

Speaking very generally, investment in capability-class supercomputers by national governments tends to scale with gross domestic product. The bigger the particular national economy, the bigger the investment in flops.
And so when it comes to Australia, with the highest median wealth per citizen in the world – it jockeys with Switzerland in recent years on that metric – and a GDP of $1.89 trillion in Australian dollars in 2019 – $1.32 trillion in US dollars at exchange rates prevailing as 2019 came to a close – not only do we expect for the country to invest heavily in supercomputers. The people and businesses of Australia expect its governments to do so.
And this week, the Pawsey Supercomputing Center outside of Perth in Western Australia it is talking about a $70 million investment (that’s Australian dollars, about $50 million in US dollars today) investment for a 50 petaflops supercomputer that will bear more than a passing resemblance to the big exascale-class machines that will eventually be installed by the US Department of Energy’s Oak Ridge National Laboratory and Lawrence Livermore National Laboratory.
To be precise, the future machine at Pawsey is based on the Cray “Shasta” system design, which is being commercialized by Hewlett Packard Enterprise as the Cray EX system, that will use future generations of Epyc CPUs and Instinct GPUs from AMD as the compute engines in the machine. The design choice is interesting here for a few reasons, which we will explain after a bit of history for context.
The forebear of the Pawsey Supercomputing Center was founded in 2000, and it is noteworthy that regional academic institutions – CSIRO, Curtin University, Edith Cowan University, Murdoch University and the University of Western Australia – plus the Western Australian regional government plus the national Australian government all kicked in funds to support its efforts to expand supercomputing in this economic region, which we know for growing wheat and barley as well as for increasingly growing grapes and making wine in and around Perth. The organization before Pawsey was constituted in 2014 in its present form – as well as Pawsey since – have a long history of buying Compaq, Cray, and Silicon Graphics supercomputers, and it is also interesting that all of these companies have been acquired by HPE and are a substantial portion of its high performance computer business these days.
The first machine at what would become Pawsey was a cluster of 20 Digital Alpha 21264 Compaq SC40 nodes, nicknamed “Carlin” and running from 2001 through 2006. A much larger AlphaCluster was installed at the Pittsburgh Supercomputing Center around the same time, and it is interesting that HPE also acquired Compaq. Four years later, the company bought an Altix 3700 shared memory system, called “Carlin,” based on Itanium processors from SGI, which had 192 processors and 384 cores. And a year later, in 2006, Pawsey wanted to try out a new architecture and installed the “Marron” Cray XT3 system, which was the first capability-class supercomputer in the southern hemisphere when it was installed in 2007 with $5 million (Australian) in funding, which covered the machine for $1.3 million plus facilities and expenses for the remainder. A marron is a crayfish found in Western Australia, and this particular Marron machine was not all that large by modern standards, with 853 gigaflops of oomph with its 164 AMD Opteron processors, with a total of 384 cores, and “SeaStar” 3D torus interconnect. Interestingly, Marron was not just used for HPC simulation and modeling workloads, but also was used to run the Second Life virtual reality simulator. (Remember that? Did many of you have flashbacks when attending early virtual events this year?)
The pace started to pick up as the first decade of the 21st century ended and the second decade started, and in line with the expected computing needs of the Square Kilometer Array radio astronomy project (and honoring Australian radio astronomer Joseph Lade Pawsey), with the Pawsey Supercomputing Center installing a 128-node, 512-core Altix XE machine from SGI based on Xeon processors. Three years later, Pawsey really started to grow its compute capacity, with a 9,600-core cluster of HPE ProLiant servers called “Epic” and a year later with the acquisition of a hybrid CPU-GPU system called “Fornax” that was based on the SGI Altix XE 1300 design, but based on 96 nodes with 1,152 cores and a single Nvidia C2050 GPU accelerator per node.
In 2013 and 2014, Pawsey ramped up the flops bigtime and these are still the production machines at the facility; as such, they are getting a bit long in the tooth. The “Galaxy” Cray XC30, based on the 10-core “Ivy Bridge” Xeon E5-2690 v2 processor from Intel running at 3 GHz, obviously used the “Aries” dragonfly interconnect from Cray, had 9,440 cores and a peak theoretical performance of 226.6 teraflops at double precision. A year later, Pawsey installed the “Magnus” system, which is an upgraded Cray XC40 system based on the Aries interconnect again, but using the 12-core “Haswell” Xeon E5-2690 v3 processors from Intel. This Magnus machine has 35,712 cores and a peak performance of 1.49 petaflops.
There are a few lessons that can be learned from this history. First, excepting its initial dabbling in Alpha and Opteron chips, Pawsey has preferred Intel processors, and excepting the dabbling in the Itanium processors, it has preferred Xeon processors in particular. No surprises there, since that is what the rest of enterprise server buyers and what most HPC centers have done. What is also interesting is that Pawsey has chosen a number of different interconnects over the years, from the proprietary Compaq/DEC AlphaCluster, the Cray SeaStar, and the Cray Aries interconnects to the Mellanox (now Nvidia) InfiniBand interconnect. Which for all intents and purposes is also proprietary, since only one vendor is really driving it. (Yes, we know about Omni-Path being a quasi-flavor of InfiniBand, which could get a new lease on life from Cornelis Networks.)
With the replacement for Magnus and Galaxy, the as-yet-unnamed system will be the first real hybrid CPU-GPU system of any scale that Pawsey has put into the field, although we do not know if all of the nodes will have GPUs or not and what the ratio of the CPUs to the GPUs will be. (We are meeting with the people at Pawsey this week to find out more, so stay tuned.) And it is interesting that Pawsey is not choosing Intel Xeon SPs for the CPUs or Nvidia GPUs or Intel Xe GPUs for the accelerators. And like the 1.5 exaflops “Frontier” system being installed at Oak Ridge in 2021 and the “El Capitan” system being installed at Lawrence Livermore in 2022, the future Pawsey machine will have the combination of AMD Epyc CPU and Instinct GPU motors. (AMD has dropped Radeon from its datacenter compute brand, apparently.) The reason seems pretty obvious: AMD is playing a cheapest flops game against Intel and Nvidia. Plain and simple.
Frontier is getting custom AMD CPUs and GPUs in 2021, for a price of $500 million for the hardware. If you do the math on that, the US government is paying $333 per gigaflops for the raw iron, which includes servers, interconnect, and parallel file system. Oak Ridge is getting a great deal, which illustrates the premise of buying at volume and also buying first to drive innovation. The Frontier design has a single CPU and four GPUs, all linked through PCI-Express transports and the Infinity Fabric coherence protocol running atop it. El Capitan comes a year later with off-the-shelf, non-custom Epyc and Instinct GPUs at a cost of $600 million for the system and what we expect will be around 2.1 exaflops. (It was originally supposed to be only 1.5 exaflops in the bid, and 2.1 exaflops gets the sentence “in excess of 2 exaflops” used in the original announcement to be correct.) That works out to $286 per gigaflops for El Capitan.
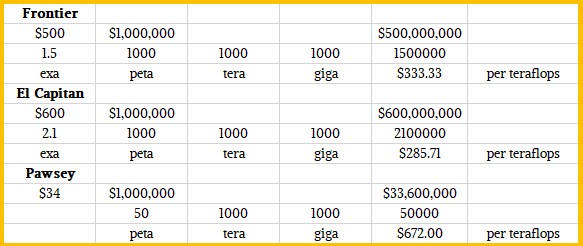
The Pawsey machine, which we presume will be using the 200 Gb/sec Slingshot variant of Ethernet developed by Cray as both Frontier and El Capitan do, will cost $48 million Australian, which works out to $33.6 million in US dollars at current exchange rates, or about $672 per gigaflops. We think there is a very good chance that this machine will use the same one-by-four CPU and GPU setup as well as the Slingshot interconnect that is at the heart of the Cray EX design, but there is no confirmation of that. We don’t think there is anything particularly special about the workloads at Pawsey that would compel a different ratio or even a custom Epyc CPU or Instinct GPU so long as the main compute engine has fine-grained mixed precision support, which is important for both AI and signal processing. But as we said, we will find out more shortly.
All that HPE and Pawsey have said about the architecture so far is that it will have 30X more oomph than the existing Magnum system and 10X more energy efficiency. That sounds like a machine that is dominated by GPU computing.




“Switzerland IN” -> “Switzerland in”
“it is talking about a $70 million investment (…) investment” -> “is talking about a $70 million (…) investment”
“$333 per gigaflops” -> “$333 per teraflops”
“$286 per gigaflops” -> “$286 per teraflops”
“$672 per gigaflops” -> “$672 per teraflops”
Hire me so I can feed my family.
The cost should be per teraflops IMHO, there is a typo in the text.
It’s all per teraflops. Just got my labels wrong when I was interrupted for the 47th time. I made a sheet where I could dial it all up depending:
Frontier
$500 $1,000,000 $500,000,000
1.5 1000 1000 1000 1500000
exa peta tera giga $333.33 per teraflops
El Capitan
$600 $1,000,000 $600,000,000
2.1 1000 1000 1000 2100000
exa peta tera giga $285.71 per teraflops
Pawsey
$34 $1,000,000 $33,600,000
50 1000 1000 50000
peta tera giga $672.00 per teraflops
33.3 cents per gigaflops sounded too cheap. $333.33 per teraflops sounds like some real money.