

The Dutch national supercomputer, called “Cartesius,” which is used for HPC education and research, is getting rather long in the tooth with some of its components being installed as far back as 2013. So the government of the Netherlands and the SURF supercomputing center are shelling out €20 million to build a new and as yet unnamed system at the SURF facility in the Amsterdam Data Tower (shown in the feature image) in the Dutch capital.
Among architectural details, which we always find interesting, the deal to build this new system is interesting because Bull/Atos, the incumbent system supplier and clearly on the rise in the HPC sector in Europe, lost out to Lenovo, the heir to IBM’s former HPC business in Europe.
HPC compute capacity tends to scale, in a very general sense, with a country’s gross domestic product and its population size, and given that Holland has a GDP of around $1 trillion (17th in the world) and only 17.1 million people in its country (69th in the world), we would not expect for the Netherlands to have an exascale-class machine. Moreover, the Netherlands is a participant in the PRACE collective in Europe, and has access to pre-exascale and soon exascale machines in this fashion when its researchers and corporate customers need access.
The base Cartesius machine was eight years ago at the SURF center by French system maker Bull based on its Bullx B710 and Bullx B720 blade servers using 40 Gb/sec FDR InfiniBand as the interconnect between the nodes. There are a mix of Intel processor types in the machine, with 12,960 “Ivy Bridge” Xeon E5 cores (rated at 249 teraflops peak in aggregate floating point operations per second at double precision) in what SURF calls thin nodes. There are 25,920 cores based on “Haswell” Xeon E5s (rated at a combined 1.08 petaflops) and another 5,664 cores in thin nodes based on “Broadwell” Xeon E5s. There are also some fat nodes in the Cartesius based on even older “Sandy Bridge” Xeon E5s with an aggregate of 22 teraflops and 256 GB per node, plus a handful of nodes based on Intel’s now defunct “Knights Landing” Xeon Phi processors, but only with 1,152 cores driving 48 teraflops peak. (This is a more modern Bull Sequana system.) SURF has dabbled with GPU acceleration, too, and way back in 2014, GPU nodes were added to the system, powered by Nvidia Tesla K40m GPU accelerator cards, with a total of 1,056 Ivy Bridge cores and 132 GPUs with a total of 210 teraflops. If you add it all up, the combined system has 47,776 cores plus those GPUs that deliver a combined 1.84 petaflops of peak performance. The whole shebang has 130 TB of main memory and 7.7 PB of scratch parallel file system capacity.
The Ministry of Education, Culture, and Science is putting in €18 million through the Dutch Research Council (NWO) with SURF members putting up the remaining €2 million for Lenovo to build the new machine, which will be used to run both traditional HPC applications as well as new AI workloads in various areas, including materials science, earth science, climate modeling, weather forecasting, astrophysics, and various social and medical research. The SURF facility is used to teach computer science and do research across more than 100 organizations in the Netherlands.
Like many supercomputing centers that have to support a diversity of workloads and that are always under budget pressure, SURF has chosen to go with AMD Epyc processors for the core compute in its future supercomputer – why not give us a name now so we can use it? The first phase of the machine will be based on water-cooled, rack-mounted ThinkServer systems from Lenovo that employ current “Rome” Epyc 7H12 processors, which are the ones that AMD cooked up specifically for HPC customers back in September 2019 and which have 64 cores running at 2.6 GHz base and up to 3.3 GHz in boost mode with a 280 watt thermal envelope. Some of the nodes in the future Dutch national supercomputer will be based on the future generation “Milan” Epyc 7003s, and presumably whatever follow-on that is created to the Epyc 7H12. (You might easily guess an overclocked part called the Epyc 7H13 with 64 cores and lots more IPC per core and a little more clock speed per core.)
As with the current Cartesius system, some of the nodes in system will be equipped with GPU accelerators from Nvidia, and in particular, the ThinkServer nodes will employ the HGX system boards from Nvidia that hold four of its A100 GPU accelerator cards, based on the latest “Ampere” A100 GPU, which was announced last May. We do not know the node counts or core counts for these GPU accelerated nodes or the CPU-only nodes. But we do know is that this machine will be rated at around 14 petaflops at double precision and that the low precision flops for AI workloads running on the GPUs will come in at 90 petaflops. The statement from SURF said “petaflops” not “petaops” and that implies FP16 math for this metric. With sparse matrix support on, that would be 36 nodes and with sparse matrix support not used, that would be 72 nodes. So not very many GPU accelerated nodes.
People kept qualifying the FP64 performance improvement in the future SURF machine as being more than 10X more oomph than the Cartesius system, but by our math, it is around 7.6X more powerful than the current aggregation of FP64 compute in the final Cartesius system, which fell off the Top 500 supercomputer rankings last year.
The future Dutch supercomputer will have 12.4 PB of capacity running licensed Spectrum Scale (formerly General Parallel File System) code from IBM in Lenovo’s Distributed Storage System (DSS-G) storage arrays. The DSS-G storage runs on ThinkServer R650 servers with Red Hat Enterprise Linux 7 and has a mix of flash and disk storage for a balance of performance and price. That’s only 1.6X more capacity on a machine that is considerably more powerful than Cartesius.
On the networking front, SURF has chosen to go with the current 200 Gb/sec HDR InfiniBand interconnect from Nvidia (thanks to its purchase of Mellanox Technology last year). That is a 5X increase in interconnect bandwidth if the system has a single rail network and 10X if it is a dual rail configuration.
To help increase the power efficiency and density of the future SURF supercomputer and to support the 280-watt Epyc 7H12 processors in the Rome generation and what we presume will be 300 watt parts in the Milan generation should there be an Epyc 7H13 as we speculate, SURF is opting to use Lenovo’s Neptune water cooling on the system. The exact configuration of the rack and server cooling has not been revealed.
We always want to know what the prevailing cost of supercomputers are, but the data is sparse. Here is how the future SURF machine compares to four other recent ones announced, all based on AMD CPUs and some with AMD GPUs as well.
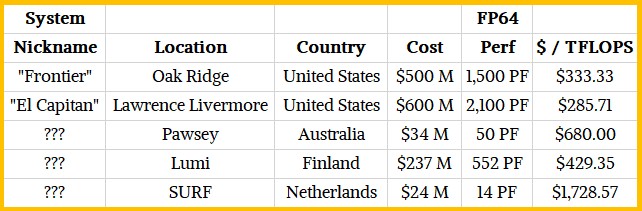
The main thing to notice is the research discount and volume discount effects of the big exascale-class machines. Their cost per unit of FP64 compute is very low, and that is in part because of the volume of compute engines as well as the inherently lower cost per compute for GPU acceleration. Both “Frontier” at Oak Ridge National Laboratory this year and “El Capitan” at Lawrence Livermore National Laboratory next year have one AMD Epyc CPU for every four AMD Instinct GPU accelerators. About half of the nodes at Pawsey have AMD GPUs paired with AMD CPUs, the other half have CPU-only nodes. And because the node count is lower and the GPU density is lower, the cost per unit of compute is higher. And for research clusters like the future SURF machine, there is a strong tendency to use CPU-only nodes because a lot of research and academic codes have not yet been ported to GPUs. And as you can see, for a relatively modest cluster – even one based on relatively inexpensive AMD CPUs – because of the lower volume and the increased dependence on CPU compute, the cost per teraflops is considerably higher.
Installation of this new SURF supercomputer will begin this month, with the machine expected to be operational by the middle of 2021.

Lumi will be installed in Finland.
Of course it is. Fixed, and thanks for the catch.
data is sparse not spare. Cool article, thx.
It could be both. But sparse is what I was shooting for. Funny how the spellchecker missed that….