
Here is an old saw that we bring out of the toolbox every now and then, and we use it just enough so it has never really gotten rusty and it can cut through a lot of crap to make a point: The datacenter, and perhaps all clients, would have been better off if InfiniBand had just become the ubiquitous I/O switched fabric standard it was designed to be back in the late 1990s.
But, for a lot of self-serving interests, that did not happen. There were a few notable exceptions where InfiniBand was used as a kind of system backbone (by IBM, Sun Microsystems, and Unisys are the ones we remember), but InfiniBand only survived thanks to a few startups (SilverStream/QLogic/Intel/Cornelis Networks and Mellanox/Nvidia) and only in a niche as a high performance, low latency alternative to Ethernet in distributed computing systems.
InfiniBand was instrumental in high performance computing in its many guises because of Remote Direct Memory Access, or RDMA, which allows for data to be moved from the memory of one server to another server directly over the InfiniBand network without going through the network driver stack on each server’s operating system. RDMA is what gives InfiniBand low latency, and obviously it is very powerful when used in conjunction with the Message Passing Interface (MPI) protocol for distributing workloads across CPU cores and GPU streaming multiprocessors in distributed systems.
There were two attempts to converge the benefits of InfiniBand into Ethernet. The first was iWARP, which put what was in essence a clone of chunks of the InfiniBand RDMA protocol on Ethernet network adapters, which were given hardware acceleration for Ethernet TCP/IP processing, thereby removing most of the operating system overhead from using Ethernet. Offloading a TCP/IP stack was difficult and expensive (computationally and economically), and thus iWARP never got much traction. (And here we are, a decade later, and we can have fat DPUs thanks to an even slowing Moore’s Law.)
But the idea of making Ethernet more like InfiniBand didn’t go away. A little more than a decade ago, RDMA over Converged Ethernet, or RoCE, entered the scene, adding an InfiniBand-like transport layer to the UDP protocol that is also part of the Ethernet stack. RoCE first started taking off in 2015, when we started The Next Platform and when a whole lot of new things were going on. People have been complaining about RoCE since that time – particularly the hyperscalers and cloud builders but also some in the HPC jet set – and that has driven RoCE innovation forward some.
But a group of HPC and network ASIC design luminaries has just released a very interesting paper called Datacenter Ethernet And RDMA: Issues At Hyperscale that basically says HPC simulation and modeling, AI training and inference, and storage workloads running at scale have issues with RoCE and they need to be fixed. But more than that, the authors argue that it is time to do a real convergence of HPC and hyperscale datacenter fabrics. (And maybe this time we can get a better acronym that is a proper noun and lot like a ransom note? What’s wrong with Etherfabric, for instance?)
The authors of the paper know a thing or two about what they speak. And many of them saw the InfiniBand movie the first time (like we did and many of you did, too). To be specific, we have Mark Griswold (formerly of Cisco Systems), Vahid Tabatabaee, Mohan Kalkunte, and Surendra Anubolu (also from Cisco way back) of Broadcom; Duncan Roweth (formerly of Cray, Quadrics, and Meiko), Keith Underwood (formerly of Sandia National Labs, Intel, and Cray), and Bob Alverson (formerly of Cray and Tera Computer) of Hewlett Packard Enterprise; Torsten Hoefler and Siyan Shen of ETH Zürich; and Abdul Kabbani (formerly of Google), Moray McLaren (also formerly of Google but also Meiko, Quadrics, and HPE), and Steve Scott (formerly at Cray, Nvidia, and Google) of Microsoft.
These people all network, as you can see from those short bios. And clearly they talk, and they complain about the shortcomings of Ethernet when it comes to RDMA. And more than a few of them worked together at Cray on the “Slingshot” variant of Ethernet that is at the heart of some of the largest supercomputers in the world these days.
“Datacenters have experienced a massive growth during the last decade and the number of connected machines exceeds the size of the largest supercomputers today,” the authors write in what has to go down as one of the biggest understatements we have seen in a while, given that Google, AWS, or Microsoft could each by themselves own the entire Top500 supercomputing rankings if any of them were so inclined. And maybe with only a few regions. “While there remain some differences, the networking requirements of such hyperscale mega-datacenters and supercomputers are quite similar. Yet, supercomputers are traditionally connected using special-purpose interconnects while datacenters build on Ethernet. Due to similar requirements and economies of scale, both continue to grow closer together with each new technology generation. We believe now is the right time to re-think the basic assumptions and architecture for a converged interconnect.”
Yes, you are having flashbacks to 1999. It’s OK. You are in a safe place, surrounded by people who love you. . . .
If we all dream hard enough, and do it together through some kind of standards body, maybe we can get the InfiniBand we all wanted to begin with. (Well, not Cisco.) CXL would not have been necessary because it would have already been built in for decades. Chew on that for a while as you watch all of the pretty lights on the wall and feel at one with the Earth.
The Upper Echelon
For most enterprises, most of the time, 10 Gb/sec and even 25 Gb/sec ports on servers are fine, and 10 Gb/sec ports out to PCs is sufficient. It is crazy just how much 10 Gb/sec and slower Ethernet switching gear is still sold in the world, and this is why.
But for a segment of the market – and the segment that drives innovation and an increasingly large part of the revenue stream for switch ASIC makers and switch makers – 100 Gb/sec Ethernet is the bare minimum and if they could have PCI-Express 6.0 slots and 800 Gb/sec Ethernet ports today, they would take them and whinge a bit but pay thousands and thousands of dollars per port to get them. Their applications – HPC and AI and storage – are driving 100X more bandwidth and 10X higher message rates, argue the paper’s authors, and the “simple assumptions on load balancing, congestion control, and error handling made decades ago do not hold for today’s networks.”
If anything, the paper illustrates the ideas that the network is indeed the computer and that trying to make a lossy, packet-dropping technology like Ethernet behave like the orderly, lossless InfiniBand fabric has involved doing unnatural acts that have unintended consequences. There are many times that this paper uses exclamation points, and they are perfectly warranted given the exasperation that network designers often have as their only means of coping with those unintended consequences.
Priority Flow Control, or PFC, was the solution to making Ethernet lossless and seems to be a big part of the problem. HPC, AI, and storage applications do not like dropped packets, and Ethernet was explicitly designed to not care, it can always retransmit a dropped packet. This was fine on a local area network where you share a file or print something in the office, but such an attitude will make these datacenter-spanning workloads fall down and go boom. With PFC, the idea is to help Ethernet not drop packets on the floor by putting big fat wonking expensive buffers on the switches and praying that they don’t fill up.
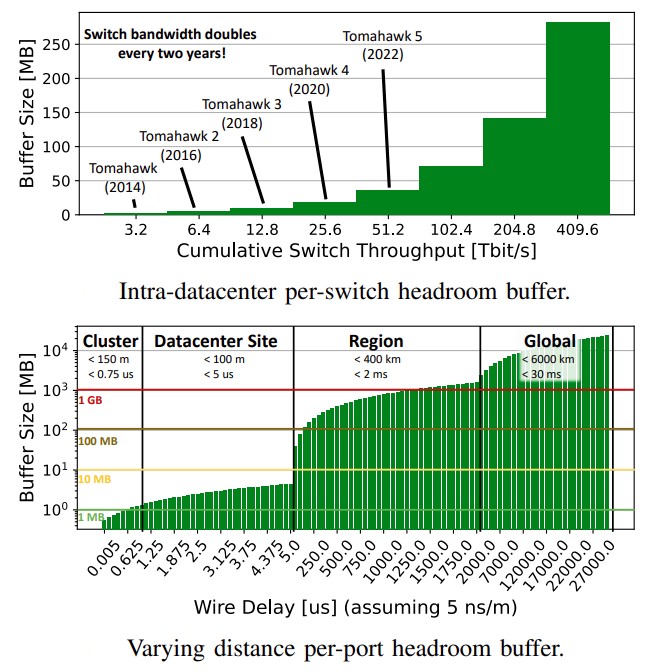
Here is a good one, pulled right from the paper.
“Datacenter switches traditionally have large (deep) buffers to accommodate traffic bursts without dropping to accommodate the slow end-to-end rate adjustment. On the other hand, switches used in HPC usually operate lossless with very shallow buffers and stiff back-pressure due to their reliable link-level flow control mechanisms. Also, HPC network topologies have usually lower diameter than data[1]center deployments. Thus, HPC deployments support lower-latency operations because small packets are less likely to wait in buffers behind longer flows. Datacenter networks with RoCE are often combining both inefficiently: they use a lossless transport with all its issues with relatively large-buffered switches. Many modern congestion control mechanisms thus aim at keeping the buffer occupancy generally low, leaving this very expensive resource unused!”
This is the kind of thing that will drive a distributed system architect mad.
Another thing that needs a looksee is forward error correction, or FEC, with the future Etherband, which is another possible name for this. (Infininet also works.)
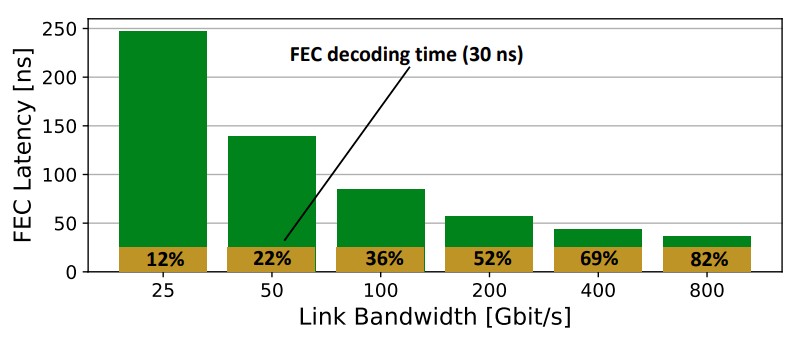
As you can see, to support higher bandwidths, we are going to higher signaling rates on the ports, and the latency of the FEC has to go down. But as you can see, the FEC decoding is eating more and more of the total FEC latency, and there may have to be a more complex FEC mechanism that adds more latency. (We note, as did the paper, that PCI-Express 6.0 and 7.0 has come up with a novel way of encoding and correcting errors and we think it may be adopted in Ethernet and InfiniBand.
The chart below from the paper is interesting in that it shows the bandwidth delay product – literally the data link capacity in bits per second multiplied by the round trip delay time in seconds. Keeping a network business with a high round trip time is problematic, and this shows how much Microsoft Azure HPC loves InfiniBand, but perhaps not at the highest of bandwidths.
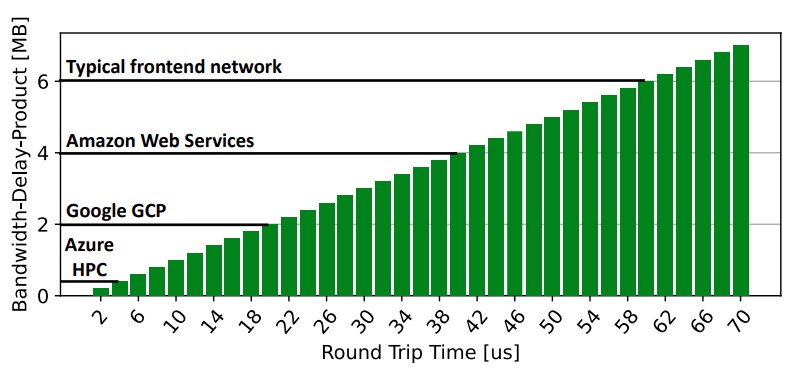
This chart, as it turns out, comes from another paper, where Hoefler was a contributor, published last year called Noise In The Clouds: Influence Of Network Performance Variability On Application Scalability.
Given the numerous issues outlined in gorpy detail in the paper, here are the conclusions that the researchers behind the paper come to:
“This next-generation Ethernet will likely support lossy and lossless transport modes for RDMA connections to allow intelligent switch[1]buffer management. This will make the provisioning of headroom buffer optional and avoid the other problems such as victim flows and congestion trees of lossless networking. Next-generation Ethernet is also unlikely to adopt go back-n retransmission semantics but opt for more fine-grained mechanisms such as selective acknowledgments. Furthermore, it will likely make congestion management part of the specification. Special attention will be paid to colocation with other flows, especially in lossy traffic classes. The protocols will be designed in a flexible way to support smart networking stacks and security will finally become a first-class citizen.”
We are trying to round up a few of these researchers to see how this might actually happen, and when.
In the meantime, InfiniBand or Slingshot when you can, and Ethernet when you must.


Lawrence Livermore To Surpass 2 Exaflops With AMD Compute
As the steward of the nuclear weapon arsenal for the United States government, it is probably not an overstatement to say that Lawrence Livermore National Laboratory, one of the main supercomputer and scientific research facilities operated by the Department of Energy, is keenly interested in bang for the buck. And …

This Switcheroo Doesn’t Get Old
Any company that holds more than a quarter of a market – by money or shipments – is doing pretty well. Those few that have somewhere between a third and half of the market are exceptional. Those that attain 65 percent are rare indeed. And those that have 85 percent …
After The 2022 Bump, Arista Is Back To The Grind In 2023
For Arista Networks, the poster-child of hyperscaler and cloud build networking that, more than any other vendor, has championed merchant silicon and Linux as the basis of a modular network operating system, 2022 was a bumper crop year. This year, there are many new things going on, but the compares …
Remember InfiniCortex (2014-2016)?
Marek T. Michalewicz, et al , „InfiniCortex: concurrent supercomputing across the globe utilising trans-continental InfiniBand and Galaxy of Supercomputers”, Supercomputing 2014: New Orleans, LA, USA November 2014, DOI: 10.13140/2.1.3267.7444
Marek T. Michalewicz, et al, „InfiniCortex: Present and Future”, CF ’16 Proceedings of the ACM International Conference on Computing Frontiers, Pages 267-273, 2016, ACM New York, NY, USA ISBN: 978-1-4503-4128-8 doi: 10.1145/2903150.2912887
Gabriel Noaje, et al, “InfiniCortex – From Proof-of-Concept to Production”, Supercomputing Frontiers and Innovations, 87-102, Vol. 4 no. 2 (2017)
Kenneth Hon Kim Ban, et al, “InfiniCloud: Leveraging the Global InfiniCortex Fabric and OpenStack Cloud for Borderless High Performance Computing of Genomic Data”, Supercomputing Frontiers and Innovations, 2 no. 3 (2015) DOI: 10.14529/jsfi150302
Jakub Chrzeszczyk et al. “InfiniCloud 2.0: distributing High Performance Computing across continents”, Supercomputing Frontiers and Innovations, 3 no. 2 (2016) DOI: 10.14529/jsfi160204