NEXTPLATFORM AD
If you want a CPU that has the floating point performance of a GPU, all you have to do is wait six or so years and the CPU roadmaps can catch up. This seems like a long time to wait, which is why so many HPC centers made the leap to GPUs from CPUs starting a decade and a half ago, laying the groundwork – however unintentionally – for the massive expansion of AI on GPU compute engines.
In many ways, an X86 CPU turned into a general purpose serial compute engine with some parallel tendencies, with a healthy mix of integer and vector math capabilities and now, at least with some Intel and AMD CPUs, also accelerators for specific functions like encryption and hashing as well as matrix math engines, at least in the case of the past three generations of Xeon processors (which we now call “Sapphire Rapids” Xeon 4, “Emarald Rapids” Xeon 5, and “Granite Rapids” Xeon 6). AMD was expected to add matrix engines at some point into the Epyc processors, but has thus far resisted. Arm CPU designers may eventually follow suit.
NEXTPLATFORM AD
To a certain extent, a GPU is a massively parallel general purpose floating point engine with the occasional integer tendencies, and it has become the engine of choice for AI training and certain HPC workloads. This is due in large part to its high bandwidth and ever-lowering floating point precision, which allows for lower and lower resolution data to be used in the statistical algorithms that underlie AI training, thereby boosting their effective performance.
This is all well and good, but as we have pointed out in the past, we want many kinds of calculations to have higher precision, not lower precision, to improve the fidelity of the answers we get out of our simulations and models. While AI allows us to squint our eyes ever more tightly and still see something through our eyelashes and identify it as “Cat,” there are many applications that really do require double-precision FP64 processing. And were it free, we might be talking about FP128 or FP256 processing at 128 bits or 256 bits. (Sounds crazy, right?)
We have thought for quite some time that GPU accelerators have focused more on lower precision math than we think many HPC centers like, but the latest generations of Nvidia GPUs have really driven this home. The GPU prices have gone up faster than the FP64 performance because the “Hopper” H100 and H200 and “Blackwell” B100 and B200 accelerators are focused on driving down data resolution and calculations to FP8 and then FP4 formats to boost AI training and inference throughput. Nvidia has been careful to keep both vector and tensor units on its GPU compute engines, and to keep a reasonable amount of FP64 and FP32 performance on them, but the bang for the buck for FP64 is not what it could be.
We were reminded of the need for high precision floating point processing for HPC simulation and modeling by a recent story contributed to The Next Platform by Elad Raz, called The Hidden Cost Of Compromise: Why HPC Still Demands Precision. Raz is the chief executive officer at NextSilicon, which is making HPC-centric math accelerators known as the Maverick line. We covered the Maverick-1 and Maverick-2 reconfigurable dataflow engines from NextSilicon – well, that is what they are – back in October 2024. We don’t have the feeds and speeds of the Maverick chips, but we do have FP64 ratings for Nvidia and AMD GPUs and Intel and AMD CPUs, which dominate their respective submarkets of compute.
NEXTPLATFORM AD
We are snobs about FP64 and we want those running the most intense simulations in the world for weather and climate modeling, or materials simulation, or turbulent airflow simulation, and dozens of other key HPC workloads that absolutely need FP64 floating point to be getting good value for the compute engines they are buying.
We have a few observations before we get into the numbers we have compiled and plotted out for vector and tensor units on the core compute engines out there.
First, in the past, we have often spoken of matrix math as if it were a generic term when in fact a matrix is a special kind of lower-dimensional 2D tensor and a vector is an even lower dimensioned 1D tensor. So we are contrasting the performance of the vector units and the tensor units, which are unique and distinct in these compute engines, from each other. Not all code has been ported to tensor units and some must run on vector units.
Second, speaking very generally, we would say that at this point in the GenAI revolution, Nvidia is designing AI training and inference GPUs that can do some HPC, while AMD is making HPC GPUs that can do some AI training and inference.
NEXTPLATFORM AD
Between 2012 and 2020, FP64 peak theoretical performance on the vector units inside of Nvidia GPUs rose by a factor of 8.3X. (That is the “Kepler” K20 in 2012 and the “Ampere” A100 in 2020. With the “Hopper” H100 and H200, which are the same GPUs but with different memory bandwidth, the peak theoretical vector performance rose by 3.5X to 33.5 teraflops on the vectors. Without sparsity – meaning on dense matrices – the performance on the tensor cores in the Nvidia GPUs was twice that for the A100 and H100, at 19.5 teraflops and 67 teraflops, respectively.
With the “Blackwell” B100 announced last year and ramping now, the peak vector FP64 performance was only 30 teraflops, which is a 10.5 percent decline from the peak FP64 performance of the Hopper GPU. And on the tensor cores, FP64 was rated the same 30 petaflops, which is a 55.2 percent decline for peak FP64 performance on the Hopper tensor cores. To be sure, the Blackwell B200 is rated at 40 teraflops on FP64 for both the vector and tensor units, and on the GB200 pairing with the “Grace” CG100 CPU, Nvidia is pushing it up to 45 teraflops peak FP64 for the vectors and the tensors. The important thing is tensor FP64 is not double that of vector FP64 with Blackwells, and in many cases, customers moving to Blackwell will pay more for less FP64 oomph than they did for Hopper GPUs.
Which sounds like a good reason to buy used H100s, if you can find them, for HPC workloads that need the highest precision for calculations.
The good thing about the GPU market in recent years is that there are two suppliers, with AMD entering the field and being absolutely competitive – and particularly so since the launch of the “Arcturus” MI100 in late 2020 and better still with the “Aldebaran” MI250X in November 2021. With the MI250X, which is used in the “Frontier” supercomputer at Oak Ridge National Laboratory, AMD delivered a peak FP64 of 47.9 teraflops on its vector units and a peak 95.7 teraflops on its tensor units. MI100 beat Hopper H100/H200 by 19 percent in vector performance, but did not have tensor units. The MI250X had both vector and tensor units, and it beat the Hopper GPU by just under 43 percent in terms of peak FP64 oomph. With MI300X, AMD is crunching 81.7 teraflops on the vectors and 163.4 teraflops on the tensors, compared to a best of 45 teraflops on either vectors and tensors for the Blackwell GPU used in the GB200 package. That is 1.8X better performance on FP64 vectors and 3.6X better performance on FP64 tensors at peak throughput.
NEXTPLATFORM AD
The AMD devices are cheaper, too. Our best guess is that a single Blackwell B200 used in the GB200 package costs around $40,000, but you can get an MI300X for around $22,500. The bang for the buck advantage that AMD has for FP64 work is anywhere from 3.2X to 7.3X comparing MI300X to B100, B200, and B200 paired with Grace.
Yes, Nvidia has a huge CUDA software stack for HPC and AI and it has advantages when it comes to lower precision floating point and other tricks for running foundation models. But we are talking about HPC workloads here. We are The Next HPC Platform as much as we are The Next AI Platform, after all.
Just for fun, we plotted out the FP64 performance of Intel Xeon and AMD Epyc processors over time, and calculated the bang for the buck of these devices and plotted them against the Nvidia and AMD GPUs since 2012.
Remember, these charts below are for peak theoretical performance for FP64 math on vector and tensor units. It is not maximum achievable performance, which takes into account eccentricities of the architecture of any given compute engine that keep it away from peak; and it is certainly not maximum sustained performance on a suite of HPC applications. We are using base clock speeds, not overclocked speeds.
Our desire is to describe the shape of the market for FP64 compute and how the economics have changed over time. This sets the stage for new devices like the Maverick-2 from NextSilicon as well as the next generations of GPUs and CPUs from the usual suspects mentioned above as well as any homegrown Arm or, someday, RISC-V CPUs.
The is for the top bin parts with the most cores available at the time without resorting to double-packing the sockets as Intel has done with the non-standard Xeon AP packages a few times.
Some things are easy to see on a normal plot, and others need a logarithm plot so you can see the deltas better. So we did both. Let’s take a gander:
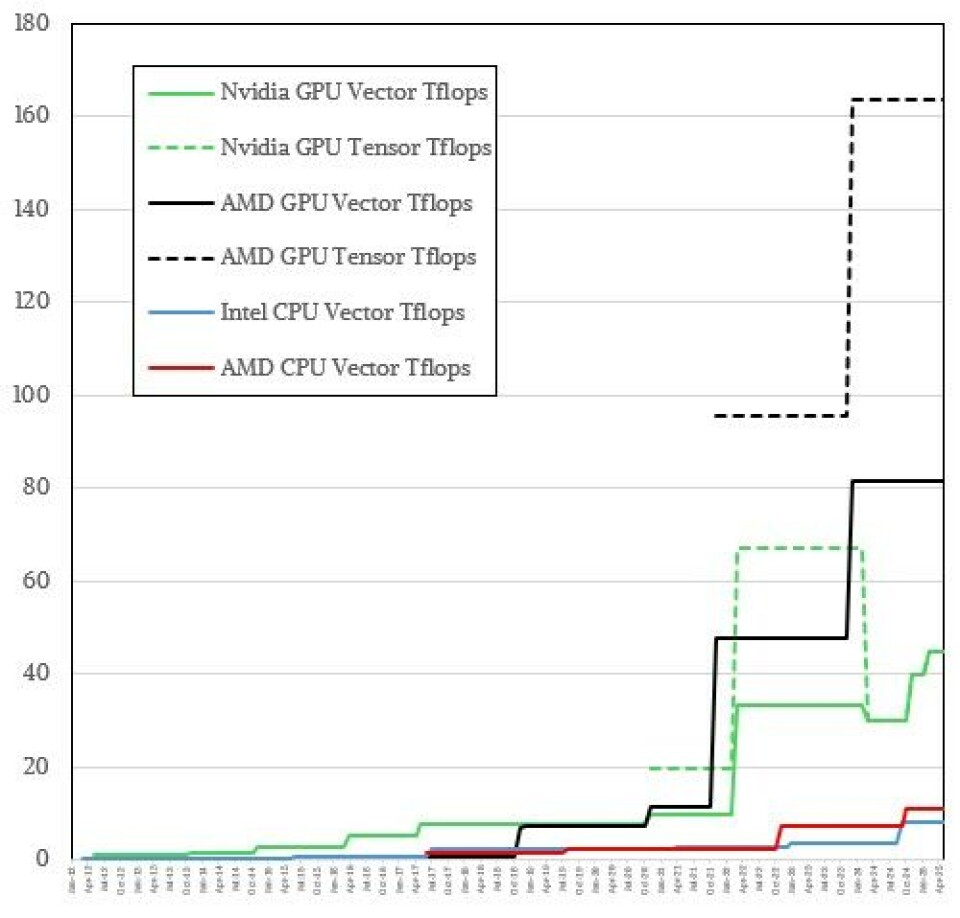
You can barely see the performance of the Intel and AMD CPUs down there at the bottom of the chart, but you can see how Nvidia pulled back on tensor FP64 performance for its GPUs and how AMD GPUs have passed it. (You cannot see the monthly figures on the X axis, no matter how good your glasses are, and that’s OK. The charts run from January 2012 through May 2025.)
If we switch to a log view, something interesting pops out:
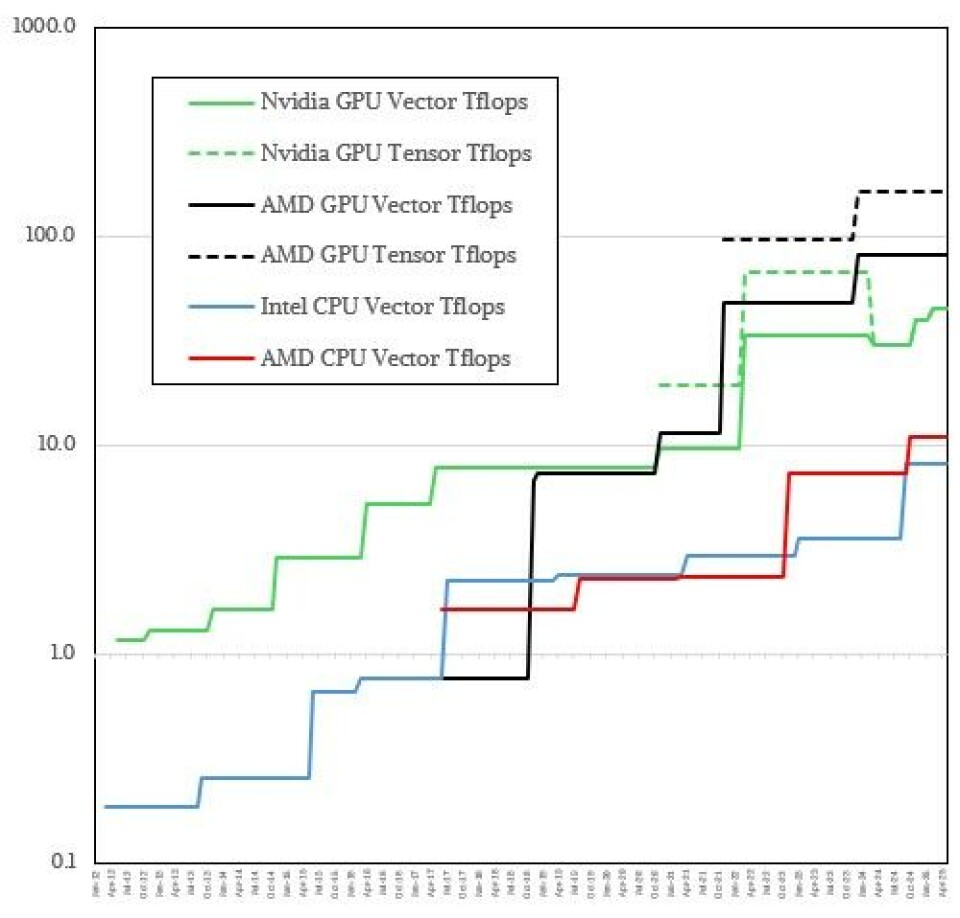
AMD GPUs did not have tensor units until the MI250X. And before that time, both Intel Xeon and AMD Epyc CPUs were only around a factor of three as slow as GPUs on vector FP64 throughput. In late 2020, Nvidia and AMD really goosed their GPU vectors, and Nvidia added tensor cores, and the gap between the CPUs and the GPUs in terms of FP64 performance really opened up.
The other neat thing was that in 2016, when AMD launched the MI25 based on the “Vega” architecture and Intel was shipping the “Broadwell” Xeon E5-2699 v4 CPU, they had the same FP64 performance. That said more about the Vega architecture than it did the Broadwell architecture. And it shows just how far AMD has come over the past several years in GPUs. You can also see that the “Naples” Epyc 6001 processors also beat the pants off the MI25 and so did the “Haswell” Xeons that were out at the same time.
That is the only time there is performance overlaps between CPUs and GPUs, and you can see that AMD has quickly caught up to Nvidia and is consistently ahead of it on FP64 throughput on GPUs. And moreover, you can see in the log plot that AMD is usually consistently beating Intel on FP64 vector throughput on CPUs as well.
Performance is one thing, but it costs money. So how do these devices stack up in terms of price/performance for FP64 calculations? Take a look:
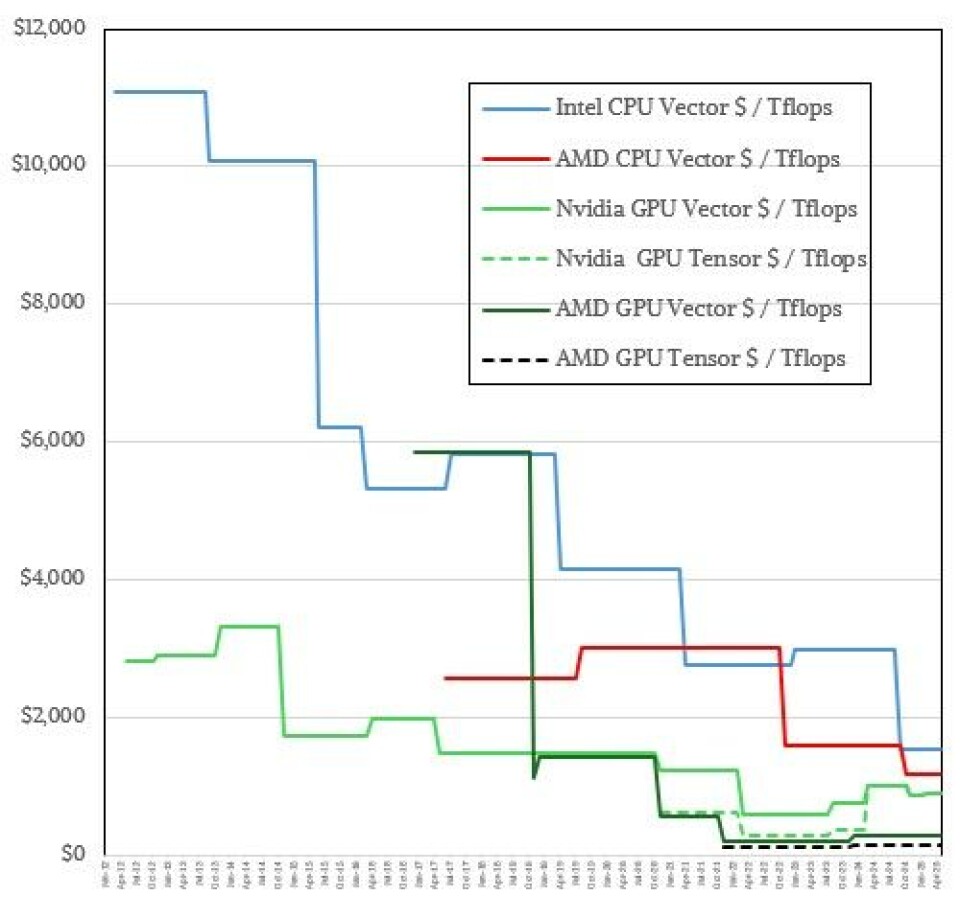
One interesting thing is how the improvement in bang for the buck has been quick for Intel, and that is no doubt due to the influence of GPU compute, which offered considerably better value for dollar. The Intel curve is a lot steeper than the Nvidia curve, and part of that is an architectural choice on behalf of Nvidia to back off on FP64 performance increases at the same time that AMD and Intel keep boosting it. Intel also slashed prices on its “Granite Rapids” Xeon 6 processors, which brought it more in line with AMD Turin Zen 5 core processors, but AMD is still offering a bit better value on the CPU front than is Intel for FP64 vector compute.
(Note: We did not take into account Intel’s AMX tensor units with the past three generation of Xeons. We do not know anyone who is offloading HPC functions to these tensor units. But clearly, someone could.)
Shifting to a log scale shows the competitive positions of Nvidia and AMD on GPUs for FP64 compute a little easier:
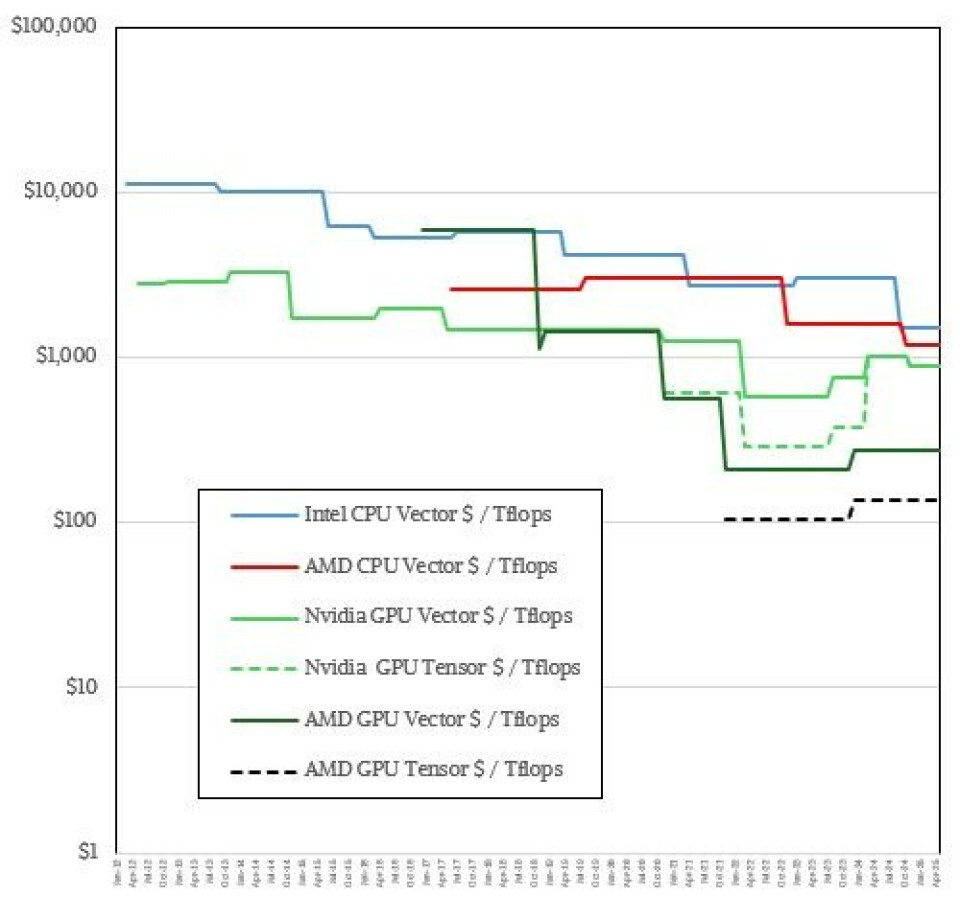
Assuming our pricing is correct, AMD is the clear value leader on GPUs.
Let’s take the Nvidia H100 from 2022 as the baseline, which cost $582 per teraflops for vectors and $291 per teraflops for tensors. AMD MI250X GPUs were at $209 per teraflops on vectors and $104 per teraflops on tensors. With the MI300X, the price of the GPU has more than doubled to around $22,500, but the FP64 performance has only gone up by 1.7X, so the value per dollar is $275 per teraflops on vectors and $138 per teraflops on tensors. The Nvidia H200 costs more than the H100 with the same peak performance, and the B100 costs more still with less peak performance – and a lot less on FP64 tensor units. So it is up to $1,000 per teraflops for either vector or tensor units on the B100. The B200 adds some FP64 oomph (33 percent, to 40 teraflops) but the price is around $35,000, which is $875 per teraflops for either vector or tensor. The GB200 has a Blackwell that will run at 45 teraflops at FP64 precision, and at $40,000 that works out to $889 per teraflops.
AMD should be able to sell so many MI300Xs to the HPC community it would make our head spin. Which is why we think it cannot make as many of them as many people might be thinking.
Just for fun, a Granite Rapids Xeon 6 6980P with 128 cores is rated at 8.2 teraflops and costs $1,521 per teraflops on its vectors doing FP64 work. (It was $2,173 before the price cuts a few weeks ago.) The AMD Epyc 9755 with 128 cores running at 2.7 GHz has just over 11 teraflops of FP64 oomph at $1,174 per teraflops. That is a cost per teraflops for AMD GPUs in 2018 and for Nvidia GPUs in 2021 on their vector units.



















