

The HPC community spends a lot of time tracking the development of and production use of the flagship machines deployed by the major national and academic labs of the world. This is always interesting, and fun. But the real workhorses of the 3,000 or so HPC centers on Earth are generally much smaller machines, doing smaller scale but no less real – and some would say more important – scientific research.
It is with this in mind that we contemplate the new “Lonestar” supercomputer being installed at the Texas Advanced Computing Center, which is housed at the University of Texas at Austin but which is a facility that houses computing capacity that is shared by many centers of higher learning in the Lone Star State as well as large scale clusters that are deployed under the auspices of the National Science Foundation.
In many ways, the Lonestar series of machines at TACC act as a testbed for the technologies that are sometimes later deployed in the much larger “Stampede” class systems. It has been a long time since the Lonestar 5 system was launched – we did a deep dive on the experimental nature of computing systems at TACC way back in December 2015 when Lonestar 5 was announced – but it is safe to say that in the six years since Lonestar 5 was installed, a lot has changed in compute, network, and storage, and the Lonestar 6 machine that is being funded by and shared by the University of North Texas, the University of Texas at Austin (two centers are paying their part of the bill), Texas A&M University, and Texas Tech University reflects this. Not only do these schools represent a long history of scientific research, but they also have played a lot of good football over the years. …
Some history of the Lonestar systems provides some perspective on the new Lonestar 6 machine. So let’s walk down memory row in the TACC datacenter.
The Lonestar 1 machine installed in 2002 was integrated by Cray and based on Dell PowerEdge 1750 servers and a Myrinet 2000 interconnect. The system had 300 nodes, each with a pair of 3.1 GHz Xeon processors, which means 600 cores, for a then very respectable 3.67 teraflops of peak performance. In 2004, this Lonestar 1 machine was boosted to 1,204 processors (and remember back then a processor was a core) and came in at 6.34 teraflops.
In 2006, Lonestar 2 was delivered based on Dell PowerEdge 1855 servers and a 10 Gb/sec SDR InfiniBand interconnect from Mellanox; it had 650 nodes based on a pair of dual-core Intel Xeon 5150 processors running at 2.66 GHz with a combined 2 TB of main memory across the nodes; it was rated at 8.32 gigaflops peak. TACC got some more funding together and added a bunch of Dell PowerEdge 1955 servers to create the Lonestar 3 system, boosting its performance to 55.5 teraflops. On the November 2006 Top500 supercomputer list, Lonestar 2 was ranked number 12, which is a very high ranking for this series of machines and which demonstrates that the capability class machines were in a lull as much as the capacity class machines like Lonestar were being built out from commodity parts.
It was another five years, until 2011, until we saw TACC deploy Lonestar 4, which cost $12 million. Lonestar 4 was based on a Dell blade server design and had 1,888 PowerEdge M610 blade servers, each with two six-core “Westmere” Xeon 5680 processors and 24 GB of main memory, for a total of 3,776 processors and 22,656 cores to deliver 301.8 teraflops of peak theoretical performance. Lonestar 4 had a 1 PB Lustre file system, and used a Mellanox 40 Gb/sec QDR InfiniBand interconnect to link the nodes together to share work. There were a number of nodes in the machine configured with fat memory, and a number of other ones that had Nvidia Tesla M2090 GPU accelerators, but mostly this machine was a CPU grunt like so many academic and government supercomputers are, even to this day, because they have a lot of software that has not been ported to accelerators.
We detailed the Lonestar 5 machine six years ago, but here are the specs in brief. The system has 1,252 nodes, each equipped with a pair of twelve-core “Haswell” Xeon E5-2690 processors running at 2.6 GHz. Each node in Lonestar 5, which has been recently decommissioned, had 64 GB of main memory and employed the Cray “Aries” XC dragonfly interconnect rather than InfiniBand. As with the prior Lonestar 4 machine, Lonestar 5 had a few fat memory nodes weighing in at 512 GB or 1 TB, and a handful of GPU-accelerated nodes that had Nvidia Tesla K40 GPU accelerators stuffed inside. The Cray XC40 design employed water-cooled cabinets, and the Lonestar 5 machine had its own 5 PB Lustre file system. All told, Lonestar 5 cost $10 million, and yielded a big jump in price/performance even as storage capacity went up by 5X. (Network bandwidth didn’t really change so much as did topology and adaptive routing by moving from 40 Gb/sec InfiniBand to 42 Gb/sec with Aries.)
This brings us to the new Lonestar 6 system, which is being built now by Dell and AMD, which is being funded by the schools mentioned above to the tune of $8.4 million. The system is using an interesting mix of dielectric liquid cooled racks and air-cooled racks. There are four of the dialectric coolant beds, which look like this:

And here are some of the ten air-cooled racks in the Lonestar 6 system:

Each of the Lonestar 6 nodes are based on a Dell PowerEdge servers that employ 64-core AMD “Milan” Epyc 7763 processors, which run at a 2.45 GHz base clock speed. The server nodes have 256 GB of memory each, and sixteen of them have a pair of Nvidia “Ampere” A100 GPU accelerators on them. The Lonestar 6 machine is interconnected using 200 Gb/sec HDR InfiniBand, and ports are running at that 200 Gb/sec full speed instead of being cut down to 100 Gb/sec using port splitters and thereby reducing the number of switches needed to interconnect the nodes into a fat tree configuration. That fat tree has sixteen HDR InfiniBand core switches. Interestingly, Lonestar 6 has an 8 PB BeeGFS parallel file system rather than the Lustre file system that TACC has preferred for many years on the Lonestar machines.
So, here is how the core count, performance, and bang for the buck has evolved between 2004 and 2021 for the Lonestar machines:
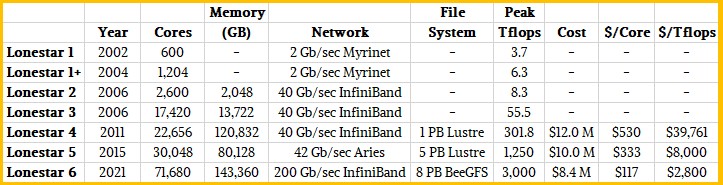
It is a pity that we don’t have the costs for the Lonestar 1, Lonestar 1+, Lonestar 2, and Lonestar 3 machines, but we suspect strongly that the cost of capacity was pretty high two decades ago. We do know how it has changed in the past decade, however. From Lonestar 4 to Lonestar 6, core counts have risen by 3.16X, but memory capacity is kinda all over the place. Network bandwidth is up 5X, the parallel file system is up by 8X, and the flops is up by just a hair under 10X. But the cost has gone down by 30 percent between Lonestar 4 and Lonestar 6, and that means the price/performance has improved by a factor of 14.2X. That’s a win for what is essentially a set of all-CPU machines. TACC is not getting the kind of bang for the buck that the centers installing exascale-class machines are getting this year and next, and we strongly suspect has always paid more per unit of compute than these centers throughout the generations. As have similar academic and government HPC labs. The smaller you are, the smaller your system, the higher the cost per unit of capacity. This is how economics works.
We did an analysis of the fastest supercomputers over time back in April 2015 and then again in April 2018 to make that point already. A massive GPU-accelerated machine like “Frontier” at Oak Ridge National Laboratory costs a little bit more than $300 per teraflops while the similar (but more commodity and and a little later to market) “El Capitan” machine at Lawrence Livermore National Laboratory will cost a little bit less than $300 per teraflops. (See this story for the math on this and a few other machines in deals done recently.) The point is, the HPC centers taking the biggest risks to blaze the trail get the best prices, and the rest of the HPC market gets an increasingly better deal over time, but always pays more at any given time.

Internet-Scale Video Requires Its Own Kind Of Supercomputing
Video has taken over the Internet, with almost 80 percent or so of the traffic being video. Datacenters over the past several years have increasingly relied on GPU accelerators to transcode the massive amount of video traffic running over networks, offloading much of the work from CPUs in hopes of …
Datacenter Will Be AMD’s Largest – And Most Profitable – Business
Two and a half years into the global coronavirus pandemic we all have upgraded our home IT infrastructure. And after several fibrillatory interest rate shocks by the major governments to try to curb inflation in the world economy, spending on PCs has consequently taken a nose dive. And a glut …
Can Nvidia Be The Biggest Chip Maker In The Datacenter?
Next year, with the launch of the “Grace” Arm server processors, Nvidia will have all of the compute and networking bases it cares about in the datacenter covered, and it will be selling its technology at a rapid pace. Nvidia already has a larger datacenter business than AMD has – …
Be the first to comment