

In an ideal platform cloud, you would not know or care what the underlying hardware was and how it was composed to run your HPC – and now AI – applications. The underlying hardware in a cloud would have a mix of different kinds of compute and storage, an all-to-all network lashing it together, and whatever you needed could be composed on the fly.
This is precisely the kind of compute cloud that Google wanted to build back in April 2008 with App Engine and, as it turns out, that very few organizations wanted to buy. Companies cared – and still do – about the underlying infrastructure, but at the same time, Google still believes in its heart of hearts in the platform cloud. And that is one reason why its Tensor Processing Unit, or TPU, compute engines are only available on the Google Cloud. (Although you could argue that the GroqChip matrix math units available through Groq are as much of an architectural copy of the TPU as Kubernetes is to Google’s Borg container and cluster controller, Hadoop is to Google’s MapReduce data analytics and storage, or CockroachDB is to Google’s Spanner SQL database.)
When you put a cluster of 2,048 TPU cores on a tightly coupled toroidal mesh network and have a combined 32 TB of HBM2 memory and over 100 petaflops of single precision floating point math (with mixed precision support to do inference) out there on the cloud for people to run applications, it is only natural that people running HPC applications will tweak their codes to make use of the TPU.
For the past several years, experiments have been done, and the latest one was done by Google itself showing how to accelerate the fluid dynamics associated with predicting river flooding. There are many more examples, which we will discuss in a moment, and it will be interesting to see if the TPU and its clones find a home in HPC or if this is just a bunch of worthy investigative science projects.
We would point out that in 2006, this is precisely how math algorithms and then portions of HPC codes were offloaded from CPUs to GPUs, starting a whole revolution that the AI explosion several years later has benefitted from. Now, it is AI that is driving technologies like the TPU and it is HPC that can benefit from it.
The most recent paper out of Google, which you can read here, researchers ported the math underlying the hydrodynamic models from CPUs to TPUs and measured the performance of the TPU core against a relatively modern X86 CPU core. (Comparisons with GPUs were not given, and obviously thanks to Google Cloud, which sells raw GPU capacity, as well as massive internal GPU farms that Google uses for various parts of its machine learning training stack. While the TPUv4 matrix engine has been in development and preproduction for some time now, as far as we know it has not been rolled out onto Google Cloud and the TPUv3 matrix engines, which we profiled here, are the only ones that people can kick the tires on.
Here is the neat thing that stuck out as we read this paper: HPC codes for running the flood simulation were not ported from a parallel stack running, for instance, Fortran code and using OpenMP and MPI. Google went straight to the Saint-Venant shallow water partial differential equations used to simulate liquid flowing over topography and implemented them in Python atop its TensorFlow machine learning framework, making use of its Accelerated Linear Algebra (XLA) compiler. Importantly, Google created a fully 2D model of river flooding rather than a hybrid 1D-2D model that is commonly done on CPU-only systems that are computationally weak by comparison to a pod of TPUs. Here is what the TPU simulation flow looks like for this flooding simulation:
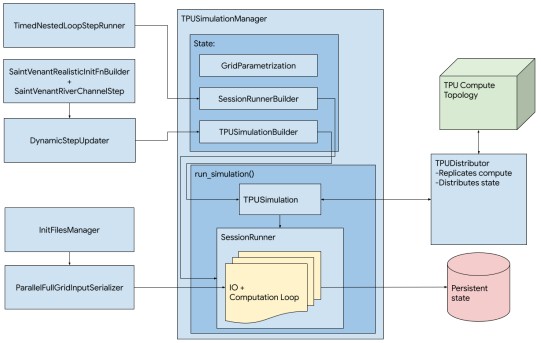
Google has open sourced the code behind this simulation to help HPC researchers see how this flooding model works and maybe do some work of their own in other parts of the HPC sector. You can download this code here. There are tricky things you have to do to create the initial conditions at the edges of any simulation, and this application created by Google handles that. And the collective operations in the TensorFlow framework and enabled by the TPUv3 network appear to do a good job, based on visual inspection of imagery and comparison with actual data obtained from a real flood that was simulated, of figuring out the height of the water and its flux through the simulated topology.
As is the case with any fluid flow simulation, resolution matters, but it comes at high computational cost. Low resolution models give you a feel, but high resolution models give you something that looks and feels more like data. So Google rans its simulations on X86 CPU cores and TPU cores at 8 meter, 4 meter, and 2 meter grid resolutions and then pushed a quarter-pod of TPUs to deliver down to 1 meter grid resolution. The simulation was done on a section of the Arkansas River that flooded in May 2019. Google tested the scaling of resolution against different sized slices of the TPU pod, ranging from a single TPU core all the way to a quarter pod with 512 TPU cores. The datasets ranged from 15.5 million grid points at the 8 meter resolution to 1 billion grid points at the 1 meter resolution.
Here is how the riverine flood simulation did on various sizes of TPU compute and at various resolutions:
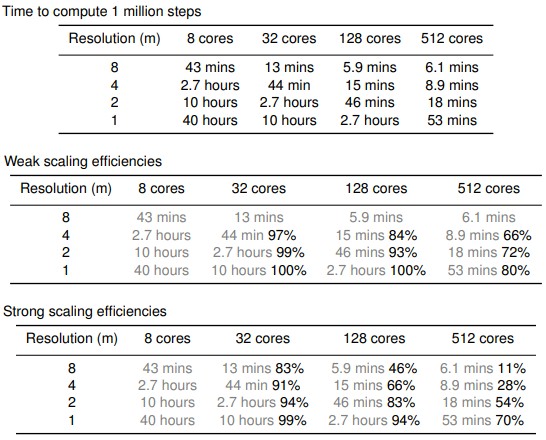
For whatever reason, Google did not run this flooding simulation across an entire TPU pod. As you can see from the table above, there were some diminishing returns moving from 128 TPU cores to 512 TPU cores at the 8 meter resolution, but at the lower resolutions, the scaling was still doing pretty well as more compute was added. But the scaling was dropping off pretty fast, and maybe Google didn’t want to talk about that. OK, we think Google definitely did not want to talk about that. But we realize that making simulations scale across all the iron in any supercomputer is hard and on a second pass Google would no doubt be able to do better at higher scale. Just like real HPC shops do with their simulations.
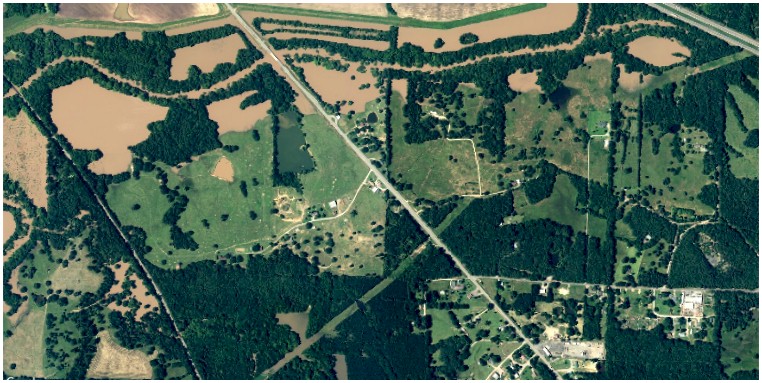
So how well did the TPU do at predicting the flood? Good enough to tell emergency responders where the trouble spots were going to be, we think. Here is the aerial flooding on a section of the Arkansas River at 1 meter resolution showing the extent of actual flooding:
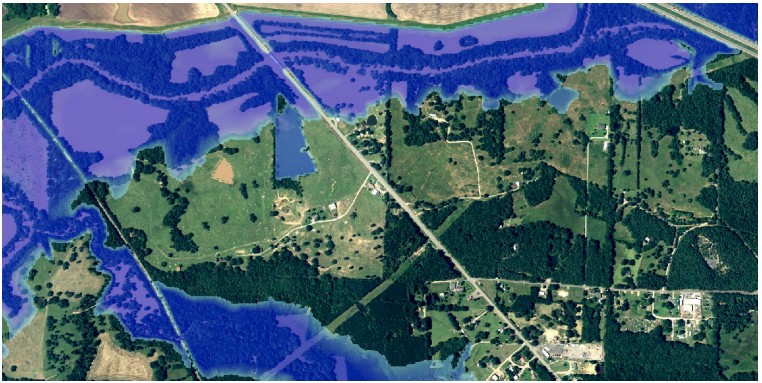
And here is where the simulation predicted where flooding would be based on a similar river flow rate that occurred during the flood:
The other interesting bit of the research that Google did was to run the same simulation on CPUs as well as its TPUs, using the same code stack and merely replacing the XLA compiler used for the TPU with the Eigen C++ template library for linear algebra for CPUs running Linux.
Here is how the CPU stacked up against the TPU on a per-core level:
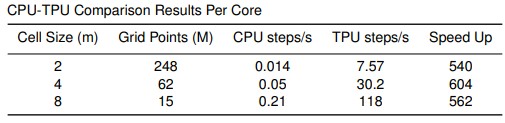
The CPU in question here is a “Cascade Lake” Xeon SP-8273CL Platinum, which has 28 cores running at 2.2 GHz and rated at around 2 teraflops at FP32 single precision. (The single precision floating point performance ratings for IEEE FP32 formats the TPUs have never been published.) The difference in performance per core is well over 500X, which stands to reason given the number and size of the MMX matrix math units in the TPU cores. Each TPUv3 core has two 128×128 matrix math units, and each TPUv3 chip has two cores; there are four TPUv3 chips per motherboard, and 256 motherboards per TPUv3 pod. (By the way, the TPUv2 had half as much HBM memory per core, at 8GB, and half as many MMX units per core, at one each, compared to the TPUv3. So the speedup on the TPUv2 iron that is still available on the Google Cloud would be around half as much per core compared to the X86 iron.
Google did not show how the X86 servers could be clustered and scaled. And it certainly did not talk about the cost of running the simulation on a CPU cluster versus a TPU cluster within a certain time, as you need for weather and emergency management simulations. But, given this data and a lot of guessing, HPC shops can start thinking about what that might be. (We might do this work ourselves when the news flow slows down in July, just for fun, figuring out how a more modern cluster using AMD “Milan” Epyc 7003 processors might compare to rented capacity on TPUv3 and TPUv4 pods. Hmmmm.)
As we pointed out above, the number of HPC codes that have been ported to the TPU to accelerate them is on the rise, and Google is not doing all of the work because the HPC community is curious. Here are the papers we could find without hurting the search engine too much:
- Large Scale Distributed Linear Algebra With Tensor Processing Units, Google, December 2021
- Molecular Dynamics Simulations on Cloud Computing and Machine Learning Platforms, Indiana University, November 2021
- Nonuniform Fast Fourier Transform on TPUs, Google, Mass General, Harvard University, April 2021
- Large-Scale Discrete Fourier Transform on TPUs, Google, December 2020
- Accelerating MRI Reconstruction on TPUs, Google, June 2020
- Tensor Processing Units for Financial Monte Carlo, Google, January 2020
- High Performance Monte Carlo Simulation of Ising Model on TPU Clusters, Google, November 2019
Wouldn’t it be funny if after coming all of this way with CPUs and accelerators that we end up with an architecture that looks like an 80286 processor with a massively parallel set of 80287 co-processors for doing its math homework? IBM did the same thing with six-way System/3090 mainframes and slapping a vector math units on each motor back in 1989 when we were just getting started in this datacenter racket and when Cray was first winning commercial customers in the enterprise. It will all depend on the software that gets developed, of course.
And one last thought: Any code created to accelerate HPC on TPUs would presumably be relatively easy to move over to matrix math engines created by Cerebras, SambaNova, and GraphCore as well as Groq.




A lot of what you write goes over my head, but I try to learn and just wanted to say thanks for writing these pieces 🙂
I try to find interesting things and see how they might take hold in new markets. I certainly don’t understand a lot of the underlying math specifically, but I have some general knowledge about it, and what I really like is watching system architecture change over time as new problems arise. I am glad you are willing to learn alongside of me. What a pleasure it is to be in this together with you.