

For those who are at the intersection of AI hardware and software, the open source Apache TVM effort is already well known and used among a number of chipmakers as well as developers. It is a machine learning compiler framework that can meet devices at the edge to datacenter with optimized configurations no matter the target hardware.
If it wasn’t already in use by AMD, Qualcomm, Arm, Xilinx, Amazon, and many others, it might smack of that “magic compiler” mojo some of the AI chip startups began with a few years ago. The idea that machine learning models don’t need to be uniquely hand-tailored to individual hardware devices expanding potential for hardware startups and established vendors alike. And now might be its time to really shine as a standard base for new AI hardware to roll into production without the heavy burden on users to adopt an architecture-specific approach. There are, after all, plenty of devices for ML acceleration to choose from.
“There has been a proliferation of hardware targets and that has been fragmented, and so too has the software ecosystem around those. There’s TensorFlow, Keras, PyTorch, and so on not to mention the increasingly complex interplay between ML models, software frameworks, and hardware,” says Luis Ceze, professor at the University of Washington and co-founder and co-CEO of TVM-driven startup, OctoML. “The way these software stacks work now are use case specific or hardware specific (cuDNN, ROCm, etc) and these are all optimized by hand via an army of low-level engineers scrubbing linear algebra codes that connect the ML operator in the models into the hardware with a tuned hardware library.” This has worked well for the vendors but in terms of capitalizing on the “Cambrian Explosion” of hardware devices, it is limiting.
In essence, TVM is a compiler plus runtime stack with a collection of intermediate representations that translate the models expressed in high-level frameworks (TensorFlow, PyTorch, etc.) into something that can be “re-targetable” to different hardware architectures—anything from server-class GPUs to low end mobile CPUs or even MIPS or RISC-V. This is good news for hardware vendors who want to get models running on their new hardware, especially given the time and cost to develop highly-tuned software stacks and even better news for those experimenting with different devices since TVM is portable, meaning you can build a model once and deploy it on almost any hardware TVM supports. Right now, that list includes nearly all major hardware vendors as well as several startups.
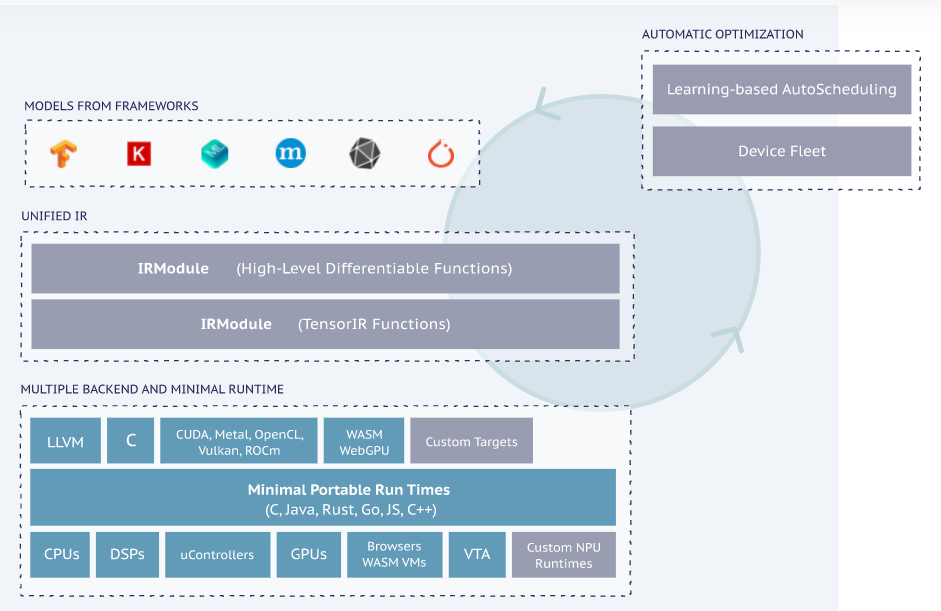
The flow of compilation of deep learning models into smaller deployable modules as well as the infrastructure to automatically generate and optimize models on more architectures with better performance—between 2X-10X versus human on average, according to Ceze.
Andrew Richards, CEO of Codeplay, which is also focused on bridging the hardware/software divide for AI adds, “The open research challenge for these kinds of techniques is how to apply them to all the different operations you might want to run on an AI accelerator. AI is a field of extremely active research, with new operations being invented daily. Running old neural networks fast on new hardware isn’t the real challenge: we need to run new neural networks on new hardware.”
“Too many AI hardware companies struggle to run the latest benchmarks. To advance both the fields of AI hardware and AI software,” Richard continues. “We need to combine the auto-tuning capabilities of graph compilers like TVM that hardware designers need, with the general programmability of programming languages like C++ or Python that AI researchers need. That challenge is what makes this field exciting”
It is exactly this kind of momentum Ceze and his team at OctoML, the company commercializing support for TVM are banking on. “There is opportunity among both platform providers who want to let users run models on new hardware. For instance, one runs computer vision a large scale in the cloud over video repositories to do content moderation. We were able to show 10X better performance with our Optimizer.” For ML engineers, which he says represent a growing set of their users, “they’re getting tired of worrying about to deploy their models. Data science is hard enough; if you have to think about hardware deployments during model creation that’s not productive. That’s why people are coming to TVM and to us—to focus on the models they want to run, not how they’ll run them given a specific hardware target.”
As we’ve seen over the years, commercializing open source can be lucrative if it’s the right thing at the right time. If there was ever a better moment to make deploying different hardware it is not when options are proliferating. While TVM has a wide base of commits (about two-thirds are from industry/hardware makers) Ceze thinks there will be enough value in their ability to take info about the type and number of models, hardware targets, level of complexity and number of deployments and spin it into gold. He says that as a very general (he stresses that this is just one project, each subscription will depend on the factors just stated) a mid-scale computer vision based model for cloud would cost around $10-$15k per month.
“The value we offer is that you get an easier to use experience, access to our cost models based on our very heterogeneous collection of all the major chips and models, and those are constantly being optimized.”
So far, the company has raised $19 million in seed and Series A and while some of its biggest (verified) customers are under NDA, consider most major chipmakers (with a couple of notable exceptions, Intel and Nvidia—not a surprise on either count, especially with Nvidia and its cuDNN) part of their base in addition to cloud providers with their own ASICs and a few industrial giants.
Whether or not there is a big enough business in support for TVM remains to be seen but what is worth recognizing, even for those outside of the software side of the AI chip ecosystem, is that the software, while a differentiating factor for the startups in particular, can start to become less overhead as time goes on. As the open source base develops we can expect broader support for more devices and a more tractable way for developers to try out different architectures, something that has kept architectural experimentation at bay.


Cracking Nuclear Fusion With Supercomputers And Smart Code
Nuclear fusion, the opportunity to harness the power of the stars, has been a dream of humanity from around the time of the Manhattan Project. But while making bombs has been readily achieved, controlling the process for thermonuclear fusion for civilian use has been frustratingly elusive. Nuclear fusion could be …
Be the first to comment