
No matter how established any market is, there is always the churning and burning of change happening and there is always an opportunity for new players to carve out a place for themselves in new niches.
So it is with system suppliers who are defining and manufacturing machinery and stacking up and integrating software to support machine learning and other related artificial intelligence and data analytics workloads – and even sometimes adjacent traditional HPC workloads that now often have an AI component to them. One such supplier is Lambda Labs, a San Francisco startup that has Apple, MIT, Amazon Research, Tencent, Los Alamos National Laboratory, Stanford University, Harvard University, Kaiser Permanente, Anthem, and the US Department of Defense as some of its marquee customers. Who are the people behind Lambda Labs, and how are they different from the big OEMs and ODMs that seem to dominate the server space? We wanted to know, so we talked to the company’s founders to find out.
Brothers Stephen Balaban and Michael Balaban, who founded Lambda Labs in 2013, clearly like to do similar things and often like to do them together. (Yes, this is one of those stories where we have to use full names because the two key people share the same last name. It doesn’t happen often here at The Next Platform, and much less so when they are related.) Stephen Balaban, who is the chief executive officer at Lambda Labs, got a double major bachelor’s degree in economics and computer science from the University Of Michigan in 2011 and then was the first hire in late 2012 as a software engineer at a company called Perceptio, which created neural networks for facial recognition that ran locally on the GPUs embedded in Apple’s iPhone smartphones. That stint didn’t last long because Apple snapped up Perceptio in August 2013, only ten months later. A few months later, Stephen Balaban founded Lambda Labs, with the idea of building a cloud that could run machine learning workloads for customers.
Michael Balaban, who is the head of engineering at Lambda Labs, also did a double major at the University of Michigan, but combined discrete mathematics with computer science and got out of school a year later than his brother in 2012. After graduating, the younger Balaban took a job as a software engineer on the infrastructure team at the social networking upstart Nextdoor, where he learned to scale its infrastructure – particularly its news feed – from 300,000 people to 100 million people, and was the principal architect of the company’s ad server engines, as well as working with his brother as a co-founder of Lambda Labs. In March 2015, as Lambda Labs was starting to make a name for itself, Michael joined Stephen full time at the company.
“So he had this AI background and I had this infrastructure background, running lots of servers, and when we were working at the company together full time, we didn’t know exactly what it might look like,” Michael Balaban tells The Next Platform. “We were both interested in artificial intelligence, and specifically deep learning, and we were reading through the AI literature for interesting projects to implement. At that time in 2015, there was a paper published called A Neural Network of Artistic Style, and it showed how to take any selfie and turn it into the artistic style of any work of art in the world, Picasso or Van Gogh or whatever. We though this was pretty cool, and we threw up a website with an iPhone app to see if anyone was interested in it. We started with one GPU server on Amazon Web Services, which was quite expensive, but it was only one server. We did a post on Reddit, and it absolutely took off. We got a ton of press and at one point we were getting 30,000 people a day signing up.”
This was very exciting, of course, for the Balabans, but as the user base grew the compute capacity needed skyrocketed and the AWS bill was growing exponentially. And the company was projecting that it would run out of money in two to three months.
“So we did some research and we looked at Amazon’s machines in particular, and people treat them like they are these magical boxes, but they are just normal hardware,” explains Michael Balaban. “And we looked at what AWS was doing and we realized we could just build machines like that for significantly less money. We had a $40,000 a month AWS bill, but we could build capacity for $60,000 and it would pay for itself in a month and a half. It was a very clear return on investment for us, and I realize that the times are different and the hardware is different today, so we have a slightly different view today.”
The problem was not buying parts and building machines. Getting facilities and paying for the power was. Co-location was expensive, but they had a friend with a big mansion with lots of power, and he let them put a baby datacenter in his house, and after that, the AWS bill dropped by 95 percent because all AWS was doing was the front end.
“We realized at the end of 2016 and into early 2017 that there were tons of other people interested in AI who were experiencing the same exact problem, that they were spending tons of money on AWS and at that rate, they were going to run out of money,” says Michael Balaban. We had developed expertise in infrastructure and in AI, and there was no company focusing just on this at the time, and those companies that were selling AI servers had their machines pushed by sales people, not by AI experts. They are not highly technical, but we were. So when we started selling our servers online – interestingly enough on Amazon’s online store – we realized this was just a better business than that AI application we had developed.”
The trick with any niche is to understand it really well, and the Balabans had run AI infrastructure at a scale that dwarfed that of most of its customers who were just getting started with AI and were discovering how useful and how expensive it might be (on the cloud at least). They spoke the same language as their customers, and had experienced the same budget pressures.
“When we did that pivot at the end of 2016, we got a lot of our initial interest in the research community, particularly at universities and colleges,” continues Stephen Balaban. “We have continued to grow in that market. If you do a sort of the top research universities by endowment, we are in 47 of the top 50. We are trying to close off the last three.”
The Balabans had some seed funding to get the company going in earnest back in 2015, and in 2017 the company took some additional funding from Gradient Ventures, the AI venture capital arm of search engine giant Google. This funding round, which has not been disclosed, help Lambda Labs really grow the company, according to Stephen Balaban, and it has been profitable since that time. (It may seem odd that Google would invest in a hardware company, but there you have it.) Scott McNealy, one of the co-founders of Sun Microsystems and its long-time and very boisterous chief executive officer, is an advisor to Lambda Labs and Robert Youngjohns, who used to run Sun’s sales organization for many years, is the independent director at Lambda Labs. Three decades ago, Sun had to design its own chips to help create the Unix server business and become the dot in dot-com, but Lambda Labs does not need to go that far with so many different compute engines available today. It doesn’t hurt to have McNealy and Youngjohns helping the Balabans avoid some of the mistakes that Sun made, causing it to disappear into Oracle when the Balabans were still in high school.
Lambda Labs has nearly 30 people these days, and as the Balabans put it, they “do quite a lot with a very small team.” That, of course, is what all niche players do. The company does not disclose its financial results, but Stephen Balaban says that the company has had two back-to-back years of tripling revenues, which speaks pretty well to the tack Lambda labs has taken first with delivering its GPU-powered Lambda Quad workstations and then Lambda Blade GPU servers back in 2017. The Lambda GPU Cloud was formally announced in 2018, although the company had been running cloudy infrastructure for many years, and its Lambda Stack of deep learning tools, including TensorFlow, Keras, and Caffe frameworks and the Nvidia CUDA stack and drivers running atop Ubuntu Server, followed in 2018. In 2019, Lambda Labs notably published a paper describing a generative adversarial network (GAN) it had created with Twitter and the University of Bath called HoloGAN.
In more recent years, the Balabans have been working to create a more fine-tuned cloud for deep learning workloads while at the same time advancing the state of the art in deep learning hardware design. And that is because they have a hybrid view of the world where companies will want to develop machine learning algorithms locally and sometimes run them locally, but also burst out to a cloud – and one that costs less than AWS when loaded up with AI accelerators. In this regard, they are creating a new category, something we might call a hybridscaler.
At the moment, GPUs from Nvidia figure prominently in both the hardware Lambda Labs sells as well as the capacity it runs on its cloud, as do Intel CPUs. But there is no saying that it will have to be that way in the future. AMD sells credible CPUs and GPUs now, Nvidia is getting into Arm server processors in one way or the other, and Intel is getting into GPUs. But the forthcoming Lambda Cloud is going to be about more than benefitting from the price war between component suppliers that comprise the vast majority of the cost of machine learning iron.
The Balabans are not giving out too many details about what they are thinking, but they drop a few hints about how they might improve their AI clouds, which are currently located in California and Texas but may not stay there.
As Michael Balaban puts it, Amazon Web Services was designed predominantly as an e-commerce platform, and as such the high availability and low latency required for those workloads means a datacenter gets designed with all kinds of redundancy because losing an hour of processing can mean a huge amount of economic damage for the customers who run their applications on the cloud. But with AI research, what is the economic damage of having an outage for machine learning training workloads for an hour when the run is going to take three days? In this case, latency between user and compute farm is not an issue if the data is already on the cloud, and the availability and reliability of the power grid is the big concern for the datacenter.
The power density and cooling of datacenters can also be pushed to different limits in a datacenter that is focused on AI, too. In the typical cloud datacenter, says Michael Balaban, companies can get 11 kilowatts to maybe 14 kilowatts of power and cooling with cold aisle containment; with chillers in the racks, you can push that density up to 50 kilowatts, saving a lot of space for the datacenter.
On the AI system front, Lambda Labs has just rolled out its Echelon clusters, which come preconfigured at the rack level with compute, storage, and networking necessary to support distributed training of neural networks at a large scale.
The Echelon clusters can be equipped with the Lambda Blade servers, which pack up to ten Nvidia GPU accelerators into a chassis using PCI-Express switching to link the GPUs to each other and to the CPUs. The Volta V100 and Ampere A100 GPUs are supported in these machines, which in turn can have a pair of Intel Xeon SP or AMD Epyc CPUs. For certain workloads, Nvidia GeForce or Quadro cards can be used as well. The Echelon racks can be equipped with the Lambda Hyperplane servers, which have four, eight, or sixteen Nvidia GPU accelerators linked by NVLink interconnects and Intel Xeon SP host processors, and these seem to be the big machines for training:
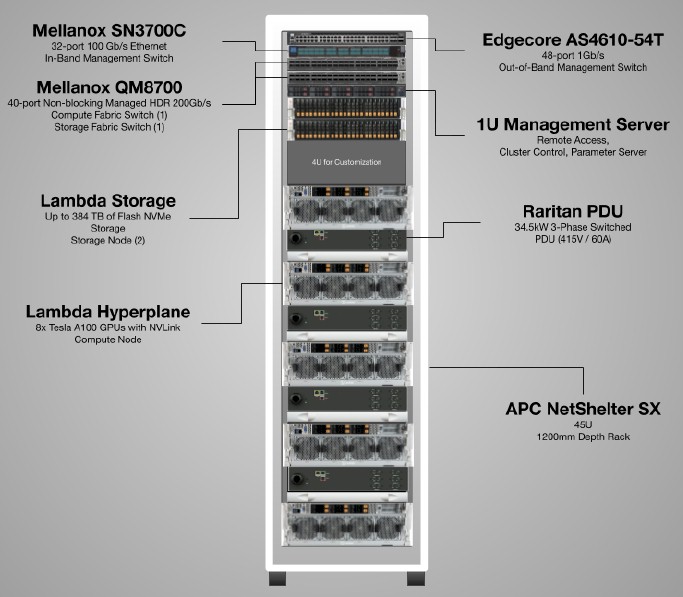
The server nodes in the racks are linked with eight 200 Gb/sec HDR InfiniBand adapters from Nvidia, and the nodes are linked with a spine and leaf topology using rack switches rather than a modular switch, which is a lot more expensive. The stock storage is a commodity ZFS storage system, but companies can add the storage of their choice – Lambda Labs has relationships to hook in VAST Data Universal Storage, WekaIO WekaFS, Quantum ActiveScale, and SoftIron HyperDrive. Similarly, companies can change up the networking to Ethernet if they so desire, but will probably want RDMA support to goose the performance of AI training.
The base Echelon rack is designed to cram 40 GPUs into a 45U rack within a 37 kilowatt power envelope. The next size up is four racks, with 160 GPUs, and the largest size is twenty racks at 800 GPUs. The Echelon rack costs somewhere on the order of $650,000, which is a lot less expensive than Nvidia’s DGX racks with the same V100 GPUs in them, which might cost twice as much as that at $1.2 million, according to the Balabans. And the Echelon rack can scale down to $500,000 or even lower depending on the GPUs and CPUs chosen and the networking within and between the nodes.

Lambda Snags $320 Million To Grow Its Rent-A-GPU Cloud
Riding high on the AI hype cycle, Lambda – formerly known as Lambda Labs and well known to readers of The Next Platform – has received a $320 million cash infusion to expand its GPU cloud to support training clusters spanning thousands of Nvidia’s top specced accelerators. This will include …

Where Portable AI Training Makes Sense
It is rare to find a story here at The Next Platform that does not focus on systems for large-scale use cases. However, given that AI training has been a driver for high-end, GPU-laden systems over the last four years or so, we wanted to give some thought to how …
Balancing Performance, Capacity, And Budget For AI Training
If the world was not a complex place, and if all machine learning training looked more or less the same, then there would only be one accelerator to goose training workloads. Nvidia sometimes talks that way, as if all anyone needed to do was to buy a bunch of A100 …
Comment after many years of reading TPM. Your’re amazing. Stay well. Can’t wait to continue the adventure into 2021 and beyond – with understanding and extraordinary insight from TPM. Thank you so much !!! Ed Ernst
Thanks, Ed. You made me blush. . . I love what I do, and in 2021, I am going to try to get more of it done. Thanks for the kind words of encouragement. It means a lot to me. Happy holidays, and don’t forget to have a drink or two.
Regarding the application it’s possible that most of the clients at the time were early adopters and knew a lot about how to use AI for specific tasks, so even if they didn’t use ML directly, they wanted to try it out.