

We have written much over the last four or five years about the role FPGAs might play in the ever-expanding deep learning space, both in training and inference. Progress there has been slower than some might have expected, especially on the inference side given the reconfigurability and lower power options available in devices from Intel (derived from Altera) and Xilinx. It seemed for a while that overlays would be the solution to wider adoption, but now it appears that the new direction is toward further fine-tuning of the hardware by, you probably guessed it, packing in the matrix elements.
With that in mind, Intel has released details on the new Stratix 10 NX FPGA, which is optimized for deep learning via a higher-density designed, support for mixed precision, and includes a “tensor arithmetic block” which is a revision on the standard Stratix DSP block for matrix operations. Intel also provided details about the networking and HBM integration in a recent overview of the AI-optimized architecture.
The “AI Tensor Block” that stands in for the DSP is comprised of dense matrix math units that can handle mixed precision workloads. It is also possible for the smaller units to be combined to handle larger precision multipliers. This is not unfamiliar in terms of the matrix units. We’ve seen this in various incarnations with the many AI chip startups that might have some FPGA-like features in terms of reconfigurability but not necessarily on a higher-end datacenter FPGA.
As seen below, the architecture has three dot-product elements with 10 multipliers and 10 accumulators per block, thus making it suitable for both matrix/matrix and vector matrix operations without size limitations. It is tuned for Int-8 and Int-4 and can also handle FP16. The key feature here is that several of these tensor blocks can be ganged up to crunch much larger vector math.
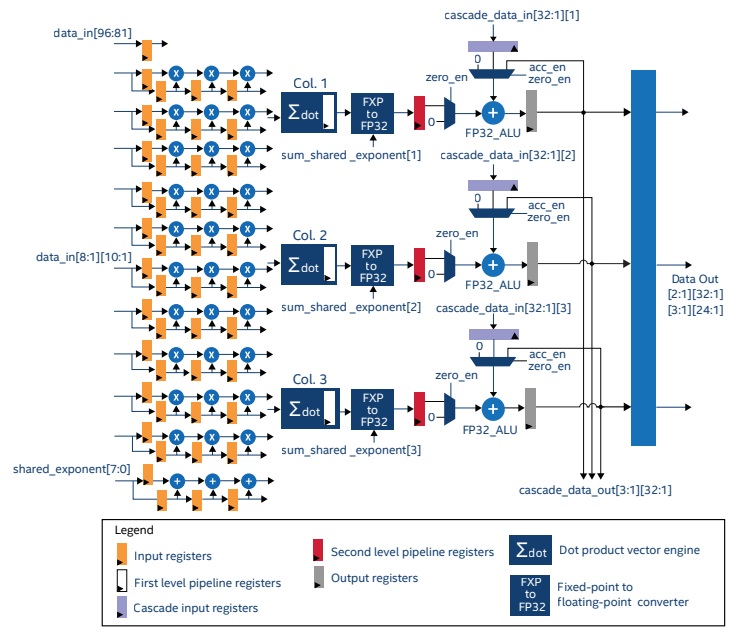
Did you have a moment where you wondered if it was still just a DSP block with a fancy new name that includes the word “tensor”? Well, the above highlights that’s not what happened here, although the early temptation may have been to be cynical. On that side note, why DSPs haven’t seen their day in the AI inference sun is still a bit of a mystery.
Intel has provided the following efficiency and performance numbers using 3,960 Tensor blocks for various precision targets seen on the right. Without normalization we are reluctant to pair those against existing MLperf inference data.
 With those figures in mind, Intel has projected on the workload everyone talks about but seems to have little bearing practically, ResNet50 to talk about its capabilities. They add that a single-chip implementation of the benchmark can tackle 7,000 frames per second (based on a 500 MHz clock with 75% utilization of the tensor blocks). They highlight that the difference between these tensor blocks replacing the DSP provide orders of magnitude performance over a straight Stratix 10 MX for ResNet 50, anyway.
With those figures in mind, Intel has projected on the workload everyone talks about but seems to have little bearing practically, ResNet50 to talk about its capabilities. They add that a single-chip implementation of the benchmark can tackle 7,000 frames per second (based on a 500 MHz clock with 75% utilization of the tensor blocks). They highlight that the difference between these tensor blocks replacing the DSP provide orders of magnitude performance over a straight Stratix 10 MX for ResNet 50, anyway.
The tensor blocks are fed and arranged around HBM2. There are two stacks with Intel’s own FPGA fabric per package, which is designed to address the real challenge in AI training and inference, memory bandwidth. Intel says each of those HBM2 stacks brings along 256 GB/s of bandwidth, so up to 512 GB/s in a package, which is definitely more bandwidth that one could get by the standard four external DDR4 memory devices. This approach also allows for larger models to kept in the on-chip memory, which comes in handy if ganging up several of the tensor blocks.
It’s interesting to look at the markets Intel sees as more valuable with this device. They have put special emphasis on financial fraud detection, noting this is where FPGAs have traditionally stood out, especially in near real-time point of sale transactions. In those cases, inference has to run on a transaction in less than 10 milliseconds (out of 400 milliseconds for the entire transaction) to check for fraud. Intel says that using batch size 1, which FPGAs can handle mightily, this on-chip memory coupled with their tensor blocks provides the low latency processing that can keep up with time-sensitive demands. Natural language and retail are other areas where Intel says the near real-time inference will be valuable with this approach.
There is not much released to date on the software underpinnings for the Stratix 10 NX FPGA but Intel says the devices will support both custom applications and deep learning on the same FPGA.
We have not seen hardware customizations like this from the other major datacenter FPGA maker, Xilinx, and it’s hard to say what we can expect going forward with the AMD acquisition. What will be useful is to see this new device paired against inference results on MLPerf, where there were actually several smaller FPGA companies vying to show off what reconfigurable devices could do.
“The increasing complexity of AI models and growth of model sizes are both rapidly outpacing innovations in compute resources and memory capacity available on a single device. Memory requirements for these models are also rising due to an increasing number of parameters or weights in a model. More parameters demand more on-chip storage to maintain model persistence. The increase in required memory also translates into a need for higher I/O bandwidth because more data must be transported. This growth rate is likely to continue,” says the team behind the engineering and design of the new Stratix 10 FPGA.

Intel’s NNP-I inference chips included a Tensilica Vision P6 DSP per compute engine.
Isn’t this what Xilinx has been doing for a while with their Versal-line? (Adaptive Compute Acceleration Platform)
https://www.xilinx.com/products/silicon-devices/acap/versal-premium.html