

Graph processing at hyperscale has historically been a challenge because of the sheer complexity of algorithms and graph workflows. Alibaba has been tackling this issue via a project called GraphScope and was able to show a nearly 3X performance boost on a trillion-scale graph on its own production workloads.
Alibaba has deployed many deep learning frameworks for its ecommerce platforms but there are some workloads that achieve higher accuracy and performance using more traditional graph approaches. While AI/ML provides the backend driver for many of their services, the nuance of graph-derived results is critical, especially in areas like fraud detection.
The following chart from Alibaba shows the complex workflow for fraud detection in buyer-seller relationships, which are often collaborative crimes. There are elements of AI/ML in the mix but the end result, which must be delivered quickly, depends on fast, scalable execution across a massive graph.
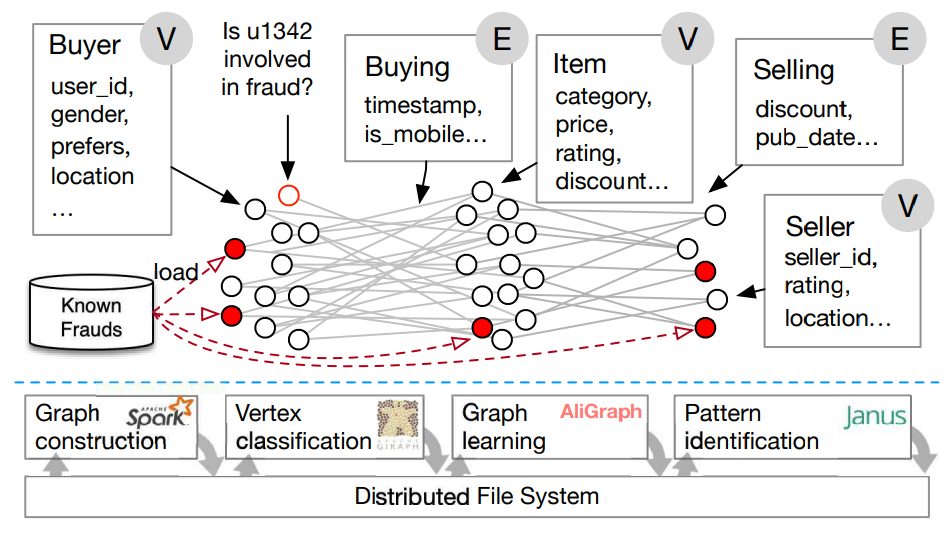
The interaction graph is constructed from data pulled from HDFS (one file system/storage example), then labeled (Apache Giraph) to look for possible fraud vertices, then Aligraph, Alibaba’s own graph processing framework, pokes around for possible connections. All of this is fed into TensorFlow (or similar) to score possible fraud with final intervention on a graph neural network model/database (in this case, Janus).
The point, there are many graph processing types and elements, from sampling to traversal to AI/ML, all working with other non-graph/ML systems.
This means different graph programming and runtime issues collide, low-level code issues arise, and bouncing between different systems (Spark, etc.) means a lot of extra data movement and handling. In short, the most accurate results leave behind a mess. That’s why GraphScope was developed.
Alibaba’s own tests with the new framework have proven higher performance and efficiency via a single high-level programming interface based on Python to avoid semantic conflicts, the ability for auto-compilation of sequential graph problems into distributed computations, and a new distributed in-memory store called Vineyard, that allows data to move between the various systems.
GraphScope outperforms state-of-the-art systems that are designed for different types of graph queries. It runs 2.86× faster than a manually assembled pipeline with complex, multi-staged processing on large graphs in a real-life application at Alibaba.
While fraud detection is the shining use case for Alibaba, there are other areas where similar multi-system graph executions run into similar problems. This includes in cybersecurity monitoring and recommendation systems for its ecommerce platform.
Distributed execution systems with high-level language support (e.g., Koalas, Dask, and TensorFlow) have been widely adopted for web-scale data analysis in a wide range of applications, such as e-commerce, on-line payments, and communication, largely attributed to ease of programming and scalability. However, the operator semantics provided by these systems is ill-suited to an important class of applications that require deeper analysis of complex interrelationships among data, where diverse analytics tools involving various graph computations are often called for instead.
Graphscope, is a collaborative development between Alibaba, its Ant Group spinoff, and the University of Edinburgh and Shenzhen’s Institute of Computing Sciences. A detailed description of the environment and test results can be found here.

Be the first to comment