

If you want to build the world’s largest social network, with 2.9 billion users, and the massive PHP stack that makes it into an application, you need a lot of infrastructure and you need it to arrive predictably. Through its own supply chain management and the Open Compute Project ecosystem, Facebook has done a remarkable job taking the risk out of its infrastructure supply chain.
If you want to build the metaverse, as the newly christened Meta Platforms, formerly known as Facebook, has said it wants to do, then you are going to need untold orders of magnitude more in compute, networking, and storage – and that is going to put even more pressure on an already strained supply chain.
There are two important lessons that came out of the OCP Global Summit this week, and as obvious as they are, it has taken more than a decade for Facebook to get the disaggregated and open networking that it has long sought. What Meta is doing to diversify its networking while maintaining compatibility is precisely what enterprises of all kinds need to be thinking about, or else they might be caught flat-footed when product development efforts at vendors hit a speed bump or supply chain issues mess things up.
This is the world we live in now.
Given that, we see that Facebook – now Meta – is not only getting switching and routing gear that has the software broken free of the metal skins, the software development kits, and the merchant silicon of its hardware vendors. The company is also lining up second sources for this gear, using different ASICs and SDKs with the differences in hardware and SDKs masked by the Switch Abstraction Interface (SAI) unveiled by Microsoft six years ago, donated to the OCP a year after that as part of its SONiC switch operating system, and now used by Meta in its network gear. The Face Book Open Switching System, or FBOSS, that has run the company’s networks for more than a decade can now be more easily ported to new hardware thanks to the SAI abstraction layer, which acts as a translator between FBOSS and various SDKs.
This abstraction layer is not just important because it allows multiple ASICs to more easily run FBOSS, which would have had to have been directly ported to each ASIC and tuned for it before SAI was adopted by the ASIC vendors. The SDKs are also a control point that Broadcom, Cisco Systems, and others have used in the past because the threat of having that SDK license pulled is very real if you do something that violates its licensing terms. SAI is genius in that it only interfaces with the SDK. If you want to reach into the switch at a lower level, fine. But now you don’t have to – provided vendors provide the hooks for SAI and their SDKs to translate and communicate down to the underlying hardware.
Abstraction is also important because you cannot trust any single company to fulfill big orders when you are growing as fast as Facebook has. The growth will probably be even more intense as Meta starts building out its metaverse platform. Hyperscalers and cloud builders have to second source, or design their own ASICs and fight like hell for foundry space, which they can do because of their size but which also presents its own challenges. (For instance, your own design teams can screw up and delay a chip rollout.)
This further disaggregation enabled by abstraction that Meta now has in its networks – and that it has long enjoyed with its compute and storage, either in bare metal or virtualized form – is precisely what Omar Baldonado, director of engineering for networking infrastructure at Meta, spoke about in his keynote address at the summit this week, even if he did it obliquely by showing off two sources for the ASICs and two sources for the switch hardware underpinning the Facebook network backbone using those ASICs.
Opening Up The Network Ecosystem
Meta has been on a long road to open networking, and Baldonado highlighted the evolution of switches since the Wedge 40 switch debuted in 2014:
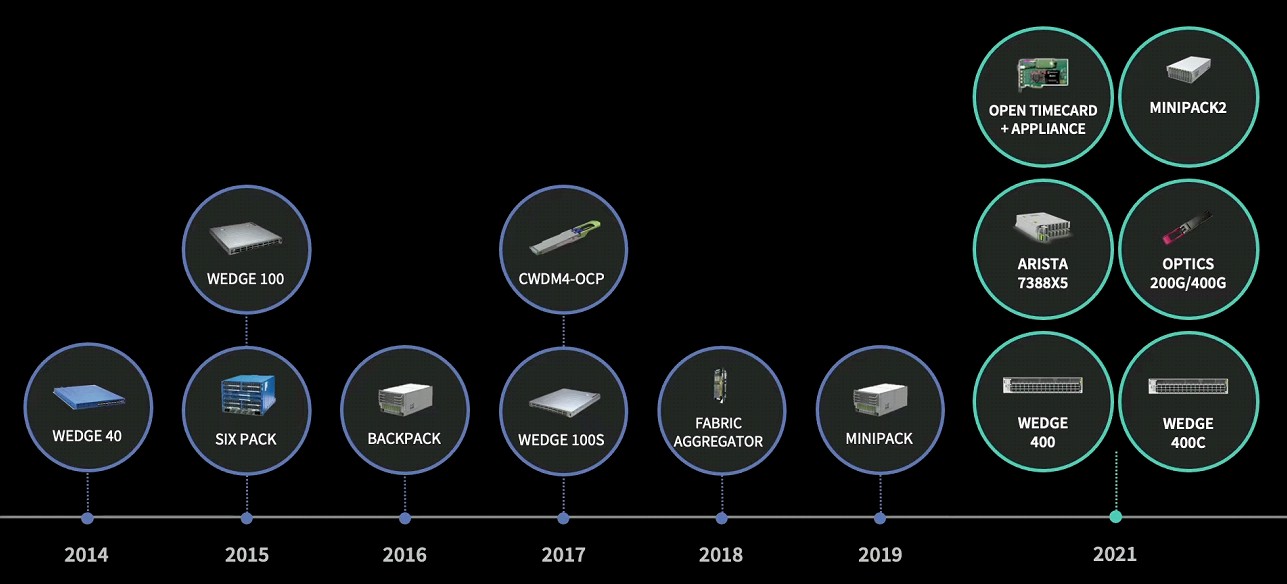
The ever-increasing bandwidth of its top of rack and fabric switches has coincided with the larger and larger networks that Facebook has woven to create every larger compute and storage complexes to support hundreds of millions to billions of users:
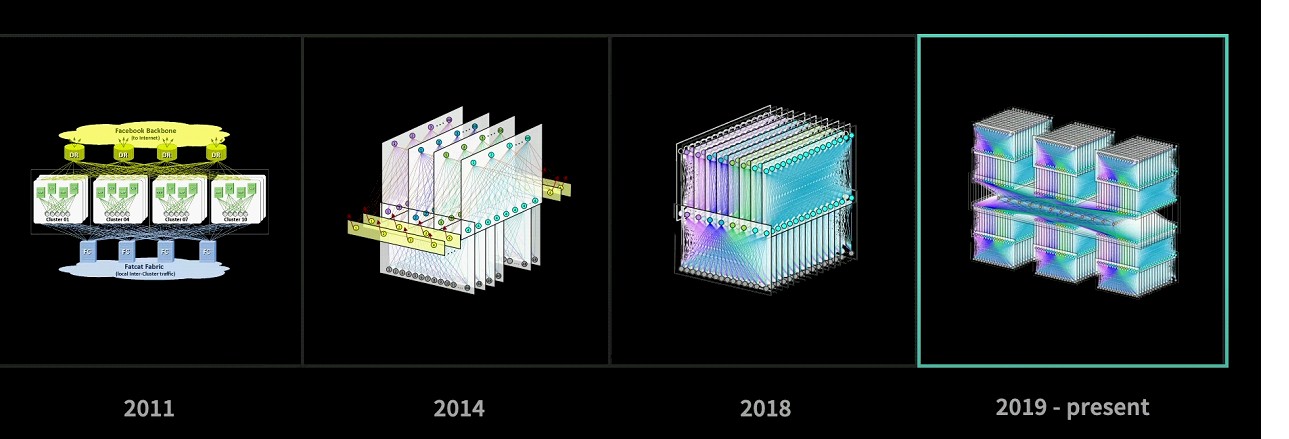
That fabric on the right is called F16, and its HGRID datacenter fabric interconnect allows for six datacenters (potentially with 50,000 to 100,000 servers each) to be fully interlinked through fabric aggregators. Let’s drill down here:

Every circle on that diagram is a fabric switch, and thus there are a lot of switch ASICs in this network. Therefore, Facebook has been thoughtful about when it moves to new technologies – and when it does not. Facebook sat out the 200 Gb/sec switching generation two years ago – to the chagrin of switch maker and long-time partner Arista Networks – but is eager to use 400 Gb/sec ASICs, in this case from Broadcom and Cisco Systems, which allow it to use cable splitters to make the switches have higher radix (and thus create an even flatter network than has been possible in recent years) and fewer numbers of ASICs, thus lowering the cost and power consumption of the network.
To support the F16 interconnect back in 2019, Arista Networks developed the 7368X4 chassis switch with 100 Gb/sec line cards, based on Broadcom’s 12.8 Tb/sec “Tomahawk 3” ASICs in conjunction with Facebook. Three years later, there are two fabric switches and two top of rack switches that Meta is deploying in the Facebook datacenters, and they come from multiple vendors and use multiple ASICs where possible.
Here are the two fabric switches Meta unveiled for the Facebook network:

The MiniPack2 on the left is based on Broadcom’s 25.6 Tb/sec “Tomahawk 4” chipset and is manufactured by Celestica in partnership with Broadcom. The one on the right is the new Arista 7388X5 modular switch, also based on the Tomahawk 4 chipset and able to support Arista’s own EOS operating system as well as Microsoft’s SONiC and Meta’s FBOSS. (Microsoft and Facebook are Arista’s largest customers, but they do not use EOS.) These modular switches, which are used in the leaf and spine of the F16 network, replace the whitebox Minipack and “OCP-inspired” Arista 7368X4 from 2019, which we talked about here three and a half years ago.
Here is the interesting thing, and it is consistent with the idea that high performance technologies created for hyperscalers, cloud builders, and HPC centers eventually get commercialized. During the keynote, Anshul Sadana, chief operating officer at Arista, said that over 100 different customers have deployed the Arista 7368X4 switch; presumably, the company is looking for a similar bump from the 7388X5 switch co-designed with Facebook. Celestica is making a similar bet with the designs it did with Broadcom and Cisco ASICs, we presume. It might take hundreds of customers to match the switch volumes of Facebook, but no switch maker wants to live by a few customers alone. That is far too dangerous, and possibly not all that profitable given the cut-throat pricing hyperscalers and cloud builders expect.
Top Of The Rack To You
There are two new top of rack switches that Meta is deploying in the Facebook networks right now: The Wedge 400, which is based on Broadcom’s Tomahawk 3 ASIC, which launched way back in January 2018, and the Wedge 400c, which is based on Cisco Systems’ Silicon One Q200L ASIC, which we detailed here. It is interesting that for the top of rack switches, Meta did not choose the Tomahawk 4 from Broadcom or the Silicon One G100 from Cisco, both of which drive 25.6 Tb/sec of aggregate bandwidth. The ASICs in Wedge 400 and Wedge 400c run at 12.8 Tb/sec; it all comes down to the interplay of price/performance, thermals, radix, availability, and what is actually needed at the server level.
Here is what the Wedge 400 and Wedge 400c switches look like from the outside:

You can’t tell what ASIC is in there, and that is the point. Facebook engineers don’t care, and Facebook users really don’t care.
The significant thing is that all of these switches going into the Facebook datacenters support SAI abstraction of the Broadcom and Cisco SDKs, and the interface between the two are the problem of Broadcom and Cisco, not Facebook engineers.
Here was another good point that Sadana brought up having to do with co-design and the relentless pursuit of energy efficiency as companies also try to push bandwidth:
“When you look at networking, one of the biggest challenges facing us today is as bandwidth increases, how do you contain power consumption,” explained Sadana. “The switches get more and more power hungry. They break the power allocation you have today for networking. And we managed to work together to create innovation, and the product here [referring to the 7388X5] has been designed without any gearboxes, despite all the breakouts and so on. This saves almost 20 percent of the power in this design. And on top of that, the same modules can support 200 Gb/sec or 400 Gb/sec – again, without requiring any gearboxes. I think that was really cool for the teams to come together and make it happen.”
Ram Velaga, general manager of the core switching group at Broadcom, joined Baldonado on stage and showed just how much the power curve for switch ASICs has been bent downwards as bandwidth has increased. In 2012, the “Trident-2” ASIC was the preferred merchant chip for datacenter switching at high scale, and it could drive 128 ports at 10 Gb/sec. With the Tomahawk-4 shipping now, Broadcom can drive 256 ports running at 100 Gb/sec – that’s twice as many ports at 10X the bandwidth, which is a factor of 20X more aggregate bandwidth. But the power per port and the power per bit shipped for the Tomahawk 4 are both 90 percent lower than with the Trident-2 ASIC.
That is what happens when a hyperscaler says no and tells engineers and chip designers to go back to the drawing board. Remember: HPC centers want performance and scale at any cost, but hyperscalers want price/performance at crazy scale, at an ever-improving cost. HPC has to beat time to find solutions, but hyperscalers have to beat Moore’s Law to stay in business with their “free” services and ad engines.




Be the first to comment