

Let’s just cut right to the chase scene. The latest Top500 ranking of supercomputers, announced today at the SC21 supercomputing conference being held in St Louis, needed the excitement of an actual 1 exaflops sustained performance machine running the High Performance Linpack benchmark at 64-bit precision. And because the 1.5 exaflops “Frontier” system at Oak Ridge National Laboratories is apparently not fully built and the Chinese government is not submitting formal results for two exascale systems it has long since built and had running since this spring, we’re hungry.
Excitement is as vital a component in supercomputing as any compute engine, interconnect, or application framework, and excitement is what competition in the industry is supposed to deliver – aside from the ability to do more science and better science. We are emotional people, living during a global pandemic that may never go away, during what is supposed to be a shining week for supercomputing and socialization amongst its participants, and this is just not right.
So the November 2021 Top500 rankings are like leftovers a few days after Thanksgiving: You will eat them because they are food and you need sustenance, but you want something a little more exciting.
It isn’t right that China has run Linpack tests on two supercomputers and they were not on the Top500 in June or now in November. And it is not right that Frontier didn’t make the November 2021 list. And it is not right that, knowing that Frontier was not going to make this iteration of the list, Microsoft didn’t personally throw down a much larger Azure cluster, and one actually based on the new “Milan-X” extended cache processors that AMD announced last week and that Microsoft has first dibs on, to make the bold point to the world about how the hyperscalers and cloud builders can drop exascale machines any freaking time they want.
To be superclear: We think that only cloud supercomputers that are run as managed services on behalf of their parent company or HPC centers should be allowed on the Top500 list. You can’t fire up a massive cluster as a benchmark stunt, but you can do it to make a statement and then provide access to the cluster and do real things with it to show how that might look. As we have pointed out for many years, Google, Amazon Web Services, Microsoft, and Facebook if it felt like it, as well as Alibaba, Baidu, and Tencent, could carve up their massive datacenter-scale clusters into machines that would remove every other machine from the Top 500 list, should they be so inclined.
To be fair, the most interesting new machine on the November ranking is, in fact, a perpetually running cluster on Microsoft Azure, called Voyager (not to be confused with the cluster at the San Diego Supercomputing Center of the same nickname). The Voyager system is not an all-CPU design based on its HBv2 instances, which use a pair of the 60-core AMD “Rome” Epyc 7742 processors, nor the HBv3 instances that will debut with a mix of core count and cache configurations of the Milan-X at some point in the near future. Rather, the Azure ND A100 v4 instances in the Voyager cluster have a pair of custom 48-core AMD Rome Epyc 7V12 processors running at 2.45 GHz matched with eight Nvidia A100 GPU accelerators with 40 GB of HBM2 memory each. These instances have 900 GB of physical memory, and a single 200 Gb/sec HDR InfiniBand interface from Nvidia for each GPU accelerator as well as a PCI-Express 4.0 connection back to the server host. These instances were actually put into preview at SC20 last year, and went into production in June of this year.
The Voyager cluster on Azure has a total of 253,440 CPU cores and GPU streaming multiprocessors (or SMs), which is how the people who do the Top500 rankings correctly compare across the CPU and GPU compute elements with these very different architectures. The A100 with 40 GB of memory had 108 SMs, so that works out to a total of 228,096 SMs and leaves 25,344 total CPU cores. If you do the math, the Voyager machine has a whopping 264 physical nodes. The system has a peak theoretical performance of 39.53 petaflops and delivered 30.05 petaflops of 64-bit oomph running the HPL benchmark, for a computational efficiency of 76 percent, which is typical of a hybrid CPU-GPU architecture these days. 30 petaflops and you are number ten on the list.
The ND96asr A100 v4 instance, as this virtual machine with two CPUs and eight GPUs is called officially, has 6.5 TB of local storage and a 40 Gb/sec link to the Azure network (and therefore the outside world). If you buy it under a pay as you go model, it costs $27.197 per hour, and if you reserve it for one year, the instance costs 31 percent less at $18.8284 per hour and if you reserve it for three years it costs $10.8788 per hour. So what does this 264 node machine cost for three years? There are 24 hours in a day, 365.25 days in a year, and three years in the useful life of a supercomputer, and reserving this machine on Azure for three years would therefore cost $286,090 per node or $75.53 million for three years for 264 nodes. That includes power, cooling, datacenter, and system management costs.
We can estimate the power it would take to light up and cool this Voyager instance easily enough, and do so in the table below:
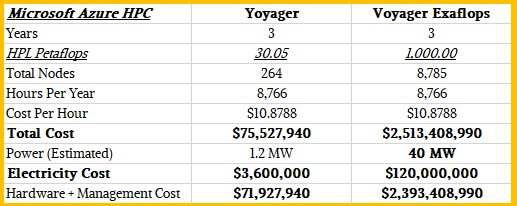
We figure this is a 1.2 megawatt cluster, including networking and storage, and that would run around $3.6 million over three years. So we subtract that out to get machine, facilities, and management costs.
Now, let’s have some fun. Let’s say Microsoft wanted to slap down an exaflops of oomph on Azure and keep it running for three years so it could persist on the Top500 list and donate its capacity to science. (Why not?) That would take 8,785 ND96asr A100 v4 instances – a little less than the 9,000 node count as the “Frontier” supercomputer going into Oak Ridge will have, and which will have about 50 percent more performance by the way thanks to those AMD “Aldebaran” Instinct MI200 accelerators – and you better get out Uncle Sam’s checkbook to pay for this one. Let’s do the math:
Over three years, at list price discounting from Microsoft, the Voyager exascale machine would cost about $2.51 billion, and even if you back out about 40 megawatts worth of juice over three years at a cost of around $120 million, you still have $2.39 billion in costs. That number made our eyes water like we were cutting the onions to stuff several turkeys on Thanksgiving Day morning. And it demonstrates aptly the perception that cloud HPC is much more expensive than on-premises HPC, considering that Frontier costs $500 million for the hardware and another $100 million for non-recurring engineering (NRE) costs. Frontier is expected to be rated at about 29 megawatts, so call it around $90 million to power and cool it for three years.
Now we know why Microsoft, Google, AWS, Alibaba, Baidu, and Tencent don’t slap down exascale machines to make statements. They do Top 50 through Top 10 systems so they can keep us all talking about what they do, and what this really shows is the cost of convenience and massive scale over and above the responsibility of ownership and capacity planning. That’s the cloud in a nutshell. Cost differences of 5X to 9X are still not unusual when pitting cloud instances against on-premises clusters. You have to count the costs of all the things the cloud providers do – take the risk on architecture decisions on established technologies, and the risks that HPC centers take in pushing the technology envelope – into account in the full accounting of this math in the table above. Which we have not done, and cannot do without more information. The gap is not as big as it looks, but it will always be there because any cloud builder’s profit margins must, of necessity, be bigger than the volume pricing discounts they get to take into account that the clouds must always overprovision their compute, networking, and storage. At least until we have 20 years or 30 years of cloud compute under our belts and workloads stop shifting between on premises and cloud and changing outright.
So, never, really.
Now, let’s get back to the Top500 rankings after that amusing diversion.
For the moment, the “Fugaku” heavily vectorized Arm server at RIKEN Lab in Japan is the most powerful supercomputer in the world, again, at least among those ranked by official HPL benchmark results. This is Fugaku’s fourth top ranking, and unless something really weird happens, Frontier at the very least should best it on the June 2022 list. There could be another two Chinese machines on the list at that time – or not, depending on moods in the Middle Kingdom. Unless these two machines are upgraded, they will only be just over 1 exaflops on HPL, so Frontier should have a considerable performance advantage. At some point. The upgraded “Aurora” machine at Argonne National Laboratory should enter the picture, and it looks like this machine might best Frontier on the HPL benchmark if it can be up and running by the June 2022 list.
The thing that we need to consider is that we have fallen off the exponential curve with supercomputers, both high and low:
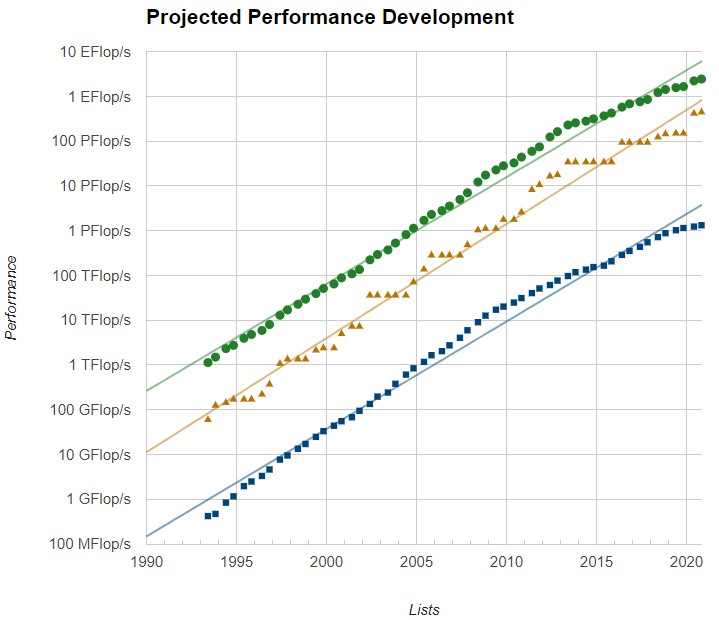
The growth in the aggregate sustained 64-bit floating point performance of the 500 machines on the lists since 1993 has also slowed. For those who say that Moore’s Law has not slowed down, budgets surely have because of the increasingly large cost of machines. Yes, the cost of a unit of compute is coming down, but the budgets for systems are growing fast, too. Adding more cloud to the mix will actually make HPC more expensive, for the sake of convenience and the profits of the cloud providers. They are not going to do it below cost as the OEM supercomputer makers have always done because these machines are as much R&D as they are real tools. The OEMs are supposed to make up the profits with enterprise customers needing to emulate, on a smaller scale, what the HPC centers do.
Aside from the Microsoft Voyager cluster coming into the Top 10, the only other change in the upper reaches of supercomputing (again, limited to those who do HPL runs) was that the “Perlmutter” system at Lawrence Berkeley National Laboratory boosted its performance by 9.7 percent to 70.9 petaflops sustained by adding 7.9 percent more CPU cores and GPU SMs. By the way, the computational efficiency of the Perlmutter machine running the Slingshot interconnect from Hewlett Packard Enterprise is on par with what we see with InfiniBand networks, at 75.6 percent.
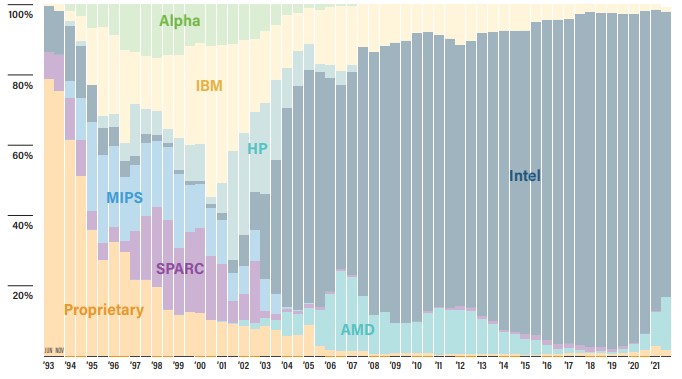
One of the things that we are watching very closely is how the AMD Epyc processors are being adopted by HPC centers, and we will be watching as Instinct MI200 accelerators hit the market in volume early next year after Frontier is done eating all of AMD’s capacity for these GPU accelerators. At its peak in the early 2000s, AMD had in excess of 20 percent shipment share of overall X86 servers and had an even higher share, at 25 percent, in the HPC sector that was the early adopter of its Opteron processors.
In the November 2021 list, AMD had a total of 73 machines, for a 14 percent share of systems, nearly triple that of where it was at a year ago. And importantly. Of those 73 systems, 17 of them are using the “Milan” Epyc 7003 processors as the host CPUs, which is remarkable given that these only started shipping in March. AMD has eight of the top 20 systems, and is going to lay down some big wins with Frontier, a slew of other machines in 2022 and add to that with Frontier’s sibling system, the “El Capitan” supercomputer at Lawrence Livermore National Laboratory, in 2023.
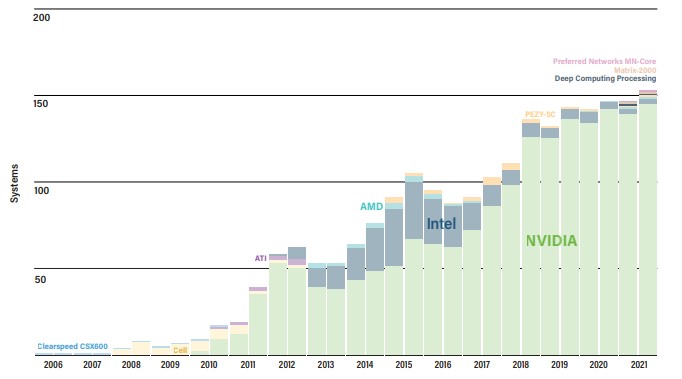
The other thing we have always watched carefully is how accelerators are being adopted to push performance. On the November ranking, there were 152 machines with some form of acceleration, up a smidgen as has been the case for sequential growth in this area for the past four lists and overall growth in the past fifteen years since accelerators came into being with ClearSpeed’s floating point accelerators, which were pushed out of the market by Nvidia’s GPUs.
The question is, will the competition between AMD, Intel, and Nvidia in GPU compute expand the market in supercomputing, driving a higher percentage of attach rate, or will it just carve up the territory already established by Nvidia? The latter is certainly easier than the former in the short term, and it is debatable whether all of the HPC applications in the world can be updated to use hybrid CPU-GPU architectures. It will be interesting to see if AI augmentation techniques compel HPC centers to adjust their simulation and modeling codes for GPU acceleration, not only expanding the market for GPUs in HPC, but also expanding the workflow in HPC applications with the addition of AI to the HPC stack. Over the long haul, there is no reason to believe that acceleration of some sort won’t be normal. But it could turn out that CPU-based simulation coupled with CPU-based inference will be the mode for running simulations, while GPU-based acceleration of HPC and AI training are used to create the hybrid applications. In other words, organizations might have two different supercomputers: One to train the AI to do HPC, and one to run the HPC simulations themselves on machines with embedded AI inference.


For HPC Cloud, The Underlying Hardware Will Always Matter
Decades of cloud collaborations and optimizations have brought solid performance and cost efficiencies to cloud. Those who require high performance computing (HPC) resources tend to set their own rules when it comes to systems. Highly tuned for blazing fast computation and communication with software stacks optimized to match, these users …

Waiting – Not Precisely Patiently – For Exascale
There was an outside chance that China might pull a surprise on the HPC community and launch the first true exascale system – meaning capable of more than 1 exaflops of peak theoretical 64-bit floating point performance if you want to be generous, and 1 exaflops sustained on the High …

Data Analytics Can Be The Next HPC For IBM Power
In the next few months, Big Blue will launch its entry and midrange Power10 servers, and to be blunt, we are not sure what the HPC and AI angle is going to be for these systems. This is peculiar and not consistent with the prior two decades of the history …
Be the first to comment