

UPDATED Like many HPC and AI system builders, we are impatient to see what the “Antares” Instinct MI300A hybrid CPU-GPU system on chip from AMD might look like in terms of performance and price.
And with the ISC 2023 supercomputing conference coming up in a few weeks, and Bronis de Supinski, chief technology officer at Lawrence Livermore National Laboratory, is giving a talk at the event about the future “El Capitan” exascale system that will be the flagship machine for the MI300A variant of the Antares GPUs, it is on our minds.
So, just for fun, we pulled out the trust Excel spreadsheet and tried to estimate what the feeds and speeds of the MI300 and the MI300A GPUs, the latter of which will be at the heart of the El Capitan system might be. Yes, this is perhaps folly, considering that AMD will likely talk a bit more about the MI300 series of GPUs at ISC 2023 and beyond, and we will eventually know precisely how this compute engine is architected. But quite a number of people keep asking us if the MI300 series can be competitive with the Nvidia “Hopper” H100 GPU accelerators and, perhaps more importantly, competitive with the combination of the 72-core “Grace” Arm CPU lashed tightly to the Hopper H100 GPU to create a combined Grace-Hopper hybrid CPU-GPU complex that will go toe-to-toe with the MI300A that is going to be deployed in El Capitan and, we think, other hybrid CPU-GPU machine running HPC and AI workloads side by side.
And considering the intense demand for GPU compute, driven by an explosion in AI training for generative AI applications based on large language models, and AMD’s desire to have more of a play in AI training with its GPUs, we think the demand will outstrip the Nvidia supply, which means despite the massive advantage that the Nvidia AI software stack has over AMD that the latter’s GPUs are going to get some AI supply wins. The predecessor “Aldebaran” GPUs already have some impressive HPC design wins for AMD, notably in the “Frontier” exascale system at Oak Ridge National Laboratory, with four of these dual-chip GPUs attached to a custom “Trento” Epyc CPU to create a more loosely coupled hybrid compute engine. (There are others.) And we think the intense demand for Nvidia GPUs for AI workloads is going to actually leave an opening for AMD to win some deals as demand outstrips supply.
People are not going to be any more patient about adding generative AI to their workloads today than they were in the late 1990s and early 2000s to add Web infrastructure to modernize their applications to deploy interfaces for them on the Internet. The difference this time around is that the datacenter is not transforming itself into a general purpose X86 compute substrate, but rather is becoming more and more of an ecosystem of competing and complementary architectures that are woven together to provide the overall best possible bang for the buck across a wider variety of workloads.
We don’t know a lot about the MI300 series as yet, but in January AMD talked a little bit about the devices, which we covered here. We have an image of one of the devices, and we know that one of them will have 8X the AI performance and 5X the AI performance per watt of the existing MI250X GPU accelerator used in the Frontier system. We know that one of the MI300 series has 146 billion transistors across its nine chiplets . A big chunk of that transistor count, we think, is implemented in four 6 nanometer tiles that interconnect the CPU and GPU compute elements that also has Infinity Cache etched on them. It is hard to say how many transistors this cache uses up, but we look forward to finding out.
By the way, we think the MI300A is called that to designate it is an APU version – meaning a combination of CPU and GPU cores on a single package – of AMD’s flagship parallel compute engine. This implies that there are going to be non-APU, GPU-only versions of the Antares GPU, perhaps with a maximum of eight GPU chiplets riding atop those four interconnect and cache chips, shown below in what we think is the MI300A:

To be very precise in AMD’s language from earlier this year, that 8X and 5X number was based on tests for the MI250X GPU and modeled performance for the GPU portions of the MI300A complex. And to be very specific, this is what AMD said: “Measurements by AMD Performance Labs June 4, 2022, on current specification and/or estimation for estimated delivered FP8 floating point performance with structure sparsity supported for AMD Instinct MI300 vs. MI250X FP16 (306.4 estimated delivered TFLOPS based on 80% of peak theoretical floating-point performance). MI300 performance based on preliminary estimates and expectations. Final performance may vary.”
And to be even more specific, here are the notes to the three claims that AMD has made regarding the MI300 series to date:

We wonder what happened to MI300-002, and we searched the Internet for it and could not find it.
Based on this data above and the conjecture engine stuck in our brain lobes, here is our table estimating what the feeds and speeds of what the MI300 and MI300A might look like given what AMD has said so far, with a fair amount of guessing shown in bold red italics as usual.
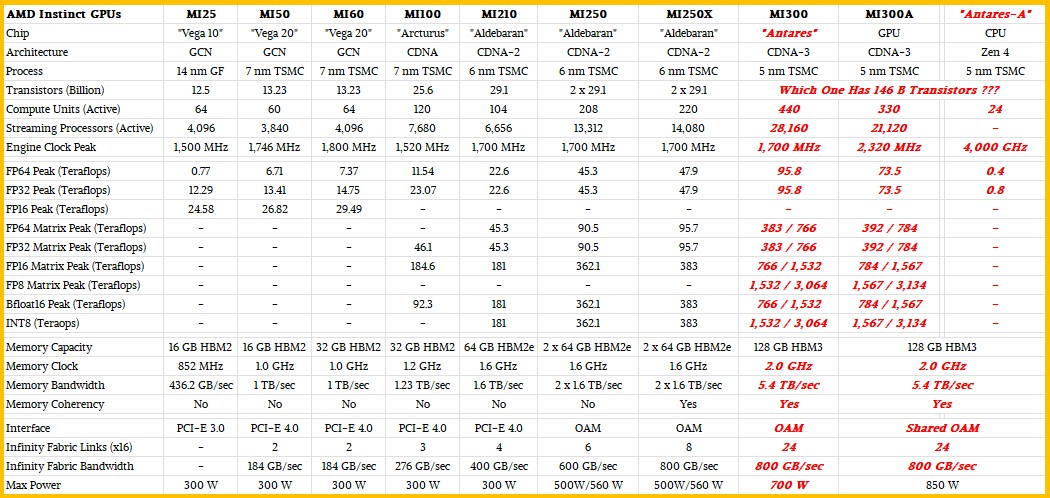
In an earlier version of this story, we assumed that all of the comments AMD made were about the MI300A, but some of them were about the MI300. So we have done our best to see what these two chip complexes might look like. We make no warranties, and offer this up as the thought experiment that it is.
We had too many streaming processors and compute units in our earlier chart, but we think this is correct. Sorry about that. We added sparsity matrix processing at the end, but forgot to take the 2X factor for that processing out.
We think the MI300 has eight GPU tiles for a total of 440 compute units and 28,160 streaming processors, yielding 3,064 teraflops peak on FP8 and 3,064 teraops peak on INT8 processing commonly used for AI inference and, for some applications with FP8 support, also for AI training. We think this chip runs at the same 1.7 GHz clock speed as the MI250X it replaces, and that it will have 2X the vector FP64 and FP32 processing capacity of the MI250X.
With the MI300A, two of the GPU chips are popped off, reducing the compute units to 330 and the streaming processors to 21,120. But, because we think Lawrence Livermore was willing to sacrifice some heat to get the CPU and GPU on the same high bandwidth memory, we think AMD is going to crank the clock speed on those six GPUs to push the performance a little bit beyond that in the MI300. Our math suggests 2.32 GHz will do the trick, yielding the 8X performance and 5X the performance per watt figures that AMD has talked about in its claims.
Just like Nvidia boosted the performance multiple higher on the matrix math units in the H100 GPUs compared to the vector units, we think AMD will do the same thing with the MI300A hybrid compute engine. So the vector units might only see a 2X improvement. That is another way of saying that many HPC workloads will not accelerate nearly as much as AI training workloads, unless and until they are tweaked to run on the matrix math units.
Now, let’s talk about money.
In our analysis back in December 2021, when the MI250Xs were first shipping into the Oak Ridge to build out the Frontier machine, we estimated that one of these GPU motors might have a list price in the range of $14,500, a few grand more than the Nvidia “Ampere” A100 SXM4 GPU accelerator, which was selling for $12,000 at the time. In the wake of the H100 announcement in March 2022, we estimated that a case could be made to charge anywhere from $19,000 to $30,000 for a top-end H100 SXM5 (which you can’t buy separately from an HGX system board), with the PCI-Express versions of the H100 GPUs perhaps worth somewhere from $15,000 to $24,000. At the time, the price of the A100 SXM4 had risen to around $15,000 because of rising demand. And only a few weeks ago, the PCI-Express versions of the H100 were being auctioned on eBay for more than $40,000 a pop. Which is crazy.
The situation is worse than the used car market here in the United States, and it is a kind of inflation that comes from too much demand and too little supply. A situation that vendors love when they know they can’t make enough units anyway. The hyperscalers and cloud builders are rationing access to GPUs among their own developers, and we would not be surprised to see price increases for GPU capacity in the cloud.
When it comes to FP8 performance with sparsity on, the MI300A will deliver around 3.1 petaflops of peak theoretical performance, but against 128 GB of HBM3 memory with maybe somewhere around 5.4 TB/sec of bandwidth. The Nvidia H100 SXM5 unit has 80 GB of HBM3 memory with 3 TB/sec of bandwidth, and is rated a 4 petaflops of peak performance with sparsity on at the FP8 data resolution and processing. The AMD device has 25 percent less peak performance, but it has 60 percent more memory capacity and maybe 80 percent more memory bandwidth if all of those eight HBM3 stacks on the device can be fully populated. (We sure hope so.) We think a lot of AI shops will be perfectly fine sacrificing a little peak performance for more bandwidth and capacity on the memory, which helps drive actual AI training performance.
![]()
What we can say for sure is that El Capitan is first in line for the MI300A compute engines, and to break through 2.1 exaflops peak at plain vanilla 64-bit double precision floating point will require 28,600 sockets, and in this case, a socket is a node.
Hewlett Packard Enterprise’s Cray division is building the El Capitan machine, and it likes to put many compute engines on a node. The Frontier system blade, for instance, has a pair of nodes, each with one Trento CPU and four MI250X GPUs, for a total of ten devices and about 5,300 watts. With the Slingshot 11 network interface cards, call it maybe 6,000 watts per blade just for the sake of argument. If there are eight MI300As on a blade at 850 watts, that would be somewhere around 6,800 watts just for the compute engines. Still within the cooling specs of the “Shasta” Cray EX frames is our guess. Because this is a water cooled machine, we think eight MI300As can fit on the blade with their Slingshot 11 network interface cards. We look forward to finding out.
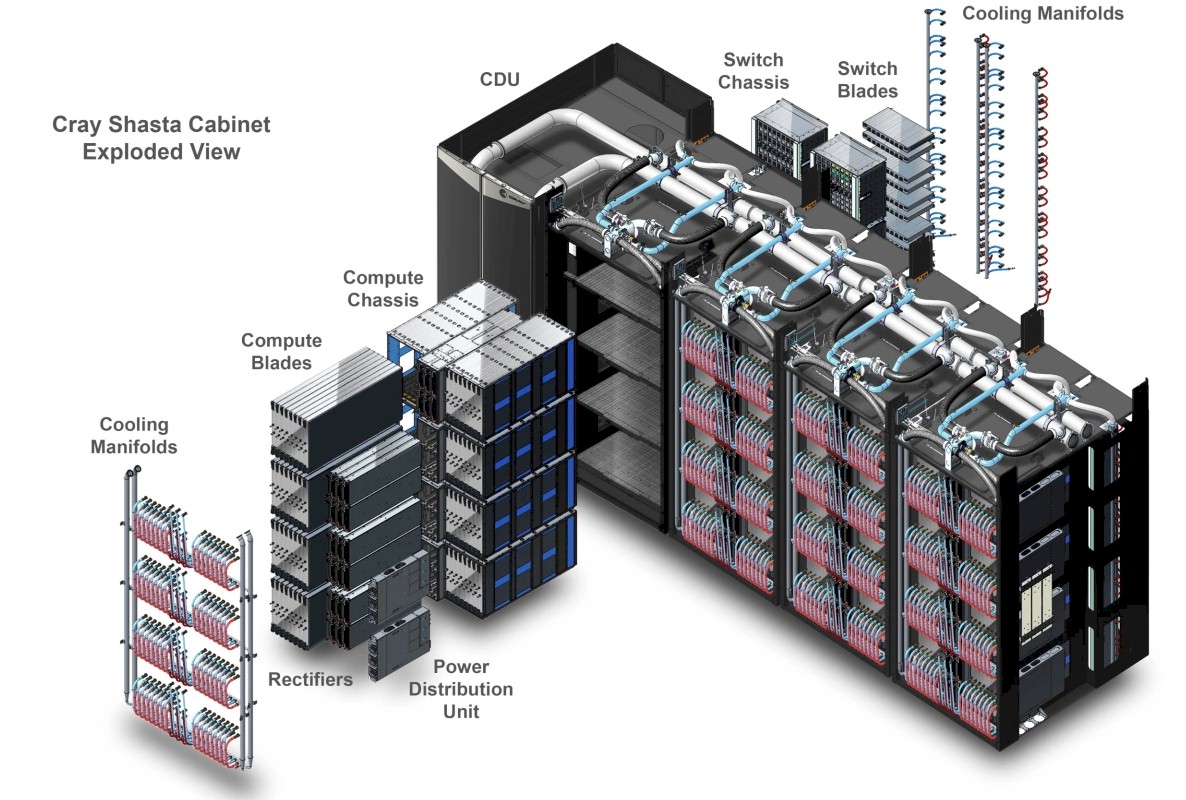
With eight MI300A devices per blade and 64 blades per cabinet , as shown above in the Cray EX exploded view, then that is 56 cabinets (rounding up). Cray has historically liked to sell capability class machines in the 100 cabinet range, and have machines that can scale to 200 cabinets so customers feel like they have some headroom, including storage. If El Capitan comes in at 2.3 exaflops peak, that will be 62 cabinets, and 2.5 exaflops will be 67 cabinets. With storage, we strongly suspect that El Capitan will be around 100 cabinets.
The current “Sierra” system, which is now approaching five years old because El Capitan is coming to market about a year later than planned (but presumably still within its $600 million budget) has 4,320 nodes, each with two Power9 processors from IBM and four “Volta” V100 GPU accelerators from Nvidia. That is a total of 17,280 GPUs in Sierra, and if our guesses about MI300A’s FP64 performance are correct – and we are the first to admit that this is just a hunch – then that is only 65 percent more GPU sockets in El Capitan than were in Sierra. But, there are six logical GPUs in each El Capitan socket, so that is more like 171,600 GPUs to deliver 2.1 exaflops. That would be 16.9X more raw FP64 performance at a 4.8X increase in price across the two systems, delivered by a factor of 9.9X increase in GPU concurrency. El Capitan has to deliver at least 10X more oomph on performance than Sierra and do so in less than a 40 megawatt thermal envelope. If we are right about all of this, then a 2.1 exaflops El Capitan would come in at around 24.3 megawatts just for the compute engines.
And as a price check on this whole thing, if 85 percent of the cost of the El Capitan machine is the CPU-GPU compute engines, and there are 28,600 of them, then that is around $17,800 a pop for them. And there is no way the hyperscalers and cloud builders will pay less for them than the US national labs that are basically sponsoring AMD’s foray into the upper echelons of HPC are paying. (That is a lot of “ifs” and we well know it.)
In the past, we would actually figure out the list price of a GPU from the supercomputing deals by reversing the HPC national lab deep discount. With the Volta V100 accelerators used in Sierra, for instance, the GPUs listed for around $7,500 but sold to Lawrence Livermore and Oak Ridge for around $4,000 a pop. And so list price for the MI300A, if that old discount level prevailed, might be above $33,500. We think the discounting is less steep because AMD added a lot more compute to the MI300A engine and the price was also a lot lower per unit – list price was more like street price because AMD needs to be aggressive to displace Nvidia.
Remember that when the original El Capitan deal was announced in August 2019 for delivery in late 2022 with acceptance by the end of 2023, it was specified as machine with 1.5 exaflops of sustained performance and around 30 megawatts of power consumption just to run the system.
This all leaves us with three questions. One: How many MI300A devices can AMD make? If it is a lot more than are scheduled to go into El Capitan, then it can set their price and sell them all. And two: Will AMD sell them at an aggressive price or push for the price that the market can bear?
It is not hard to answer the second question, is it? Not in this bull GPU market where AI is going to be absolutely immune from recession. AI may even accelerate the recession, should it come to pass, if it is increasingly successful at replacing people. . . . So far, neither a real recession nor an AI accelerated one has happened.
The third question is this: Will the MI300 have essentially the same price as the MI300A? It is very likely.




MI300 seems a bit expensive (for an individual), but should wipe the floor with the competition, clean-off, and it will be great to get the low-down on its State of the Oomph-nion from isc-2023! Speaking of which, TNP deserves to gift itself a free trip to Hamburg in celebration of 6-months of heroic journalism (since the November List), and partake in local HPC gastronomy there, particularly the eponymous delicacy immortalized by JFK in these words: “Ich bin ein Hamburger!” (or somesuch), delicious with freedom fries, and even french ones! The conference keynote by Dan Reed will revisit TNP’s recent article on HPC funding (the Zed issue), and Tuesday’s keynote by Google may re-address the “bissed moat” strategic challenge, particularly apt in view of this port city’s recently completed elbphilarmonie, whose shape evokes the hull of large sailboats, not to be missed on a town visit. Jack Dongarra will even talk about HW/SW for mixed-precision HPC; another topic nailed by TNP. Bon voyage and bon appetit (eh-eh-eh)!
Maybe the drop off in demand for consumer tech and server cpus will open up some fab capacity for printing out a few more GPUs.