

There could be a new era of codesign dawning for machine learning, one that moves away from the training and inference separations and toward far less dense networks with highly sparse weights and activations. While 2020 was peak custom AI chip, it could be that the years ahead feature devices we already know but with re-imagined circuits that get us closer to that brain-like efficiency, performance, and continuous learning that has been the golden grail of AI since the beginning.
There could be nothing further from human brain function in learning than what we have now: dense networks, unpacked in batches on massive matrix multiplication units that are then fed into a separate, albeit lower-power capable inference phase. While neuroscience is often the touted inspiration for almost all we’ve heard from the AI chip startups and established accelerator vendors over the years, the hardware doesn’t meet the theory in the middle.
Emphasizing sparsity, both in terms of devices and frameworks, has been another area where there has been plenty of lip service but ultimately, especially for accelerators that want to do both training, inference, and general compute workloads cannot be fit into the sparsity mold—for good reasons. But if the training and inference steps are no longer separate, if learning is continuous and doesn’t need to conform to the batch-driven notion of “forgetting” what it’s learned to move on to something new, a truly new paradigm opens for machine learning.
The interesting part is that the elements to have super-sparse networks, with ultra-sparse weights and activations are all there. What’s missing is the hardware that can exploit huge sparsity but even that isn’t so out of reach. Optimized circuitry is more within reach than bringing custom silicon to market and so far has shown some rather dramatic improvements over existing high-test GPUs or off-the-shelf, unoptimized FPGAs.
The trick to ultra-efficient devices that actually deliver on the brain-like computing promise is not just about codesign with sparsity in mind. It’s about how this allows for continuous learning, thus removing the distinct training and inference phases and all their custom hardware and tooling.
Sparsity is a core component of continuous learning because when you have sparse representations at the core it’s possible to keep learning without new input inferring with what’s come before—learning without forgetting, just as the brain does. However, traditional AI/ML frameworks are optimized for distinct, batched training then inference phases. “Sparsity is just the start of it, says Subutai Ahmad, VP of Research and Engineering, Numenta, a research company that is testing the sparsity/codesign problem. “There are a number of other components to the future of continuous learning over time like how neurons process sparse information, then how they interact with cortical columns—the common cortical algorithm that uses sparse representations but builds true sensory models of the world.”
“A major challenge faced by these networks is an inability to learn continuously. As new data arrives, a large model needs to be retrained in batch mode in order to update it, using huge additional resources. Our brains adapt continuously with each new data point. Moreover, today’s machine learning models require supervised learning with labeled data while your brain is able to rapidly classify similar objects without labeling. The Thousand Brains Theory neuron model describes how a brain is continuously updated and how it learns without supervision. In the future we can apply these techniques to machine learning in order to enable continuous learning and unsupervised learning.”
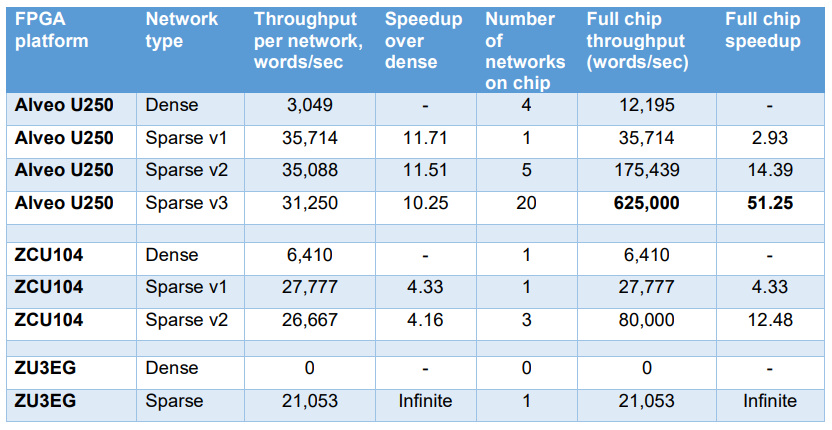
Ahmad and team at Numenta, which has roots in computer vision and neuroscience research and product development, has proven out this concept on FPGA. Using an Alveo U250 (Xilinx) datacenter-class card to parse a 3-layer network with sparse convolutional kernels, weights, and activations, they were able to show some serious efficiency and performance improvements. The whitepaper is here but in a nutshell, they showed that sparse networks provide 50X more throughput than dense networks over a V100 GPU. Each network is sparse (meaning it can focus only on non-zero multiples) and since the networks are smaller with far fewer weights, it’s possible to fit 5X as many sparse networks on a single device. The full chip throughput is 51x faster than equivalent dense networks. In other words, each network is faster and it’s possible to fit more networks per chip. This was for an inference workload but training should show similar benefits. Still, separating training and inference isn’t the ultimate goal, although that will take a lot of work, down to a rip and replace of common AI/ML frameworks that are designed for the batch world.
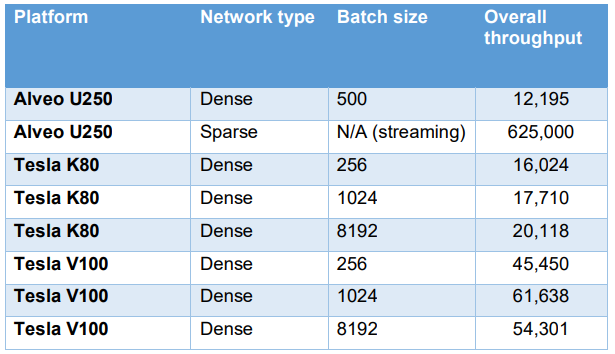
Throughput for dense networks on two GPU platforms for different batch sizes. This sparse network approach appears to significantly outperform all dense implementations.
“On a per network basis, sparse networks are also significantly faster than dense networks on all platforms. On the Alveo U250 the sparse networks are more than 10 times faster than dense networks. On the ZCU104, a single sparse network is more than 4 times faster than a single dense network. Note that the per network speed drops by about 10% more networks are packed on chip (from 35,714 words/sec to 31,250 words/sec on the Alveo U250). This effect is likely due to communication bottlenecks, since the amount of data that has to be transferred per second grows with the number of networks running in parallel. Still, the gain in overall throughput is far more than the drop in each network’s speed.”
“Down the road, if manufacturers can incorporate circuits that are suited to sparsity that would dramatically accelerate beyond what we did her on FPGA. Right now circuits for GPUs are optimized for dense matrix multiplication, there should be some nod to optimizing for sparse computation eventually as well,” Ahmad says.
Numenta is a research lab (i.e. technology patent developer) first, but they do have a license-based business that lets interested parties deploy sparse ML that works on their applications. This technology provides sparse convolutional and linear kernels as developed for the FPGA experiment above, along with custom logic they’ve implemented in addition to code to actually be able to use the sparse networks to train using PyTorch or Tensorflow. If this was pre-FPGA acquisition mayhem as we saw over the last few years, most recently with AMD/Xilinx, it would not be unreasonable to see a Xilinx or Altera (now Intel or AMD) buying Numenta to provide ready-to-roll sparse CNN capabilities and a software stack to support it. As it is now, it seems the FPGA space is still waiting to see where the chips fall (literally) among the AI hardware startups scrambling for that side of the accelerator market and then do their own overlaying and tweaking based on what’s left, in training at least. Inference may be a separate story for FPGAs, at least for datacenter.
Aside from providing something near-term for CNNs, as mentioned earlier, the golden grail for the AI market will be to (finally) meet the long-heralded promise of brain-like, low-power, low-overhead continuous learning. These first forays into sparse networks, just by focusing on training/inference separately for now represent an important first step down the road to continual learning, although it’s hard to say how many miles it goes on.




From a product reliability and testing point if view, continuous learning could lead to unexpected behaviour similar to a teen-ager deciding to learn how fast the family automobile can go on the freeway. In my opinion this is not the holy grail of AI.
What makes AI potentially more useful that hiring a bunch of human workers to do the same thing is that AI doesn’t start experimenting with shortcuts in the middle of doing what it is supposed to do. This and other differences between AI and human intelligence are what make AI potentially useful. In particular, the ability to switch off the learning aspects of an AI model is what leads to predictable behaviour and that’s extremely important.
The most impressive number in this article is >10x streaming throughput vs. GPUs (BTW streaming usually has a batch size of 1 instead of N/A, Please see Microsoft Brainwave paper for reference). Streaming and massive connectivity have always been “a forte” of FPGAs in tele, data, and other comms. These ace cards have not been played well by FPGAs in current AI offerings. While sparse xNNs are faster indeed, connectivity also will break single chip barrier and FPGA can take multichip computing path of GPUs And CPUs.
On a side note, I would question the appearance of ZU3EG with infinite speedups. Perhaps someone formatting tables in the future should pay attention to division by zero?
Sparse neural networks look a lot like circuits – i.e. the matrix math is similar to what you see in (fast-) SPICE. That implies that (analog) circuits can be built (as ASICs) with the same behavior, and those will hit performance levels well beyond FPGA/GPU.