

It is very rare for any of the major semiconductor suppliers of the world to ever admit that things are going wrong, even when we all know that they have been.
But as part of a briefing ahead of the SC22 supercomputing conference next week and just ahead of AMD’s launch of the “Genoa” Epyc 9004 series of processors, we got a little something that looked like contrition as Intel is late delivering its “Sapphire Rapids” Xeon SP CPUs with HBM memory and its related “Ponte Vecchio” Xe HPC GPUs.
This may be the last time we have to type or read Xe HPC when referring to Intel’s compute engines focused on HPC and AI, so let’s celebrate that for a second as we contemplate the “Max Series” branding that Intel has adopted for its HBM-goosed Xeon SP processors, its Ponte Vecchio and follow-on “Rialto Bridge” datacenter GPUs, and the future hybrid “Falcon Shores” hybrid CPU-GPU packages due in 2024 alongside the “Granite Rapids” Xeon SPs. So long superscript e, we never really liked you in a brand name. Go back to the natural logarithm where you belong. . . .
As part of Intel’s prebriefings for its SC22 announcements, we did get a little bit more information on the timing of the Sapphire Rapids HBM CPUs and Ponte Vecchio GPUs that are at the heart of the 2+ exaflops “Aurora” supercomputer that is to be installed at Argonne National Laboratory. Aurora was initially expected in 2018 as a pre-exascale system and in a completely different configuration, based on a “Knights Hill” many-core X86 processor etched in 10 nanometer processes and goosed with vector engines and high bandwidth memory of a different kind.
Intel and Argonne have never explained to our satisfaction why the original Aurora machine was canceled, but you don’t need a supercomputer with tens of thousands of low-precision matrix units to infer what probably happened from the outside.
The Aurora machine and its Knights Hill CPUs were designed at a certain place in HPC and AI history, and had Intel been on the leading edge of process technology and delivered 10 nanometer manufacturing at reasonable volume and on time, it may have come to market as planned. And that might not have been good for Intel or its customers because AI has gotten more voracious than perhaps many HPC centers or Intel had planned.
Because GPU computing widened the gap with many core Xeon Phi chips from Intel, it is understandable that Intel could cancel Knights Hill and start down the path of delivering a power GPU compute engine leveraging all of the design, processing, and packaging technology that it could muster. That initial delay, given where Nvidia was with its GPUs and where AMD was heading, was understandable even if it was terribly disruptive. And not just to Argonne, but to all of the other HPC centers that had adopted IBM’s BlueGene line of supercomputers and who were led to believe that the Knights chips plus Omni-Path interconnect were the follow-ons to the many core architecture that Big Blue promoted and delivered on for several generations. Al Gara was the architect of both the BlueGene and the Knights machines.
It is significant that IBM changed its mind on HPC architectures, going with a hybrid CPU-GPU design with Power8 and Power9 processors paired with Nvidia V100 and P100 accelerators. Intel ultimately followed a path blazed by IBM. Twice. Which is ironic. Some might say inevitable. The Knights CPUs plus OmniPath followed BlueGene, and then both IBM and Intel caught the GPU offload religion. An X86 core, goes this thinking on the latter bit, is just not skinny enough to be massively parallelized the way a GPU can be. Even a trimmed down Atom core like the one at the heart of the Knights family of processors had is too fat to be as efficient as a GPU for massively parallel work and too skinny for the serial work a heftier CPU core can do. It is sort of the worst of both worlds.
The delays with the latest incarnation of Intel’s Aurora compute engines don’t just stem from ongoing delays and high costs of its 10 nanometer processes, but also because of the ambition Intel has to use advanced packaging to push the envelope on its GPU designs. The Ponte Vecchio design incorporates over 100 billion transistors across 47 chiplets and employs its EMIB 2.5D and Foveros 3D chip interconnects, which are both untested on such a complex package. The word we have heard on the street from people who know a thing or two about 2.5D and 3D packaging is that the yields on the Ponte Vecchio package are running at about 10 percent, which means nine out of ten finished Max Series GPUs are ending up in the crusher. That is after any yield issues that might affect any of those 47 tiles individually.
Maybe 47 tiles was too ambitious. Maybe mixing chiplets based on the Intel 7 process (what we used to call 10 nanometer) and 7 nanometer and 5 nanometer processes from Taiwan Semiconductor Manufacturing Co is not as easy as it sounds.
Jeff McVeigh, general manager of the Super Compute Group at Intel that sells the Flex Series of GPUs and Max Series of CPUs and GPUs, hinted in a roundabout way that the company was contrite about its ambitions, and that its reach might have exceeded its grasp during this second Aurora product cycle as well. But that the goal of getting the Aurora machine built and its compute engines commercialized was going to be realized.
Here is what McVeigh said, and it warrants his full quote to get a feel for the sentiment coming out of Intel as he made an analogy between scaling up HPC systems and mountain climbing:
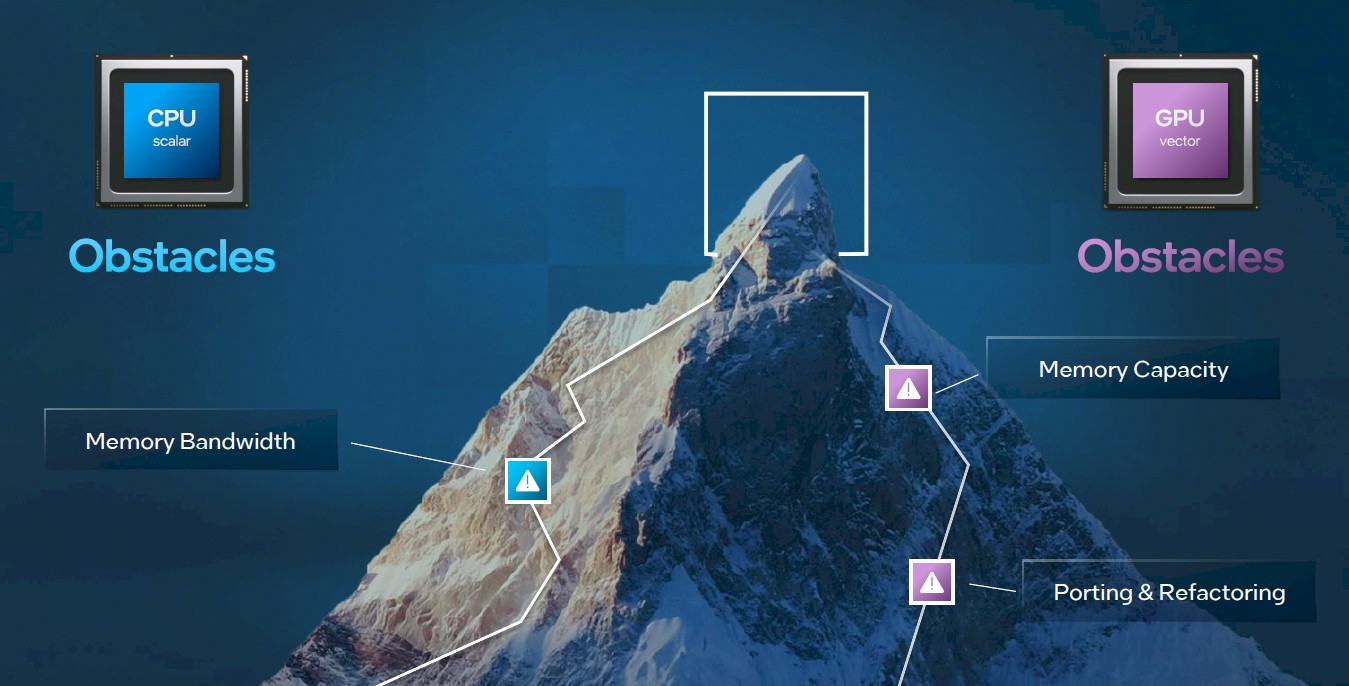
“The storyline for the keynote is really about how do we reach this maximum peak of our compute capabilities to solve those world-class problems. And traditionally, there’s sort of been these two routes up this summit. One is the CPU route. And then the other is the GPU route. And each has their own obstacles. And our goal is to really go forward and address them holistically. I fancy myself a little bit of an amateur mountaineer, living in the Pacific Northwest of the United States for a number of years and trying to reach the summit of many, many of the local mountains. Sometimes I did it, sometimes I fell short, but I was always trying to accomplish that while also doing it with the main goal of coming home safely. The same thing applies to our attempts to reach the summit of compute here. We’re always going to be pushing the envelope. Sometimes that causes us to maybe not achieve it. But we’re doing that in service of helping developers, helping the ecosystem to solve those biggest challenges.”
That is about as much as Intel has said in recent years that even sounds like an apology to Argonne specifically or the US government in general for the Aurora delays, much less the researchers whose work has been put on hold due to these delays. This is not the first HPC system in history to be delayed, of course. But this was Intel’s flagship system – twice.
When Raja Koduri, Intel’s chief architect and general manager of the Accelerated Computing Systems and Graphics Group (AXG), dropped in unexpectedly in the briefing McVeigh was giving, this is what he added: “It has been a long five years of work that went into some of the technologies and platforms. So can’t wait to get it out and get going.”
And towards the end of the briefing, Koduri had this further comment: “This is a key, key, key moment because now we have a base, both on the CPU and GPU front to iterate on, and the oneAPI software stack. It was a humongous effort to get to this point. But the improvements that you will see – the rapid rate of improvements based on this platform – that is what I am looking forward to. To deliver to developers, to our customers, to you all, because we have a baseline.”
So that is the context as far as Intel is concerned on all of this history and current events in HPC and AI compute.
Which brings us to when the Max Series CPU formerly known as Sapphire Rapids with HBM and when the Max Series GPU formerly known as the Ponte Vecchio GPU accelerator will be available. The system was originally slated to have around 9,000 nodes, each with a pair of the Max Series CPUs and six Max Series GPUs, but in the latest stats for the machine, Argonne now says there will be over 10,000 nodes. So that is over 20,000 of the CPUs and over 60,000 of the GPUs. And right now, we presume Argonne is getting all of the Max Series devices Intel can make.
The Sapphire Rapids Max Series CPU is slated for launch in “very early January,” according to McVeigh, and the rumor is that it is going to launch and be generally available on January 10. And the Ponte Vecchio Max Series, says McVeigh, will be delivered in the Aurora system first and then will be available for other HPC and AI system designs in early Q2 2023.
McVeigh also confirmed that there will be no Top500 benchmarks run on the Aurora machine or its development platform, called “Sunspot,” this year, and added that Intel was “eager to do it in 2023.”
We also eagerly await this and also look forward to seeing how the Max Series evolves through the “Emerald Rapids” Xeon SPs with HBM and the Rialto Bridge GPUs in 2023 and the converged Falcon Bridge platforms and their “extreme bandwidth memory” (whatever that is) in 2024. We await every step in the roadmap, steps that Intel can no longer miss.
In the meantime, Intel has given out some more feeds and speeds on the Max Series compute engines, which we will cover separately.




Just a few days to SC22 (Nov. 13-18), hopefully with updates on Frontier, Fugaku, LUMI, and friends, as well as some Hoppers (fingers crossed). In June, LUMI was essentially 1/8 of Frontier so, extrapolating, Frontier’s HPCG score would have been just under that of Fugaku (16 PFlop/s)… but, 20MJ/Exaflop (or 20 pico-joule per FP64-op) still looks like the record to beat (great going MI250x!).
It does make you wonder why the labs are willing to sign on to contracts like this for technology that is so much of a leap into the unknown. I suppose the original contract wasn’t. Knight’s Hill was a fairly straight-forward evolution of Knights Landing. The harder to understand part is why Argonne agreed to the change of contract to a much more ambitious design that changed even more variables. It’s not as if Aurora promises some grand revolution in the way HPC software is run or how it is written. Had everything worked out, Argonne would have ended up with a relatively standard cpu+gpu supercomputer, not so different from what other DOE labs have been running for a few generations. They would have had to deal with Intels young driver and programming tools stacks. Had everything turned out well, all of the innovation and major steps forward would be on the manufacturing side of things. The real prize would have gone to Intel. Since it didn’t, Intel pays the price, but Argonne has been very patient.
In part, it is their job. They want two different sources and architecture options for this very reason. You never know when something is going to go wrong five years out.