


A decade and a half of enterprise cloud adoption has spread vast amounts of data and processing around the globe, and the onslaught of generative AI – and now agentic AI – is only accelerating it.
Synergy Research noted in its Q1 report that since the end of 2022 – soon after OpenAI’s launch of ChatGPT – the cloud market has grown 52 percent. In its annual State of the Cloud report earlier this year, Flexera, whose software helps organizations manage their cloud environment, the 76 percent use in data warehouse services in part is driven by the need to feed AI models, and 72 percent of organizations are using generative AI services in the public cloud. Last year, the number was 47 percent.
These are boom times for hyperscalers – second-quarter spending on cloud infrastructure services reached almost $99 billion, more than $20 billion year-over-year.
That said, they also are dealing with their share of challenges that come with the cloud and AI, from enabling organizations to run these highly distributed workloads more easily across multiple locations to complying with disparate national data storage regulations to ensuring high levels of performance and availability.
Amazon Web Services, Microsoft Azure, Google Cloud, and essentially every hyperscaler and cloud provider is trying to navigate the best passage forward to address these demands.
For its part, Oracle this week unveiled the latest step in this effort with the launch of its Oracle Globally Distributed Exadata Database on Exascale Infrastructure, a service running on Oracle Cloud Infrastructure (OCI) with the aim of giving enterprises a singular operating experience even though their workloads and the infrastructure they’re running on are scattered around the world.
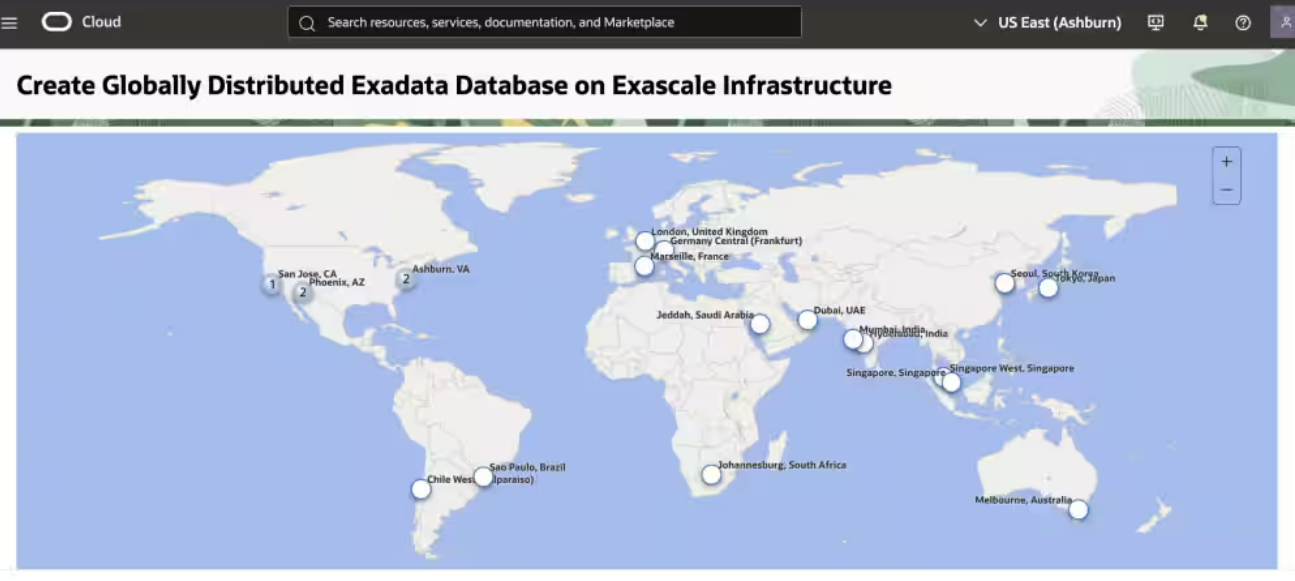
It’s essentially a combination of two of Oracle’s technology, Wei Hu, senior vice president of development for high availability and emerging technologies, told The Next Platform.
“One is our Global Distributed Database and, secondly, it’s our Exascale infrastructure based on Exadata,” Hu says. “The goal is really to build an always-on, auto-scaling serverless architecture that is powerful, easy to use, and cost-efficient. It’s a distributed database. The distributed database is basically a single database where the data is stored in multiple physical locations. It can be physical servers, it can be in physical datacenters, different regions, different countries.”

He noted that Oracle has been a distributed database since 2017, when it introduced database sharding, which scales databases horizontally by dividing larger ones into smaller and more manageable pieces, or “shards,” each of which is stored on a separate database server and drives better performance and scalability as the database grows.
The serverless architecture includes Raft replication that synchronizes data across multiple datacenters to ensure what Oracle calls an “active/active/active” capability to ensure the data is always available, hyperscale-level OLTP so databases can scale to support millions of transactions per second with petabytes of data, capacity than can grow or shrink depending on need, and near-real-time response.
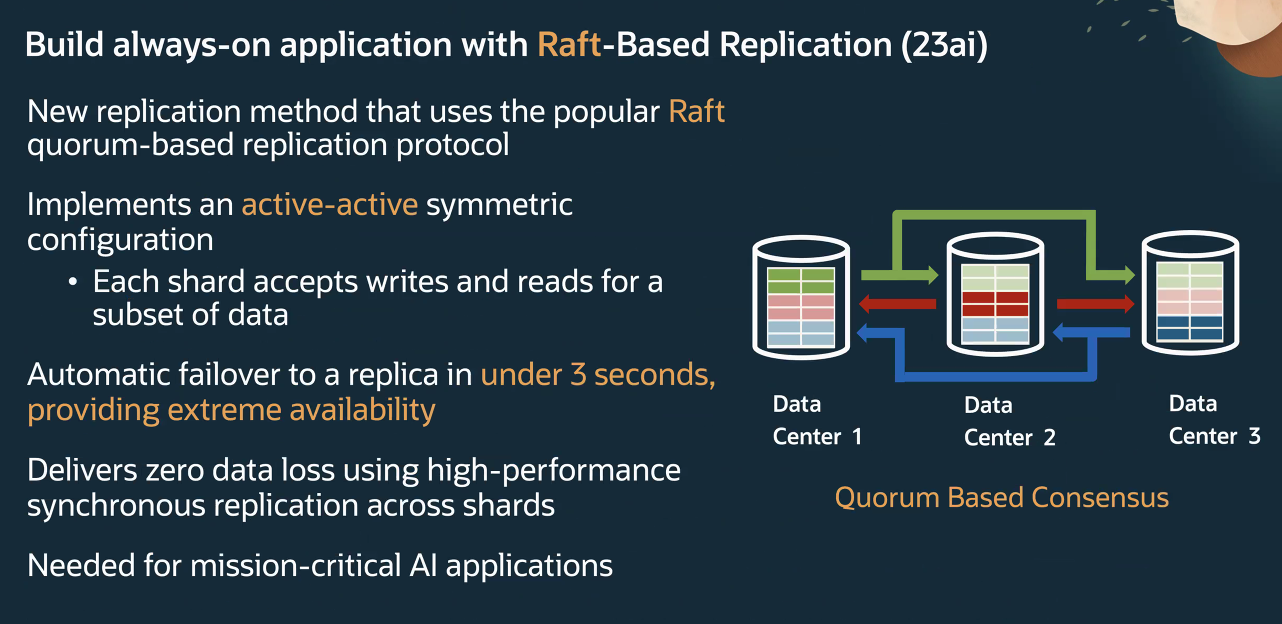
Data residency and user proximity features allow organizations to store data in Oracle Cloud Infrastructure locations nearest to users and to meet data security and privacy regulatory requirements that call for data to be stored locally. The European Union’s General Data Protection Regulation (GDPR) put a focus on that when it went into effect in 2018, and India also is moving that direction. The country unveiled its Data Protection Act in 2023, but only earlier this year released draft rules for it.
Oracle’s Hu used a US banking customer with a global reach as an example of how its new service can be used in a situation like India’s.
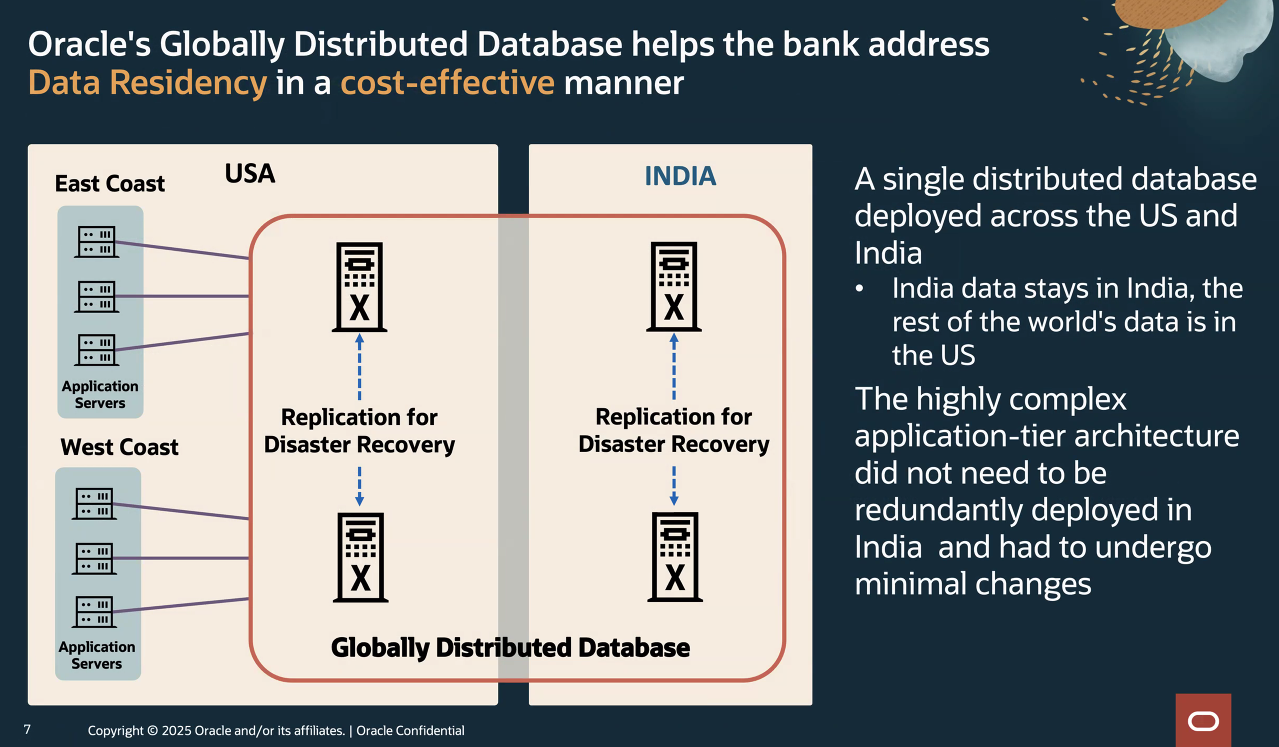
“Before, all the money transfers were done by using data stored in the United States,” he says. “That doesn’t work anymore. What they did was split off to India data and relocated it to India and kept the rest of the world – except for India – in the United States. The key thing is the whole thing is still a distributed Industry database, but it looks like a single logical database to the applications.
It’s an important point because the bank’s application stack is complicated, with hundreds of microservices and data feeds all coming into it, Hu explains.
“The is all to keep the application stack the way it is in the United States,” he says. “To have an application stack in each country would be really, really expensive. That would force them to exit certain markets. Right now, we’re in the process of working with them to deploy this to additional countries.”
The accelerating expansion of AI workloads also plays a role, with the service featuring petabyte-scale AI and analytics that allows users to run such jobs over a long time on streaming data running in real time and processing millions of records per second. The hyperscale-level OLTP also can be applied to AI applications.
“Agentic AI workloads actually drive demand for these hyperscale systems,” says Hu. “They can place immense demands on backend systems. What’s interesting about agentic AI workloads is that they’re highly variable. When they come, they can hit a very high peak, but then they go away. Then they come again later and so forth. What you want are hyperscale serverless databases that can elastically scale up and down as required, but you don’t want to build for peak capacity and keep it there, because that’s just very expensive. In addition, you need to be able to do AI vector searching across very large datasets. Finally, agentic AI workloads, like anything else, must meet data residency requirements.”

In addition, Steven Zivanic, global vice president of database and autonomous services and product marketing at Oracle, tells The Next Platform that as AI agents become more widespread, distributed transactions are going to increase correspondingly, so what’s happening now is as a point in time.
“It’s kind of a confluence of multiple things happening,” Zivanic says. “You’ve got the rise of agentic AI, you’ve got a need for these secure data residency solutions coming out. I think with the low-cost structure of this particular offering, it makes it applicable to virtually any organization that can subscribe to this. The exascale component lowers the cost so that it’s available to anybody.”