

While the promise of neuromorphic computing going mainstream is still mostly unrealized, there are steps being taken to bring it closer to reality. Spiking neural networks (SNNs) have potential, especially in inference, for far lower power consumption and good performance for certain applications in ML but mapping these problems onto actual devices takes quite a bit of work.
One of the most discussed neuromorphic architectures, the Loihi device from Intel, might jump ahead of the relatively few others in the space (IBM’s True North and the research-centered SpiNNaker devices). This is because of some new work to create an API and compiler that can translate traditional neural networks to run on Loihi without the low-level programming that has been required to date, despite existing programming abstractions, firmware and compilers inherent to all existing neuromorphic platforms.
Recall that Loihi is the most recent iteration of Intel’s neuromorphic activities. Released in 2017, the 14nm device has 128 “neurocores” each of which supports up to 1024 neurons with the help of three small CPUs per chip for management. It is purely an asynchronous spiking neural network-focused, which means the use cases are limited to certain event-driven workloads. As one might imagine, Loihi and other neuromorphic devices could be well-suited in financial services as well as edge-based near real-time applications for a range of enterprise use cases, as evidenced by the range of form factors for Loihi, including a 2-chip USB-based device all the way up to the ambitious 768-chip rack called “Poihiki Springs”. In other words, the stakes are high in terms of potential payoff for the years of R&D Intel and IBM have put into neuromorphic computing if they can just make the devices usable by non-specialists.
To be fair, the new software platform, Intel NxTF, still comes with a fair amount of complexity, but it’s not down to the previous level of near-manually defining neural networks at the individual cell level and determining how to connect the synapses and axons along variable learning rules.
At its core, NxTF is a programmatic interface based on Keras that is designed to map spiking neural networks onto Intel’s Loihi neuromorphic architecture. It based on a collaboration between Intel and researchers from the Redwood Center for Theoretical Neuroscience at UC Berkeley and the Neuroinformatics division at ETH Zurich. As the team explains, “NxTF trades generality for an application focus towards deep SNNs. The objective is achieved by inheriting from the Keras Model and Layer interace and providing a specialized DNN compiler.” They add that to compress large DNNs on Loihi, the compiler “exploits the regular structure of typically DNN topologies like convolutional neural networks in combination with Loihi’s ability to share connective states.”
Below is a better graphical sense of this from a workflow perspective:
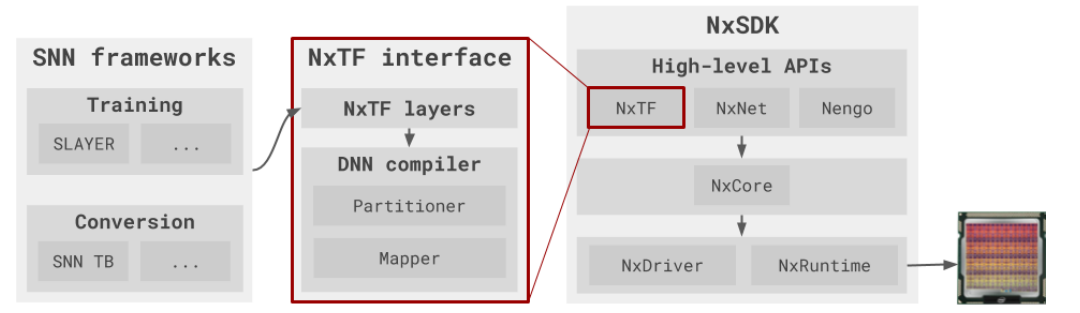
The NkSDK software stack and workflow to configure a deep SNN on Loihi. Starting from a trained or converted SNN, the user defines a model in Python using the Keras-derived NxTF interface. The network is then partitioned and mapped onto Loihi by the DNN compiler via the register-level NxCore API. The NxDriver and NxRuntime components are responsible for interaction and execution of the SNN on Loihi.
One interesting note is that while there are certain aspects of NxTF that are tailored to Loihi, the researchers say there are several elements that are general enough to be adopted in other SNN hardware, such as the Keras-derived API or the partition optimization strategy. Despite potential for some cross-functionality, there is no way to compare the broad sets of results of the work to other devices and their software stack since everything from network topologies to conversion are so different.
The team has evaluated NxTF on both spiking and convolutional neural networks in addition to models converted from traditional deep neural networks, including both sparse, dense, and event-based datasets. They also tested NxTF’s scalability across large core counts and compressed models via a novel weight-sharing feature. There are far more examples in the paper but among them, it is worth noting that the compiler achieves near optimal resource utilization of 80% across Loihi based on a 28-layer, 4 million parameter MobileNet model (input size 128 x 128) with an 8.52% error rate.
As the team developed the framework some of the issues that arose were beyond their control in many instances, particularly in terms of hardware architecture. They say that they can get high resource utilization for many of the DNNs but memory utilization is held back, something that could be fixed with a shared memory architecture that could “allow to trade on-chip neuron, synapse, or axon resources off against each other to ensure near 100% memory utilization on every neurocore.” They also see room for improvement via providing support for dedicated CNN compression to save on-chip memory resource along with a built-in soft reset to “eliminate the need to duplicate neuron compartments.”
For those interested the source code for NxTF is here and the original paper is here.

Sandia Pushes The Neuromorphic AI Envelope With Hala Point “Supercomputer”
Not many devices in the datacenter have been etched with the Intel 4 process, which is the chip maker’s spin on 7 nanometer extreme ultraviolet immersion lithography. But Intel’s Loihi 2 neuromorphic processor is one of them, and Sandia National Laboratories is firing up a supercomputer with 1,152 of them …

Intel Smells Neuromorphic Opportunity
Neuromorphic computing has a rather long way to go before it becomes an accepted part of systems. Like its quantum brethren, mapping problems to the architecture is still a heady challenge even though a few use cases show remarkable promise. Further, just as with quantum computing, most major chip and …

A First Look at Intel’s Next-Level Neuromorphic Engine
Intel is still placing bets on neuromorphic computing with its Loihi devices. While the datacenter hook for the architecture might take a second seat to embedded and edge use cases, at least for now, its second generation device shows commitment to the concept — as does the new open-source software …
Be the first to comment