
Storage in the ever-expanding HPC space has traditionally been based on temperature. The tiering architecture that has arisen has had “hot” data that is frequently accessed is placed in faster storage systems, while “warm” data – that which is accessed less frequently – is put into somewhat slower storage. “Cold,” rarely accessed data is rarely accessed and placed in even slower storage systems. Organizations also have to have policies and software in place to access data and from it one to place to another as needed.
That may have worked well a few years ago, but the data landscape has changed and the temperature tiering method is increasingly complex, costly and too slow for the emerging workloads that are being run not only by HPC-based organizations but also enterprises that are finding that they need to HPC-like capabilities if they’re going to keep up with the massive amounts of data that they’re generating. As we’ve talked about, emerging technologies like artificial intelligence (AI) and machine learning are contributing to a rapid expansion of the type of HPC workloads that are being run and the increasing numbers of small files also are contributing to challenges facing organizations.
All-flash options are costly, tiering is complex – which also contributes to rising costs – and manual tuning puts pressure on organizations around headcounts and skill sets. Along with all this, the ever-present need for performance in moving and accessing data is forcing the industry to look for new ways to address storage needs.
“We saw this coming and decided we were going to try to innovate around it,” Curtis Anderson, software architect for HPC storage vendor Panasas, tells The Next Platform. “So flash is just too costly. If you want to buy a 30 PB or 40 PB setup, the extra cost there of all-flash is more than the cost of your compute farm. It’s just silliness. On the other hand, people need the capacity and really, really want the bandwidth, so what do you do? Most people respond with tiering. You have a small flash tier and a large cold archive tier – so temperature-based. We believe it gives you a very inconsistent performance and reduced productivity because of that. And there’s other costs – the cost of maintaining and managing two-and-a-half solutions. You get the hot here, the cold here and the policies to move things back and forth. There’s another traditional solution, manual tuning to change the tuning parameters in the parallel file system to match the workload.”
The problem is that the “days of a single workload and or even a few workloads are gone,” Anderson continues. “There’s now this enormous variety of workloads constantly changing and shifting on the compute clusters. They’re all what we used to call shared resource centers now. You’ve got lots of people doing lots of things, all sharing the compute farm and the storage has to keep up with it without tuning. The number of people and the skill set required to do that meant that manual tuning is expensive and in short supply. It’s just a difficult place to be.”
A key driver behind the use of AI and machine learning and the rise of small files and changing workloads, all of which are driving enterprises that are moving to HPC-style computation for normal processing. That means if a company is going to invest millions of dollars into a compute farm, it’s got to serve more than a single workload or two. Instead it needs to be able to run a wide variety of workloads. A study commissioned by Panasas in May laid out what’s fueling the growth in HPC storage, and number one on the list was more multi-run simulation workloads, followed by new workloads like AI and big data. An increase in analytical workloads also was on the list.

To address the inconsistent performance and the need for adaptability in HPC storage, Panasas this week unveiled Dynamic Data Acceleration on its latest PanFS parallel file system, an integrated software system that leverages various storage media – NVDIMM, NVM-Express SSDs, regular flash SSDs, DRAM and hard drives – to manage the range of storage needs, all of which is managed from a single place. The major difference is that Dynamic Data Acceleration tiers the storage based on size rather than temperature.
“We have director nodes and storage nodes,” Anderson says. “The storage nodes have this internal architecture. We have an NVDIMM that commits data and metadata operations that arrive from the client. All that goes straight in the NVDIMM and the client continues on its way. Then we do all the rest of our processing asynchronously to the client. Along the way, we realized as part of developing this technology that metadata is much more latency-sensitive than either small or large files, so we segregated that out into a database and put it into an NVMe SSD. It’s a combination of hardware and software architecture matching the need of metadata management. Small files are put those onto a SADA SSD – kind of low-rent SADA, but it’s an SSD. We also included six hard drives. The hard drives are actually very good at delivering bandwidth if the only thing they ever do is large transfers. You can’t ever put a small thing on them. Otherwise, you have to do a small transfer. What’s going on here is something akin to tiering, but it’s based upon size, not on temperature.”
PanSF is a scale-out POSIX file system that runs on Panasas’ ActiveStor Ultra HPC appliance built from commodity off-the-shelf hardware and is layered on top of an object pool that is defined by the T10 SCSI standard rather than S3 and all the technology in Dynamic Data Acceleration lives inside the Panasas storage nodes. When a file is created, if it’s small it gets triple replicated and as it grows, it’s moved to an erasure-coded format, which is more space- and performance efficient. Internally the storage nodes are looking at the size of the files and storing the content on the appropriate storage system, Anderson says.
“As a file continues to grow, it’ll graduate off of the SSD onto the hard drives,” he says. “All of that happens automatically so that the architecture is set up to, just by its nature, do the right thing. We do have a sweeper involved in this where we’re saying, ‘If for some set of reasons, like you deleted a whole bunch of small files, now your SSD is underutilized.’ We will pull a bunch of the smallest things [from a hard drive and] will pull them onto the SSD, etc. If the small file SSD gets over-full, we’ll take the largest things and graduate them to the hard drive. There is some dynamism going on, but basically we’ve designed the system to use devices efficiently and the customer doesn’t have to do anything. There’s no tuning, there’s no options they have to set. It simply performs well in the face of different file sizes and different workloads.”
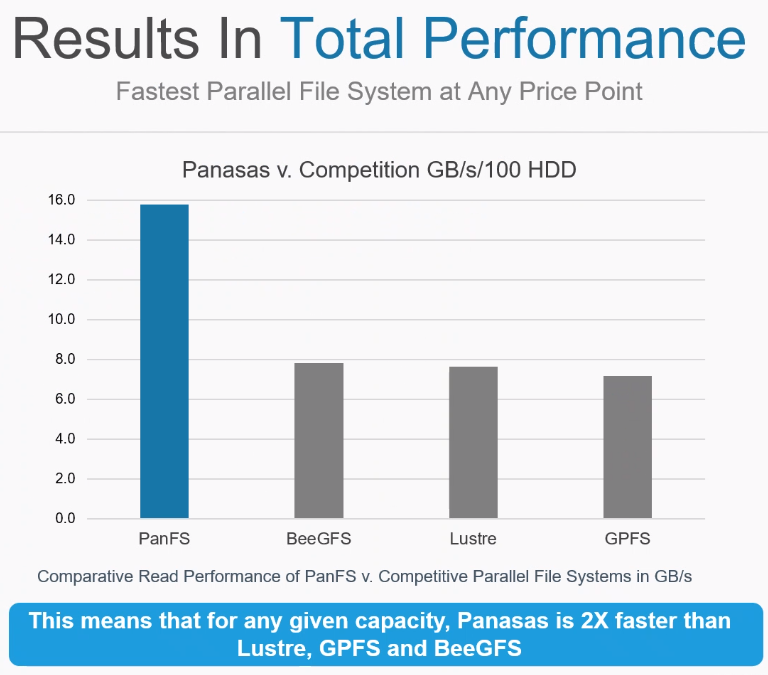
The focus is on device efficiency by using the appropriate medium for the particular file and automatically balancing the system as needed, Anderson says. The result is about double the performance than systems like BeeGFS, Lustre and GPFS at about half the cost. The cost of competitive systems comes in at about $400 per terabyte because of the heavy reliance on costly all-flash storage. In addition, the management of the environment includes more than two panes of glass – one for hot storage, another for cold.
“All-flash isn’t really an option for HPC capacity points,” he says. “You’re not going to buy 20 PB to 30 PB of flash. That’s silly. So the question is, how can you deliver near flash performance with a hybrid solution? So that’s what we ended up with, device efficiency as the core of this feature.”
By contrast, the Panasas system costs about $200 per terabyte. In comparing with competitive offerings, Panasas had to find common metrics in systems where the underlying hardware is so different across each.
“We finally said, ‘OK, we’re talking about hybrid, so the majority of the cost and the capacity comes in the form of hard drives, so let’s say performance per hundred hard drives,” he says. “That’s what this is. Also, the other solutions are clustered and and we are significantly ahead about twice. It’s because of that focus on device efficiency. The hard drives only ever do large transfers, so we’re getting an average of 150 MB/sec out of each one of them, pushing up to the 180 range. The SSD and the NVMe are also working hard. That’s why we did this, the focus on device efficiency.”

Panasas Adapts To The Ebbs And Flows Of Enterprise HPC
With enterprises increasing embracing HPC environments to help manage the tidal wave of data that’s washing over them and the rise of AI and machine learning workloads, tech vendors selling into the market need to demonstrate both flexibility and adaptability. Most of these organizations are going to start slowly with …

AI Is Driving Storage Down New Avenues
Storage systems are inherently data intensive. But the rapid emergence of artificial intelligence as a standard datacenter workload has storage vendors scrambling to design platforms that better meet the more stringent performance needs of these applications. Panasas, one of the few HPC storage specialist that hasn’t been swallowed by a …
Panasas Eyes Partnerships As Enterprise Demand For HPC Storage Grows
In late 2018, HPC storage provider Panasas rolled out its re-engineered PanFS parallel file system based on Linux, a move designed to give the company and its technology a capability that has become key at a time when HPC-like workloads and emerging technologies like artificial intelligence (AI) and machine learning …
I have no idea what tests you run to show Panasonic as 2x faster than BeeGFS but if you want to take the Pepsi challenge I’ll show you how our Parallux HIgh Performance Storage Cluster achieves over 50 GB/sec sustained reads and writes. Total usable capacity of this flash based SSD cluster we tested was right around 500TB. All at a cost that I’m certain how please any HPC user. Oh and there are no additional annual support cost.