
In March 2020, when Lawrence Livermore National Laboratory announced the exascale “El Capitan” supercomputer contract had been awarded to system builder Hewlett Packard Enterprise, which was also kicking in its “Rosetta” Slingshot 11 interconnect and which was tapping future CPU and GPU compute engines from AMD, the HPC center was very clear that it would be using off-the-shelf, commodity parts from AMD, not custom compute engines.
This stood somewhat in contrast to its peer HPC center, Oak Ridge National Laboratory, whose “Frontier” exascale supercomputer has custom “Trento” Epyc 7003 processors with Zen 3 cores and the Infinity Fabric 3.0 interconnect, which provides coherent memory between the Trento CPUs and the “Aldebaran” Instinct MI250X GPU accelerators.
Being installed later means that Lawrence Livermore can intersect the AMD compute roadmaps further into the future, and get more powerful compute engines to reach its “greater than 2 exaflops” peak performance target. And while AMD was saying more than two years ago that El Capitan was going to be based on standard “Genoa” Epyc 7004 parts and standard “Radeon Instinct” GPU parts – AMD had not yet dropped the “Radeon” brand from its datacenter motors when it was speaking – it was not at all obvious, even weeks ago, that El Capitan would not be using discrete Epyc and Instinct chips to do its work.
It sure wasn’t obvious from this diagram of the El Capitan nodes using high-speed, PC-Express switched high speed storage system called Rabbit, which we wrote about in March 2021:
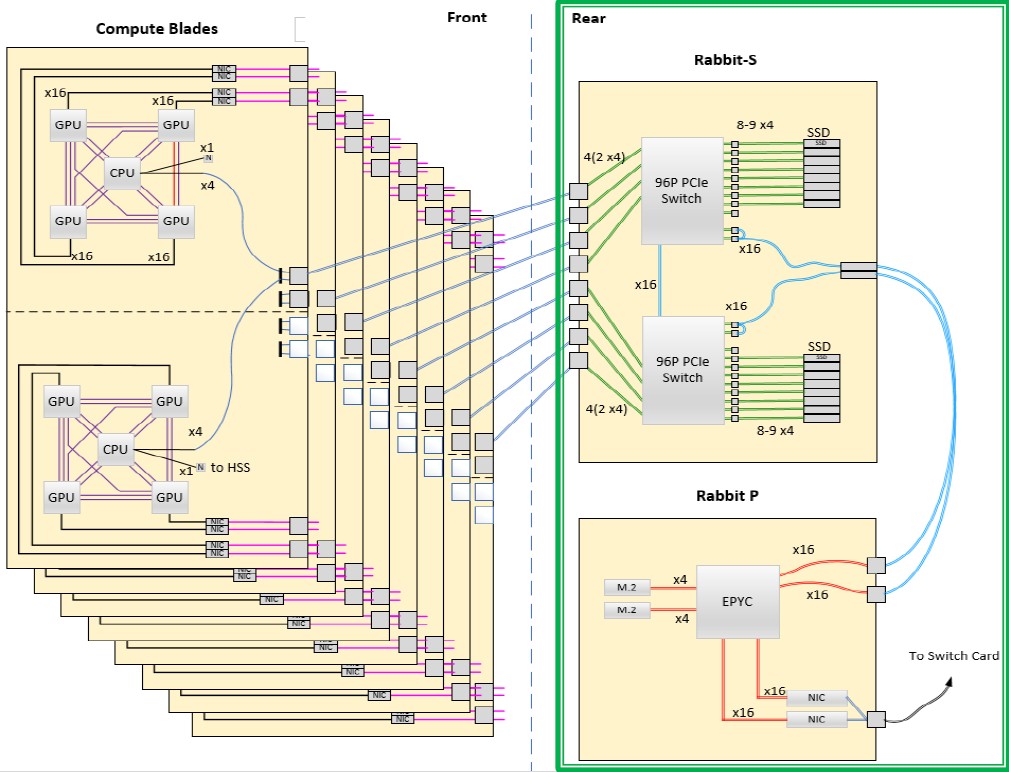
That sure looks like a Frontier node, architecturally. And it looks like sometime within the past year, as AMD was putting together its hybrid CPU-GPU device that Lawrence Livermore decided that was a better approach. We do not think Lawrence Livermore would have used an incorrect block diagram a year ago to throw us all off of the scent that it was using a single CPU-GPU package. And thus we think that the implementation of a converged accelerated computing unit, or APU, hybrid CPU-GPU compute engine, which is absolutely not a new idea at AMD, was perhaps a product that was brought forward onto the roadmap and Lawrence Livermore is one of the first – if not the first – to get access to it.
At the HPC User Forum meeting, which is being hosted at Oak Ridge this week, Terri Quinn, deputy associate director for high performance computing at Lawrence Livermore, revealed that the HPC center would actually be employing the future Instinct MI300 compute engine, which converges a Genoa CPU and a future (and as yet un-code-named) Instinct GPU into a single, tightly coupled compute complex with unified memory across the Infinity Fabric 4.0 interconnect – not just coherent caches across discrete devices to help share memory that came with the Infinity Fabric 3.0 interconnect employed by Frontier.

These specific APUs, as AMD has called them for a decade, will be branded the Instinct MI300A, according to sources at Lawrence Livermore. And as we talked about last week when we delved into AMD’s compute engine roadmaps, we expect for a fairly large number of cores on the Epyc chiplet (64 sounds like a good number, 32 might be more likely) and as many as four next-generation GPU chiplets on the Instinct side of the complex. AMD may even break the chiplets down in the APUs, with eight GPU chiplets paired with eight CPU chiplets to maintain the one-to-one ratio of chiplets seen in Frontier. Look at the chart in our Frontier story:
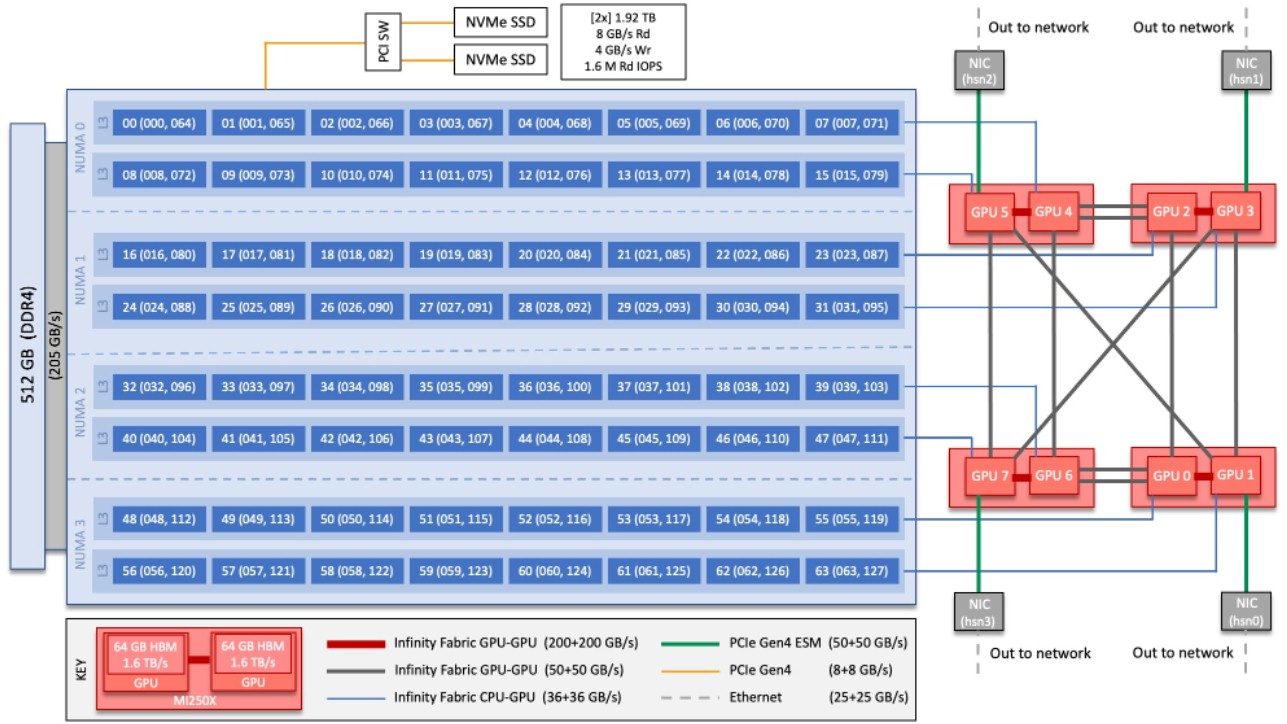
See what we mean? Frontier does not really have a 1:4 CPU ratio when you look under the hood, but really a 1:1 ratio, just like the “Titan” supercomputer had way back when.
Whatever the CPU to GPU ratio is with the MI300A, it will be locked down by AMD, and it will apparently be done in a way the system architects at Lawrence Livermore want it. We shall see.
So, in a sense, El Capitan is not so much using off-the-shelf parts as it is helping AMD create an APU that suits its needs that AMD can turn into a higher volume product as other HPC and AI centers emulate El Capitan.
To be fair, the rumor we have heard is that the MI300 series would have four GPU chiplets, doubling their FP64 performance, and if there are four chiplets and four core complexes on the Genoa part of the die with, say 32 cores, then it will be a one-to-one pairing that would look like the same 1:4 ratio of the Frontier node. And that picture above would still hold true, except that the eight chiplets (drawn as five because the CPU is glommed down into one unit logically) would be in one package. And would it not be interesting it if was supporting the Open Compute Accelerator Module (OAM) standard?
We think it almost certainly will, and that Intel could do the same thing with its “Falcon Shores” Xeon SP-Xe HPC hybrids, as we talked about a few weeks ago.
However the compute engines are built, the El Capitan machine is to have more than 2 exaflops of peak theoretical performance at FP64 double precision floating point, and aims to consume less than 40 megawatts of power. By going with the architecture that it did. Livermore was able to get about 30 percent more FP64 flops than the “more than 1.5 exaflops” it had originally planned for the same money, and we think part of that performance boost came from letting the power draw on the box go from around 30 megawatts to kissing 40 megawatts.
When the El Capitan system deal was announced in August 2019, the machine was expected to be delivered in late 2022 by Cray, which was not yet part of Hewlett Packard Enterprise. Now, El Capitan is expected sometime in 2023. Full production is anticipated for the second quarter of 2024, and the machine is expected to be operational all the way out to 2030, having that megawatts be as low as possible is important for economic as well as political reasons. (This is the Department of Energy, after all.) At $1 per watt per year and rising fast, over its expected lifespan, El Capitan could burn $250 million or more in electricity to power itself, and cooling would be supplemental to that. The system itself has a budget of $600 million for the hardware and systems software.
Importantly, El Capitan is supposed to provide more than 10X the performance of real-world applications compared to the “Sierra” system, built by IBM using Power9 CPUs and Nvidia V100 GPUs.
The other interesting bit from Quinn’s presentation above is that the El Capitan system will make use of the Tri-lab Operating System Stack (TOSS) and the Tri-lab Common Environment (TCE) systems software created by Lawrence Livermore, Sandia National Laboratories, and Los Alamos National Laboratory. This software normally runs on the more generic capacity clusters at these three US Department of Energy labs, while the capability-class machines run the software stack provided by the prime contractors of the machines – IBM did Red Hat Enterprise Linux and other stuff and Cray had a variant of SUSE Linux that was tweaked to run on its iron and to support Cray’s compilers and runtimes.
The system will also employ the homegrown Flux resource management framework, a next-generation to the SLURM resource manager that was also created at Lawrence Livermore. SLURM thinks about nodes, but Flux assumes that job schedulers and workload managers might change over time, or be used concurrently, just like Google’s Borg/Omega cluster controller and job scheduler does. (We need to spend a little more time analyzing Flux. . . .)
The El Capitan system will have near-node local storage based on the Rabbit architecture, which we mentioned above and which we wrote about here in detail a little more than a year ago. Rabbit is a kind of disaggregated flash storage, kind of like a DPU running only storage protocols on PCI-Express switching with low-latency NVM-Express drives talking directly to the flash. It is both converged with the compute like local storage and yet separate from it like a storage area network. HPE and Lawrence Livermore are also working on a “New HPE/LLNL I/O stack,” and we are curious as to what that might be.

HPE Is The First Big OEM To Adopt Ampere Computing Arm Chips
Hewlett Packard Enterprise has been an early and enthusiastic supporter of alternate processor architectures outside of the standard Xeon X86 CPUs that comprise the vast majority of its revenues and shipments, particularly with Arm server chips starting in 2011. Maybe now, the fourth time will be the charm as it …

HPC In 2020: Acquisitions And Mergers As The New Normal
After a decade of vendor consolidation that saw some of the world’s biggest IT firms acquire first-class HPC providers such as SGI, Cray, and Sun Microsystems, as well as smaller players like Penguin Computing, WhamCloud, Appro, and Isilon, it is natural to wonder who is next. Or maybe, more to …
HPE Converts Analytics, Storage, Data Protection To GreenLake
Since launching GreenLake in 2018 and promising that all of its portfolio would be available as services by next year, Hewlett Packard Enterprise has been on a sprint to build up the capabilities of the platform. That has only accelerated since Antonio Neri took over as CEO in the wake …
The possibility that single-package CPU+GPU chiplet designs will replace discrete GPU accelerators just as fast as FPU accelerators disappeared years ago may explain why Nvidia needed to buy ARM and conversely why ARM needed Nvidia.
Even with that deal cancelled, my hope is that Nvidia will survive the crypto-mining crash and produce competitive Grace Hopper CPU+GPU combinations suitable for AI and high-performance computing. More choices are always better, especially when there are so many supply-chain problems.
Hi Tim,
I’m curious: in your Frontier piece you mentioned total built-out power draw of 29 or 30 GW IIRC. For El Capitan, you note about 40 GW. Are the architectures that dissimilar, or the FLOPS ratings that diverse, or something else? Otherwise I have to believe Frontier learnings would help El Capitan’s budgets. What am I missing, please?
Curious, isn’t it? I been thinking about that, too.
Megawatts. Dear god, gigawatts won’t happen for a decade yet, and we will have fusion then….