

Although hardware gets all the attention during Supercomputing week, much has been happening behind the scenes to make all the software run on the latest, fastest systems.
There are many problems when it comes to creating and deploying scientific packages, not the least of which are the sheer number of architectures to tune to. Further, teams often need to be able to ship work around all the while minimizing how much code they write. Versioning is a nightmare (one change can have a cascading effect) and for HPC, there are many parameters to adjust (versions, compilers, build options, microarchitecture, GPUs, etc.) and often, each build ends up being its own specialized effort where incompatibilities aren’t known until developers find them.
Until relatively recently, there was no automated, optimized ways to automate deployment on these machines and while there were package managers, they were built more for the sake of saving time and not necessarily for allowing prime use of the software on multiple architectures.
The open source Spack effort sought to fill gaps in customization and configurability where other efforts lagged, something that is more important given the broader architectural diversity in supercomputing. Spack is now the deployment mechanism for the world’s top supercomputer with its Arm base, Fugaku, and has been and 1300 packages on the Summit machine were handled by Spack. It is expected to get further momentum with the future exascale systems as well, according to Todd Gamblin, one of the founders of the Spack open source effort, which has roots at Lawrence Livermore National Lab.
“If you look at the mainstream package managers, they’re making assumptions about your software stack and will build everything that way, thus they force consistency. But there is no consistency in HPC,” says Gablin. “We had to parameterize a lot of things you don’t have to worry about in the cloud, for instance, where everything is vanilla, x86 Linux node based. That’s where we’re different—where we had to be different because of the specific requirements of HPC. With Spack, you can build packages, target microarchitectures, inject flags, build options, build one package with six different compilers…there’s just a lot of capability because that’s what HPC needs,” he adds.
One of the reasons Spack and competitive efforts are worthy of remark this week as several new systems are announced, is because of the growing complexity and dependency issues for HPC software. Gamblin highlights this below. The manual hours needed to keep pace with this, just to get it up and running (nevermind optimized) would be weeks.
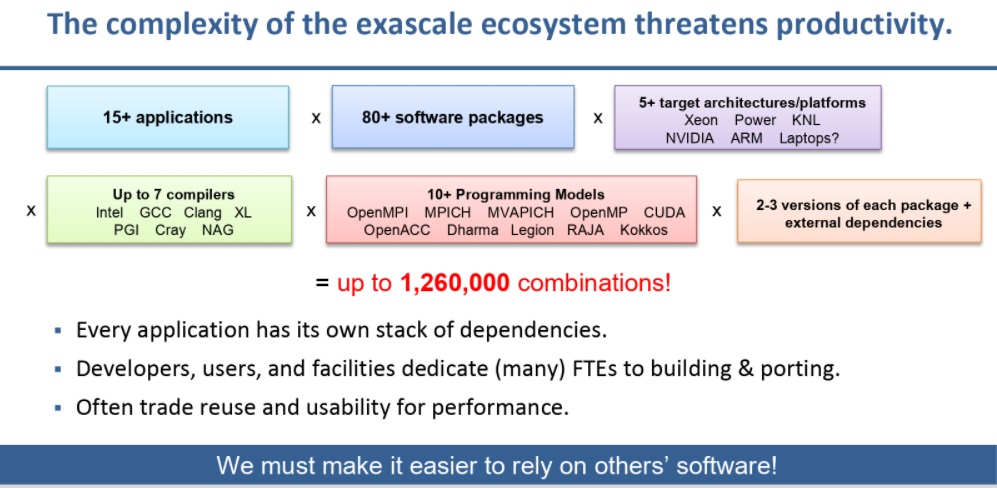
The project has upwards of 3200 users each month with around one thousand people in the Spack Slack asking questions daily. In addition to being used as a package manager for deploying on new systems it is also used by scientific software developers who want to build different versions of their code, which means it’s a tool for both facility deployment and can also do the same thing in the home directory of a user.
“We’re supporting codes with hundreds of dependencies with Spack. When we first started this in 2013 I had a grad student with 10-20 libraries she had to build for her PhD work and it took her two weeks to get that up and running and another week to get it running on a different system if she wanted to change a piece,” Gamblin explains. “We’ve gone from code that took two weeks to deploy but now we can build 60 different configurations of that in hours.”
Many people who have to deal with these porting problems are already familiar with another open source effort called EasyBuild, which is trying to fill the same niches as a port system where users can install HPC software and generate models instead of writing them by hand. It’s like Spack, Gamblin says, but their community has been the fastest growing with over 600 contributors on GitHub focused primarily on core tools and package recipes.


Blazing The Trail For Exascale Storage
When it comes to advanced technologies at the high end of compute, networking, and storage, Lawrence Livermore National Laboratory is one of the world’s pathfinding testbeds. Trying new things at scale is a big part of the mandate for the lab, which among other things, is the US Department of …

The Many Facets Of Hybrid Supercomputing As Exascale Dawns
There may not be a lot of new systems on the November 2020 edition of the Top500 rankings of supercomputers, but there has been a bunch of upgrades and system tunings of machines that have been recently added, expanding their performance, as well as a handful of new machines that …
Gordon Bell Prize Winners Leverage Machine Learning For Molecular Dynamics
For more than three decades, researchers have used a particular simulation method for molecular dynamics called Ab initio molecular dynamics, or AIMD, which has proven itself to be the method most accurate for analyzing how atoms and molecules move and interact over a fixed time period. In this time of …
Be the first to comment