
The interesting thing about the June 2023 rankings of the world’s most powerful supercomputers is not how it really has not changed all that much in the past six months, or that the June list is coming out in May. But rather it is how that list might change, yet again, this time thanks to an influx of cloud systems and AI systems, moving the rankings even further away from its original goal of ranking the performance of the largest, permanent supercomputers doing HPC simulation and modeling.
Such transformation is inevitable, given the nature of the broader realm of “high performance computing,” particularly when running the High Performance Linpack benchmark test on a distributed system is not that hard compared to other tests and when such tests are often run for political and economic reasons as much as to show the relative performance of commercial, academic, and national supercomputers that perform simulation and modeling tasks.
We have talked time and again about how the Top500 list of supercomputers has been flooded with instances of machines that do telecom, Web, and hosting workloads for their day jobs. And as we see the rise of commercial AI systems, the vendors that build these machines and the countries and companies who host them are going to be rightfully proud of what they do and they are going to run HPL on their machines to show off. And even though these machines rarely, if ever, run 64-bit floating point math and even more rarely do traditional HPC work, there are going to be thousands of such systems in the world and only 500 spaces in which to show them. And the HPC community is going to want to continue to show the vibrancy of the cluster business, so you know they will be eager to add such machinery to the list, too.
We are fine with ranking the machines of the world that are doing HPC in the broadest sense, of course. But we think there needs to be something easy to use like HPL for the AI community and that is not as arduous to do as the MLPerf tests that AI hardware vendors prefer. We also think there needs to be more rigorous auditing of benchmark results to prove that machines are actually doing HPC or AI work, and not just have clusters at the hyperscalers, cloud builders, and telcos carved up into chunks large enough to dominate the middle third of the Top500 list. (Hewlett Packard Enterprise and Lenovo, we love you for all of the great HPC work that you do, but we all know what is going on here. IBM did the same thing way back in the 2000s, and so did other vendors.)
With that, let’s take a look at the June 2023 Top500 list, which still does not include Chinese exascale systems that most people are pretty sure exist and that still has the “Frontier” supercomputer, at 1.19 exaflops sustained performance on HPL, as the only certified exaflopper in the world. The “El Capitan” system at Lawrence Livermore National Laboratory and the “Aurora” system at Argonne National Laboratory, also paid for by the US Department of Energy, will join the exaflopper ranks later this year, and almost certainly in time for the November 2023 Top500 rankings.
The Frontier system at Oak Ridge, which is a cluster of over 4,000 nodes comprised of a custom “Trento” AMD Epyc CPU and a quad of AMD “Aldebaran” Instinct MI250X GPU accelerators link by the Slingshot 11 Ethernet interconnect from Hewlett Packard Enterprise, and the “Fugaku” systems based on the Fujitsu A64FX heavily vectored Arm CPU and its Tofu D interconnect, remain unchanged at number one and two on the list, with peak theoretical performance at 64-bits of 1.68 exaflops and 537.2 petaflops. Fukagu is two years older and is quite a bit hotter, has a little more than a third of the performance at 64 bits, burns more juice, and cost a lot more per unit of compute. RIKEN Lab in Japan, where Fugaku and its predecessor, the K supercomputer, called home, has fostered remarkably well-rounded machines that delivered the best efficiencies on tough workloads like the Graph500 test or HPCG.
The Lumi system at CSC Finland is ranked at number three on the list and was upgraded to its current 309.1 petaflops sustained performance last November. Like Frontier, Lumi is based on the Cray EX235a system from Hewlett Packard Enterprise – as will El Capitan and Aurora be. El Capitan will be based on the “Antares” hybrid CPU-GPU compute engine called the Instinct MI300-A, which has two “Genoa” Epyc chiplets” and six GPU chiplets in a single package. Aurora will have nodes based on a pair of Intel’s “Sapphire Rapids” Xeon SPs cross-coupled to six “Ponte Vecchio” Max Series GPU accelerators using an Xe Interconnect to link the CPUs and GPUs and Slingshot 11 to link the nodes. So far, HPE was been very good at compelling the attachment of Slingshot 11 interconnects with its CPU and GPU nodes in pre-exascale and exascale class machines. As we have pointed out before, Lumi was supposed to be expanded to 550 petaflops peak on its GPU partition, and it is not clear if this is still happening. What CSC Finland now says is that this Lumi-G partition will have a peak of 375 petaflops sustained performance on Linpack.
The ”Leonardo” system at Cineca in Italy, which was built by Atos (now called Eviden), was added to the list last November as well, remains number four in the Top500 rankings, but was upgraded with 25 percent more iron and saw its peak performance rise by 19.1 percent to 304.5 petaflops but its sustained Linpack performance rose by 36.6 percent to 238.7 petaflops.
Nothing else has changed in the top ten of the Top500. We do want to hunt around for interesting new systems and other trends, though.
Trends And Tidbits
Let’s talk about cloud for a minute. Microsoft Azure has seven permanent, if virtual, clusters that are running real customer HPC workloads that made the Top500 list this time around. This is significant, and with the number 11 ranking with an Explorer-WUS3 system comprised of 48-core Epyc 7V12 processors and MI250X GPUs from AMD, with server nodes interconnected with 100 Gb/sec HDR InfiniBand from Nvidia, this machine has a peak Linpack performance of just under 87 petaflops and a sustained performance of just under 54 petaflops. That is a 62 percent computational efficiency, which is in the ballpark of the 65 percent to 70 percent efficiency we see commonly in GPU-accelerated machines, and clearly the Hyper-V virtualization on the Azure cloud instances eats up some performance (as any hypervisor on any cloud would necessarily do). The Voyager-EUS2 cluster that has been running since the summer of 2021and that was ranked number ten on the November list that year, drops to number 16 on the list at 30 petaflops sustained. Microsoft’s four Pioneer clusters are still ranked in the 40s with 16.6 petaflops peak, and its original HyperCluster machine, based on Intel Xeon SP CPUs and Nvidia V100 GPUs, which came onto the November 2019 list, is still ranked number 289 with 2.67 petaflops of sustained Linpack oomph.
Microsoft has 229 petaflops peak and 153 petaflops sustained 64-bit performance in operation, which is in the same range as the “Summit” supercomputer at Oak Ridge. We wonder how much money these seven cloudy HPC clusters generate, and if they have paid for themselves yet, but we know one thing. None of the national labs in the world are generating revenue for their clusters, even if they are doing important science. If you add in the two clusters at Yandex in Russia and one at Descartes Labs at Amazon Web Services in the United States, there are ten clous instances on the June Top500 that have 294.1 peak petaflops, which is a mere 3.8 percent of the 7.83 exaflops of aggregate peak 64-bit floating point performance of the entire list.
That doesn’t sound like much, but remember: This Top500 is only a ranking of machines that are submitting results to the people who run the list. It is not a list of all HPC machines known and unknown, cloud or not. This has always been our gripe. We need a list – a database – that has our best guesses of the performance of machines we know about as well as the ones who do the test. Otherwise, we get a distorted view of reality. (Don’t get us wrong. The data we do get in the actual Top500 is very valuable, and HPCG, Graph500, Green500, and other benchmarks are extremely valuable, too – within their limits.)
We think there are a lot more cloud instances of HPC clusters, and there are probably some more that are permanent residences on the cloud and will be in use for three or four years.
Speaking of which, we want a new detail in the sublist generator, good people of Top500. The rankings tell us what ranking a machine came onto the list with and how it changes twice a year until it falls off the list, but it doesn’t tell us how long it has been in the Top500 rankings. The data is in there, since we know when it entered the list. It would be interesting to track how long supercomputer clusters stay in the field, and if that number is getting longer as it is for servers installed at the hyperscalers and cloud builders. A three year cycle for these big server buyers (as opposed to buyers of big servers) is stretching out to four, five, and six years – and we strongly suspect that the duty cycle for supercomputers is being stretched out, too, even as compute engines with better bang for the buck per watt are coming out every year.
Now. Let’s talk about the re-ascendant AMD in the HPC space, both for CPUs and GPUs.
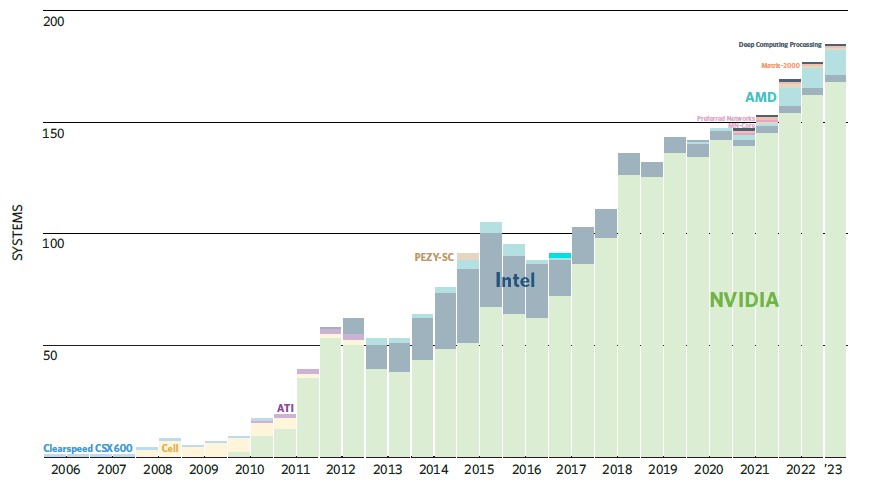
Of the 184 accelerated machines on the June 2023 list, eleven of them have AMD GPUs, but 167 have Nvidia GPUs and the other six have other kinds of accelerators like those Intel Knights coprocessors. AMD has 5.9 percent of accelerated system share in GPUs, compared to 90.8 percent for Nvidia. That doesn’t sound so great. But if you look at the number of GPU streaming multiprocessors in those systems, AMD has a 30.3 percent share compared to 53.2 percent for Nvidia, since its GPU base is newer, and it has 49.2 percent share of Linpack sustained performance across those 184 machines compared to 48.6 percent for the combined Nvidia GPU base on the current Top500 list.
This is a remarkable thing to have happened in a few short years, but Nvidia is going to be fighting back with its Grace-Hopper and Grace-Grace compute engines, the former being a CPU-GPU hybrid and the latter being a dual-CPU package tightly coupled.
Now, let’s talk about CPUs on the Top500 list. Our buddy Aaron Rakers over at Wells Fargo Securities made this pretty chart counting cores by CPU generation and vendor over time:
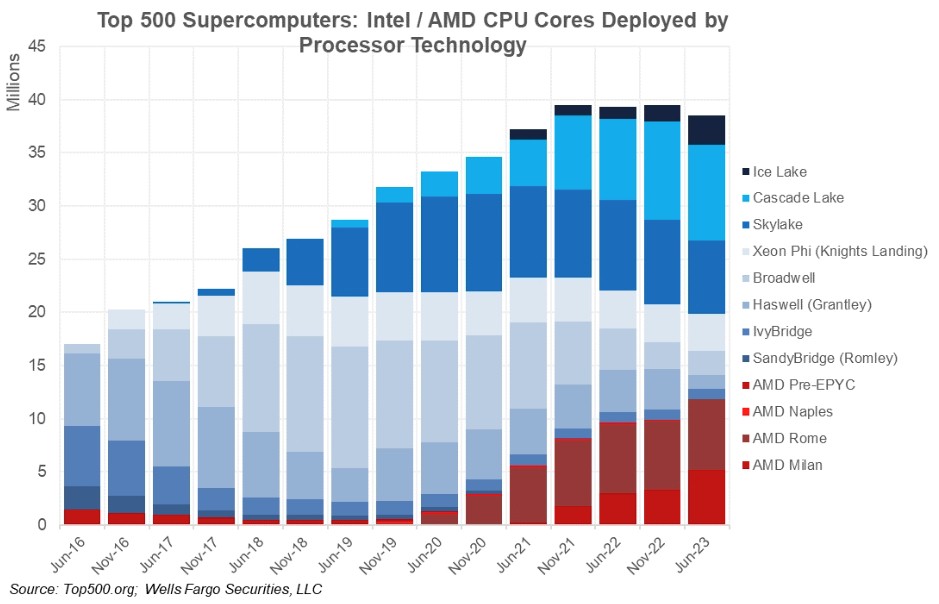
The first thing I hoped you noticed is that the number of cores in the Top500 list has kissed 40 million and has been kissing it like a bad rom-com for the past two years. AMD’s share is on the order of a third of the cores and has been growing steadily since 2020. Now, if you drill down into the data and adjust to show the performance of the cores by CPU generation, AMD’s share of systems is only 24.2 percent in the current Top500 list with a share of cores around 35.4 percent, but its share of sustained Linpack embodied in those cores is 51.1 percent. This data, which comes from the Top500 database sublist generator, seems to include the count and the performance of both the CPU and GPU cores. It is not easy to isolate the CPU-only systems and make comparisons of these, which would be useful.
Our point is, if AMD has somewhere a little bit north of a third of the CPUs in the Top500 systems, of the aggregate performance embodied in those CPUs, its share of performance might be 40 percent, or maybe a little bit higher. AMD has not enjoyed such success in HPC since the peak of the Opterons back in the middle to late 2000s. And this time, it has to take on not just Intel in CPUs, but Nvidia in GPUs.
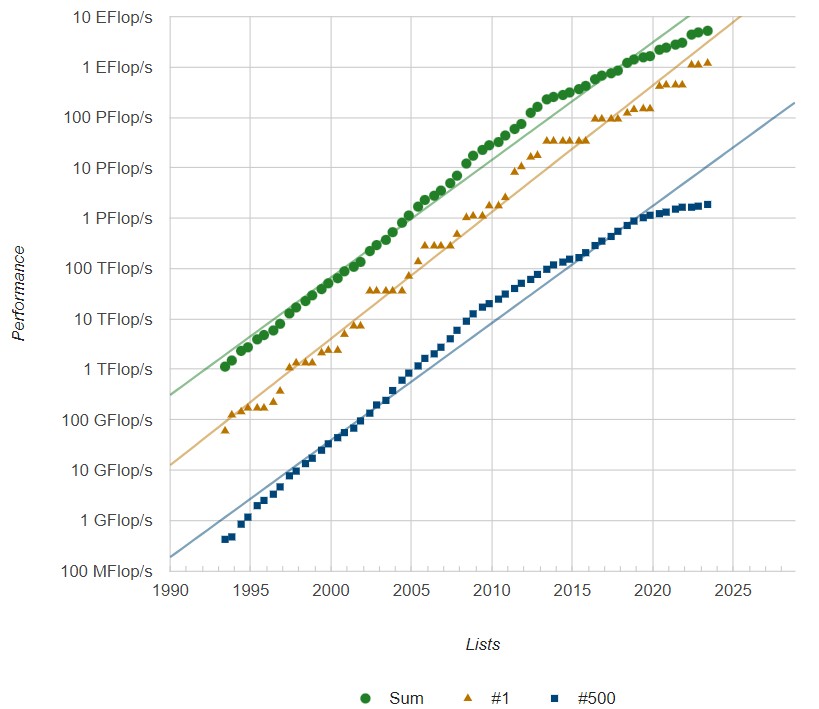
To get onto the list, a supercomputer had to have at least 1.87 petaflops on Linpack. To break into the top 100 machines, which is a reasonable proxy for capability-class supercomputers doing real HPC work, you have to break 6.32 petaflops.
The total capacity of the Top500 list is now 5.24 exaflops, up 7.8 percent from November last year and up 19.1 percent from the 4.4 exaflops a year ago.

The NVSwitch Fabric That Is The Hub Of The DGX H100 SuperPOD
Normally, when we look at a system, we think from the compute engines at a very fine detail and then work our way out across the intricacies of the nodes and then the interconnect and software stack that scales it across the nodes into a distributed computing platform. But this …

Boosting AI Storage With QLC Flash And Deduplication
A few years ago, DirectData Networks gave us a hint at the tectonic-like shifts that were emerging in datacenters at enterprises and high-end research institutions and were shaping the strategy of a company that had made its name in HPC with its parallel file system technology. New performance and storage …
Cornelis Unveils Ambitious Omni-Path Interconnect Roadmap
As we are fond of pointing out, when it comes to high performance, low latency InfiniBand-style networks, Nvidia is not the only choice in town and has not been since the advent of InfiniBand interconnects back in the late 1990s. The folks at Cornelis Networks, which acquired the Omni-Path interconnect …
Thanks for these great insights and analysis! The dullness of this June List is just breathtaking — wow. I was hoping for some competition, some fight to the finish, some blood, some gore, some suffering … nada. With such a non-spectacle, some may wish to get refunds on their free plane tickets to Vienna …
This begs the questions: where is the aurora, where are the gracehoppers, and is the #11 azure eating their hamburgers, or other lunches (have they gone to Frankfurt, by mistake, and got stuck with Mike Ditka polish sausage hot-dogs, plus surrounding AI crowds)? The anti-climax of this list, at which a supreme battle royale was expected, or at least hoped-for, between the big 3, is likely quite revealing, by the deatheningness of its silence (no gasps of great new effort, no grunts of new intolerable pain and excrutiating agony, no loud orgasmic screams of victory by a new or old champion, echoing in the moonlit landscape of the isc-2023). AMD, uncontested, wins this round hands-down, clean-off; it is crowned the Shaolin AND Ip Man of this June List, by default (and becasue of their superb execution).
Still of interest, maybe, that they’ve (top500 folks) listed some HPL-MxP results at the bottom of the HPCG web page, suggesting a possible mainstreamization of this benchmark (formerly HPL-AI, or “formally” according to the website). It’s nice to see that mixed-precision can give a near 10x speedup on dense matrix calcs. Also, O’Henri (Xeon+H100) did climb up the charts, from 405 last November to 255 now, and it is still Numero Uno in Green500. Speaking of which, the Numero Ocho green machine is a new entry, from MEGWARE, also Xeon+H100 (at 483 in HPL), and possibly a beast to watch in upcoming contests. The remainder of the list (that matters) is AMD, and the Fugaku Lone Ranger.
Well then (schnitzel), it looks like it’ll be November ’til we can enjoy some properly exciting HPC entertainment, with punchy knockout rounds, and sudden-death overtimes, or computational equivalents. Hopefully the no-shows will pull-up their shorts, and prepare their forks, for that next bout of the HPC gastronomy battle royale!
“Patience, Gracehopper.”
Ah-Ha! I guess someone knew what topic his next article was going to be on … eh-eh! But, sticking with this boring June ’23 List topic, for a couple extra items of possible disinterest … There is a new A64FX system, at both #50 and #51 in HPL, #21 and #22 in HPCG (the same exact one, same specs, same location, cloned twins?) which makes a total of 6 systems based on that 48-core chip (mostly PRIMEHPC FX1000, all of them in Japan). And, there is this new Sapphire Rapids + H100 DGX SuperPOD (Pre-EOS, 128 nodes) at #14 in HPL (#34 in HPCG — might need tuning of some libraries) which suggests an interesting, upcoming, “EOS” machine (an upgrade to Selene?). That’s all I got …
Well, HuMo, if you had reviewed your lecture notes before the big event, you would have noticed the detailed analysis of EOS (indeed successor to Selene) ( https://www.nextplatform.com/2022/03/23/nvidia-will-be-a-prime-contractor-for-big-ai-supercomputers/ ), and the JMA torrential downpour twin pairs ( https://www.nextplatform.com/2023/02/27/japan-buys-supercomputer-to-predict-torrential-downfalls/ ). Happy reading! 8^p
Good article. “We wonder how much money these seven cloudy HPC clusters generate, and if they have paid for themselves yet”, any estimates here?