
The IT industry, like every other industry we suppose, is in a constant state of dealing with the next bottleneck. It is a perpetual game of Whac-a-Mole – a pessimist might say Sisyphusian at its core, an optimist probably tries not to think about it too hard and deal with the system problem at hand. But what do you do with the hammer when all of the moles pop their heads up at the same time?
Or, to be more literal, as the title above suggests, what do we do when processors and their SRAM as well as main memory stop getting cheaper as they have for many decades? How do system architects and those building and buying datacenter infrastructure not get depressed in this Post-Moore’s Law era?
In the past month, we keep seeing the same flattened curve again and again, and it is beginning to feel like a haunting or a curse. We have been aware of the slowing of Moore’s Law for years and the challenge it represents for system architecture on so many fronts – compute, memory, storage, networking, you name it – and we have been cautioning that transistors are going to start getting more expensive. But what is more striking, at least during late 2022 and early 2023, is that we have seen a series of stories showing that the cost of a unit of compute, fast SRAM memory, and slow DRAM memory is holding steady and not going down as it ought to.
The first time we saw this flattening curve pop up in recent weeks was a report by WikiChip Fuse from the International Electron Devices Meeting in December, which outlined the difficulties of shrinking SRAM cell area:
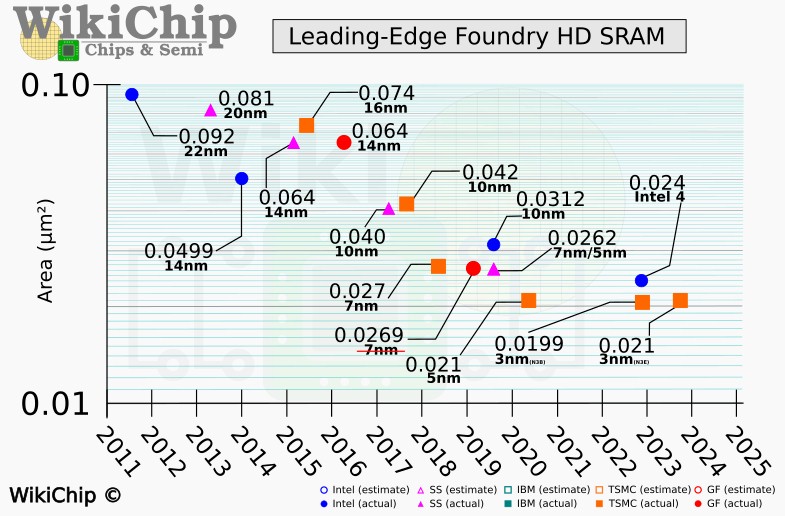
Now this chart doesn’t talk about costs explicitly, but with SRAM representing somewhere between 30 percent and 40 percent of the transistors on a typical compute engine, SRAM represents a big portion of the cost of a chip and we all know that the cost of transistors is going up with each successive generation of processes starting somewhere around the 7 nanometer node a few years ago. It remains to be seen if SRAM transistor density can be improved – the folks at WikiChip Fuse seemed to think that Taiwan Semiconductor Manufacturing Co would pull a rabbit out of the hat and get a density increase of better than the projected 5 percent with its 3 nanometer 3NE process. And if it can do that, we still think that the odds are that the cost of SRAM will go up, not down. And if it does go down, by some miracle, it won’t be by a lot.
Then today, this chart from Dan Ernst, formerly advanced technology architect at Cray and now part of the future architecture team at Microsoft Azure, put this chart out on his Twitter feed as a response to an article by Dylan Patel at SemiAnalysis. Here is the chart Ernst put out about DRAM pricing:
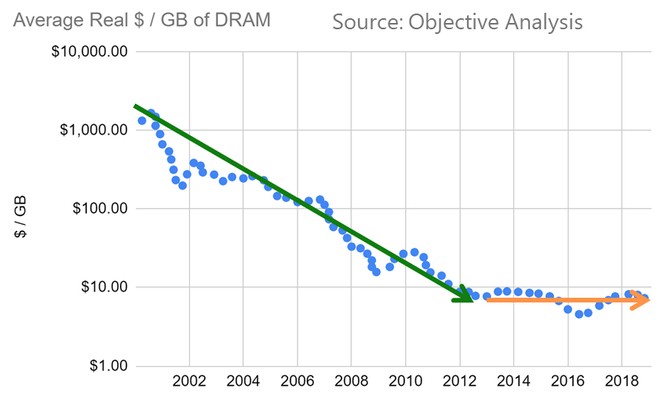
And here is the one Patel put out that prompted Ernst:
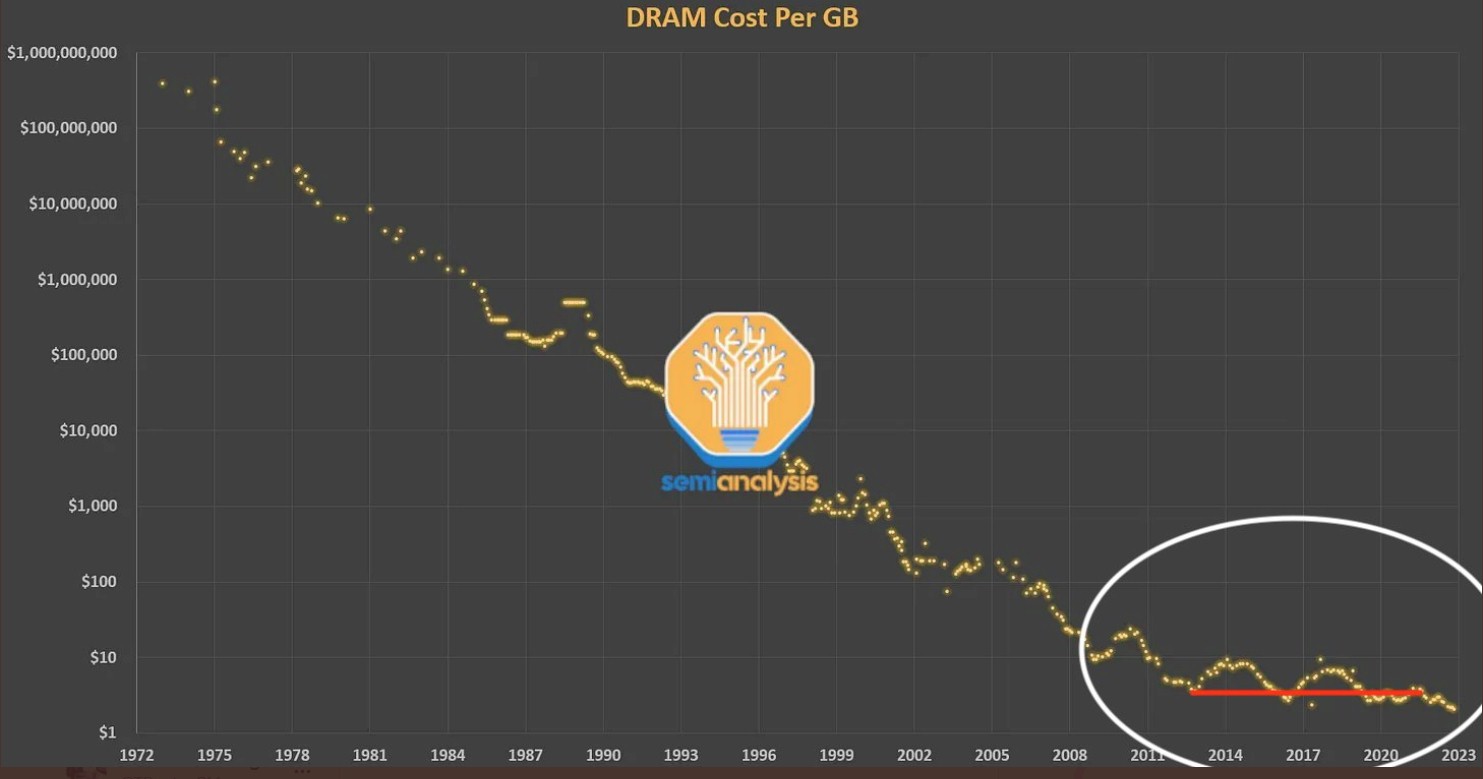
These two charts popped up a day after we had done our own analysis of the performance and price/performance of the Intel Xeon and Xeon SP server CPU line, in which the standard, mainstream parts have followed this pricing curve where the cost of a unit of work has flattened out:
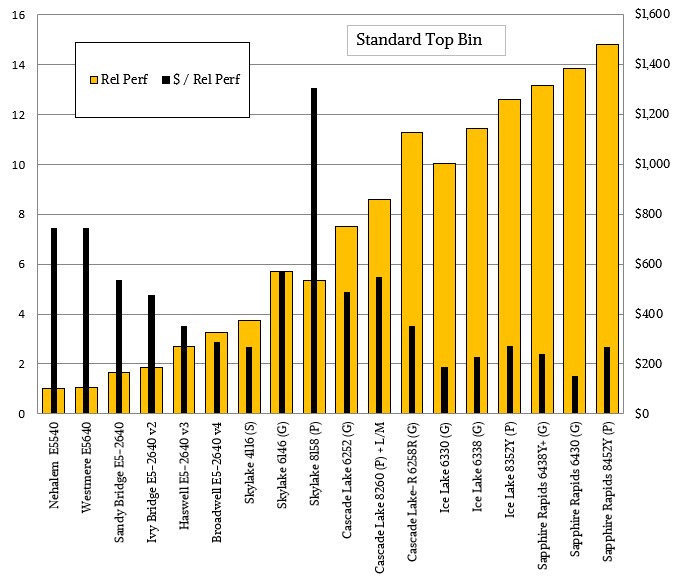
And the chips with high core counts followed this much less aggressive price curve and a combination of opportunistic pricing and higher packaging costs and lower yields have forced Intel to still charge a premium for the Xeon SP processors with high core counts:
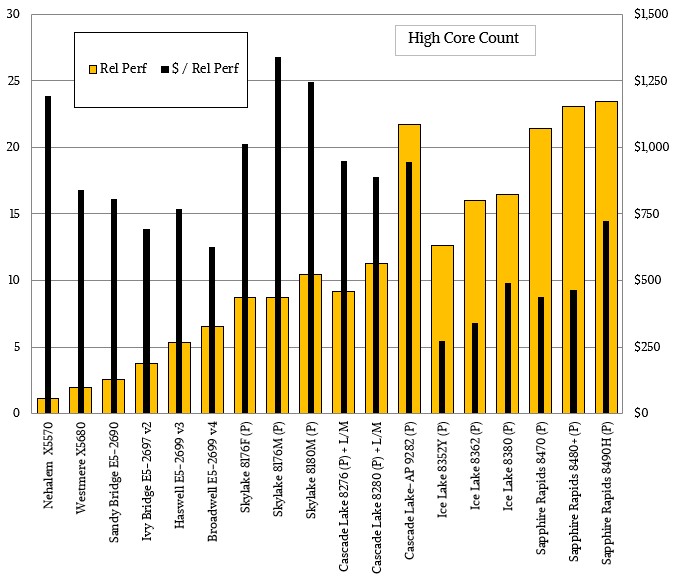
Depending on where you draw the lines and depending on chip architecture and implementation, Moore’s Law price scaling stopped somewhere around 2016 or so. It is hard to tell with Intel data because it had an effective monopoly on X86 compute until 2018 or 2019. But clearly, Intel is not trying to drive down the cost of compute as it did when it moved from 45 nanometer “Nehalem” Xeon E5500s in 2009 to the 10 nanometer “Sapphire Rapids” Xeon SPs here in 2023.
As we are fond of pointing out, Moore’s Law was not really about transistor shrinking so much as it was about reducing the cost of transistors so that more of them, running progressively faster, could be brought to bear to solve more complex and capacious computing problems. The economics drives the IT industry – density alone does not. Creating compute or memory density in and of itself doesn’t help all that much, but creating cheaper and more dense devices has worked wonders in the six decades of commercial computing.
What do we do when this has stopped, and may stop on all fronts? What happens when the cost per bit goes up on switch ASICs? We know that day is coming. What do we do when compute engines have to get hotter, bigger, and more expensive? Do we just keep getting more and more parallel and build bigger and more expensive systems?
It is the money that matters, and we want to talk about some smart people about this topic in an upcoming series of video roundtables that we will publish soon. So if you are interested and you know something, send me an email.


Great Scott: Spanning Supercomputing And Clouds
System architects that live in the Seattle area who don’t want to uproot their lives and move to California or Texas or New York or maybe possibly Illinois or Oregon or even overseas to Japan or China have a fairly small number of job opportunities. But, the good news, as …
Is Microsoft’s SONiC Winning The War Of The NOSes?
There are many things that are ironic in the IT business. Too many to count, some days. And maybe it is just because many of us are attending the virtual Open Compute Summit driven in large part by Facebook and Microsoft (still). But it looks like momentum is building for …

Chiplet Cloud Can Bring The Cost Of LLMs Way Down
If Nvidia and AMD are licking their lips thinking about all of the GPUs they can sell to the hyperscalers and cloud builders to support their huge aspirations in generative AI – particularly when it comes to the OpenAI GPT large language model that is the centerpiece of all of …
energy get more expensive in the future breakeveb point of economics of energy use compute or memory van newer generations of compute still be at less energy use
when it is about best value for money we could stay on 28 nm node forever
Well, that’s one answer. HA!
Decrease in compute cost need not come directly from the chips itself.
If cost per unit of compute and energy usage per unit of compute stayed the same, other factors could be changed to decrease cost.
1. You wouldn’t need to buy new hardware as often and could stretch out the upgrade cycle without being at acost disadvantage to your competitors.
2. More data centers could increase their PUE. More free air cooling, more minimally filtered air, higher operating temperatures.
3. Solar and wind, once you’ve paid the initial cost of solar, maintenance is minimal and the power is essentially free, albeit intermittent. This intermittency will create periods of negative power pricing, when you will be paid to use the energy. This already happens in Texas, they have a lot of wind on the grid, (and other places)
4. More efficient layouts of servers, better airflow, with the possibility of liquid cooling an entire rack, and having a heat exchanger hooked up to a data center cold source.
5. Geographical and time shifting of compute. Move the job to a geographical location with cheaper energy, this could be where the sun is shining, or more towards the poles, where you can use free air cooling. In terms of time shifting, run the job during the day when solar makes energy free, and then turn off the servers at night. Google was doing this with Spanner over a decade ago.
6. Use the data center to heat buildings. Especially if you were water cooling your racks with a heat exchanger from the rack to datacenter cooling fluid, you could run the data center cooling fluid that has been heated up through a heat pump as a heat source for building heating, and then if necessary, cool the data center cooling fluid further before recirculating it in the data center.
7. More efficient software. Write new software that functions to the specification and doesn’t have 20 or 30 years of accumulated code revisions. Get more software engineers working on better algorithms for code libraries. Do more work to make compilers more efficient and recognize parallelism. Have software engineers optimize the more intensive pieces of code in a program, the things that the program takes the most time doing, or what’s using the most resources.
There’s other ways forward too, molecular computing, DNA computing, light-based computing, quantum, sapphire as opposed to silicon chips, analog computer chips that do processing instead of just signal conversion.
Further, there isn’t enough funding of basic scientific research. Without the Soviet Union to urge the United States forward, the United States has gotten lazy, and quit funding research.
We will see further cost decreases in compute.
So, you want to be on a roundtable? HA!
Analog computing may be the way forward for AI and interference.
I honestly can’t tell whether you were taking me seriously or not regarding my previous comment Timothy Pickett Morgan.
Here’s a 10×10 mm analog chip in silicon, doing programmable computation with retransmission gates. (Yes, I know Wired, but this is real) https://www.wired.com/story/unbelievable-zombie-comeback-analog-computing/amp
“A key innovation of Cowan’s was making the chip reconfigurable—or programmable. Old-school analog computers had used clunky patch cords on plug boards. Cowan did the same thing in miniature, between areas on the chip itself, using a preexisting technology known as transmission gates. These can work as solid-state switches to connect the output from processing block A to the input of block B, or block C, or any other block you choose.”
“His second innovation was to make his analog chip compatible with an off-the-shelf digital computer, which could help to circumvent limits on precision. “You could get an approximate analog solution as a starting point,” Cowan explained, “and feed that into the digital computer as a guess, because iterative routines converge faster from a good guess.” The end result of his great labor was etched onto a silicon wafer measuring a very respectable 10 millimeters by 10 millimeters. “Remarkably,” he told me, “it did work.””
Analog is waiting in the wings looking for believers and funding, for when digital hits the wall.
Are you up on your differential equations? There’s boards available to people who could make use of them, that would make for a very interesting review.
I think in all seriousness, analog is interesting. I am most definitely not up on my differential equations — that was a long, long time ago — and this method reminds me of how I was taught physics. When my cranky British professor threw the chalk at you, you were going to be the one up in front of the class solving problems for the day. He just stood by and nudged you here or there. But before you started doing the math, he would make you walk through an estimate of how to solve the problem and what you thought an approximate answer might look like. And armed with that estimate, you checked to see if you math was converging into that direction. At first, we all had panic attacks, and then, it got to be fun. And today, I look at every problem this way, Aslan. And of course I was taking you seriously, but with the kind of wry humor that is encouraging, not at all dismissive or mocking. I don’t roll that way.
I hope that Intel’s 10nm process (Intel 7) is a bit of an outlier, and that the path of increasing efficiency, with reduced feature size, resumes with Intel 4. From the high-clock-speed table of the “Hefty Premium” article, and normalizing to 4 cores, it seems that efficiency (1K perf/Watt) improved by a factor of 2 from 45nm (Nehalem, approx. 10) to 14nm (Skylake, approx. 20), but it slightly dis-improved at 10nm (Sapphire, approx. 15, for 4 cores — better than 45nm, but not as good as 14nm). Hopefully “Intel 4” will bring the missing “single core” efficiency back, despite SRAM (maybe) not scaling further area-wise.
I get the idea of normalizing to four cores, but you can’t actually have just four cores. Or, if you turn four off, you double the effective cost of the remaining cores. I am with you about Intel 4, but Intel is not using that on Xeon SPs. They are moving straight to Intel 3 with Granite Rapids. Emerald Rapids should be Intel 4 and is just another refined Intel 7. Intel will try to close the gap some with Granite Rapids and Turin, I guess.
Ooops! You are correct — I mis-interpreted and then mis-calculated too. Re-thinking about it suggests Intel 7 (10nm) being 1.25 times more efficient that 14nm (comparing the 8-core Cascade Lake, Ice Lake, and Sapphire Rapids). So things are o.k. efficiency-wise (continued improvements!).
This is a group effort, and I appreciate you.
Good update and summary. It’s been clear to those most closely following the various metrics of Moore’s Law (SpecInt&SpectFP per watt and per dollar, DRAM costs, HDD costs, Flash Costs, transistor speed vs power, instructions per clock, clock rate advancement @ power limits, etc…) that Moore’s Law has been ending in stages. That’s why it’s so hard for many to see it, because they can often point to one last iota of advancement and say “See, well that thing got better, Moore’s Law is just fine!”. The last element that has been advancing at a reasonable pace is the number of transistors in a package (ignoring cost and overall performance). But that is starting to stumble. Most sensible folks see it, others look to nano-this, quantum-that, 3D-whatever from the various sources of hype generation for hope not really knowing how far we are from realizing a robust alternative. The limitations of physics and economics will have the final word I’m afraid. It sure was a fun run though.
Shouldn’t EUV 0.55 in 2025/2026 reduce CPU costs?
https://pics.computerbase.de/8/8/5/8/2/2-1080.a15e6f85.png
One possibility dont search and viewed in above NextP. Comments is than guys laboratory Roswell Nevada USA make better their job about UFO inverse engineer tech.
I agree that if we have neat tech in Roswell, now might be a time to reverse engineer it. I want a portable fusion reactor and a warp drive, please.