intel increased the cores by 5.5X and got a 5.4X improvement in performance. To match that, Intel is going to have to have some big improvements in IPC – several generations with 10 percent or more improvements, as it has done in the past. Our model assumes this gets harder, too, just like process shrinks do.