
It happens all the time. There is a performance problem, and everyone blames the network. Supercomputing is no different, and given that massively parallel machines are largely defined by their interconnects even though compute represents the largest portion of a system’s budget and is what people talk about most, when an application is not performing as expected, it is easy to just blame the network and that ends the discussion.
But it really doesn’t.
The interconnect that creates a distributed system is obviously critical to efficiently using the performance embodied in the tens of thousands to hundreds of thousands of CPU cores in a modern capability-class machine – and the millions of combined CPU cores and GPU streaming multiprocessors that are ganged up to create exascale-class machines. Supercomputers are very expensive tools, and every bit of work that can be performed on them must be done, not only to make the most out of that investment but more importantly to do as much good as possible.
There are a lot of different tools that have been developed over many years that have helped supercomputer architects and system administrators do a better job squeezing more performance out of workloads and cramming more workloads on the machine concurrently and over time. But those tools are not up to the task of analyzing the complexity that is coming into the modern HPC center.
HPC systems are looking more and more like cloud infrastructure, with containerized workloads and Kubernetes orchestrators managing concurrently running applications. And even those supercomputers that are still running bare metal instead of containers for applications are increasingly multitenant and have contention and congestion issues. These are very different kinds of workloads, with different network access patterns, and they can wreak havoc on each other because of this.
Adaptive routing has been around for decades, acting as a traffic cop for HPC interconnects, trying to route traffic around hotspots in the network, but these features can have unintended consequences and make congestion worse rather than better.
Congestion control algorithms have been added to switches and their network operating systems more recently, including Explicit Congestion Notification (ECN) and Quantized Congestion Notification, but as Steve Scott, former chief technology officer at supercomputer maker Cray (Cray is now part of Hewlett Packard Enterprise) put it a year and a half ago when Cray launched its Slingshot HPC variant of Ethernet: “These protocols tend to be difficult to tune, slow to converge, fragile, and not suitable for HPC workloads. They can do a pretty good job if you have long-lived, stable flows, providing backpressure at the right flow rates per flow to avoid congestion. But they just don’t work well for dynamic HPC workflows.”
But the situation is even a bit more complicated. Not only are supercomputers looking more like clouds, they are also running a mix of HPC and AI workloads, either side by side or as part of a continuous workflow that merges the capabilities of machine learning and data analytics with traditional simulation and modeling to create much more capable applications.
Trying to figure out what application – and we use that word loosely – is causing what kind of contention and congestion on the network has never been harder. And that is one of the reasons why Cray-now-HPE worked with Argonne National Laboratory and NERSC at Lawrence Berkeley National Laboratory to create the Global Performance and Congestion Network Test, or GPCNeT. Feedback on network performance was also provided by Lawrence Livermore National Laboratory, and Oak Ridge National Laboratory.
None of these network routing and congestion problems are new. Back in early 2013, a few months after Cray announced its “Cascades” XC30 systems and their “Aries” XC dragonfly interconnect, Cray began receiving customer reports of run-to-run variability, each requiring significant analysis and unique solutions. In one report from 2017, a customer was running the GROMACS molecular dynamics application. When the XC system was under load, it could take twice as long or more to finish a simulation, with the same amount of compute allocated to it, than when the machine did not have to share the network with other workloads. This was obviously unacceptable, recalls Peter Mendygral, a master engineer at HPE who worked on this issue and who is one of the creators of the GPCNeT benchmark that HPE is offering up to the industry for adoption.
When debugging that GROMACS issue, Cray’s engineers created a bunch of “canaries in the coalmine,” which were synthetic applications that were either latency sensitive or bandwidth sensitive, and loaded them up on the XC machine to see the effect that congestion on the network was having on them. This let Cray better understand how the network was behaving, and importantly how to tune the Aries network to yield better performance for GROMACS and other workloads.
Unbeknownst to Mendygral, a few years later when Cray was working on the design for the “Shasta” generation of supercomputers, the company decided to get back into the HPC interconnect business and started work on the Slingshot variant of Ethernet. Slingshot takes some of the congestion control ideas embodied in switches made by Gnodal and marries them to Cray’s own adaptive routing techniques and implements them in a new 200 Gb/sec Ethernet ASIC that looks like it is offering a step function improvement in congestion control.
At the same time that HPC centers are getting increasingly in need of congestion control is precisely the moment when Cray-now-HPE has a new switch that is doing congestion control in a new fashion and when it has worked with these national labs to lay the foundation of a new HPC and AI interconnect benchmark that, among other things, shows the value of congestion control when networks are operating in less than ideal – rather than idealized and perfect – conditions.
“I view this in a number of ways,” explains Mendygral. “We will have fewer issues that are treated like bugs now because congestion management was precisely what was needed to fix this once and for all because you can’t really fix it in an MPI library. That library would have to be used by everybody, and not everybody uses MPI and so really it has to be done in the hardware. At the same time, we were getting a lot of feedback – not always very happy – from customers about performance variability. They definitely care about this, and care about it a lot. But the question we had is how do you demonstrate to them that congestion control works? How do you know that it will actually solve the problem they were having before? The only way to do that is to write something that measures it on the old and new systems and show them they were subjected to a lot of performance variability due to application interference. We needed a tool to measure this.”
And as it turns out, in a classic case of enlightened self interest, so does every HPC center. And so Mendygral teamed up with Taylor Groves at Lawrence Berkley National Laboratory and Sudheer Chunduri at Argonne National Laboratory, as well as nine other researchers at Cray and these two labs, to craft the GPCNeT benchmark and write the paper explaining what it is to the HPC world. That paper was announced at SC19 last year, and you can read the paper here and also get the companion presentation from the SC19 session here. Now Cray and the HPC centers who helped craft the initial implementation of GPCNeT and ran the test on a series of supercomputers with three different network architectures – Cray Aries, Mellanox EDR InfiniBand, and Cray-now-HPE Slingshot – and on all-CPU and hybrid CPU-GPU systems want to get the word out more broadly about GPCNeT and work to get it to become a standard for testing interconnects under load for distributed systems.
The Long Tail Wags The Interconnect
The issue that HPC customers as well as their peers running AI clusters and managing datacenter-scale systems with 100,000 servers at hyperscalers and cloud builders is tail latency. Networks and systems have tended to be designed and chosen with average latencies in mind, but that 99th percentile latency – the one that is slower than the other 99 percent of the network requests going on in the system – is the one that can bring everything to a crawl.
“How sensitive an application is to this really depends on its synchronization patterns,” explains Duncan Roweth, senior principal engineer in the CTO office of HPE’s HPC business unit. “Although we talk about latency sensitivity, a lot of people have this rather simplistic view about latency and really it is the interaction between tail latency – the worst case latency an application is seeing – and the synchronization in the application. Some people have done lots of work making their algorithms much more asynchronous so that they can cope with performance variation of all forms in a machine and in their applications, and data sensitivities in their application. But where an application has lots of fine-grained synchronization, that is how it couples to the tail latency. Some people are strongly motivated to make their applications more asynchronous and reduce all this coupling. But in other cases – and this is really the majority of high performance computing applications – — there is this coupling either in the form of collectives that apply across large numbers of processes or through the repeated use of the same communication pattern. The simplest way of causing trouble is to put a global reduction into your code. Now, no process can proceed until every process has finished, and that is a very common idiom in high performance computing applications. But if you don’t have that and you still have each process communicating with all of its neighbors, and then they are communicating with their neighbors, and so on and so on, you are still introducing synchronization across the whole application. It just takes a little bit longer for effects to spread out.”
This issue is not just one that HPC centers wrestle with. It is inherent in the interconnects lashing together all of the compute engines in a distributed system. The hyperscalers and cloud builders have a different attitude, one that is engendered by their scale and the fact that their machines literally print money today rather than do research that makes money for someone else at some point possibly in the future. For one thing, they massively overprovision their networks, and they often buy Ethernet switches with deep buffers that help with congestion some, but ultimately just add latency to the network if contention gets bad enough. And so, they drop packets.
“One of the main reasons why Ethernet networks drop packets is because people are extremely concerned about causing congestion, or interference between different workloads and different streams,” said Steve Scott, former chief technology officer at Cray. “So if one stream starts causing congestion, these hyperscalers would rather throw its packets on the floor than allow it to back up the network. There is a sort of death spiral because you don’t want to cause congestion, so you drop packets. But you don’t really want to drop packets and so you build these really big buffers in Ethernet switches and they can soak up temporary congestion. And that works if the congestion is really temporary. But it also introduces big pools of queued up packets that are being buffered in the network that aren’t going anywhere. And so that ends up really adding onto the queuing latency for the traffic across the network. Alternatively, datacenter operators will dramatically overprovision networks to avoid congestion, which is of course quite expensive.”
Scott said that it is important to realize that this is not just an HPC problem, but it is also happening with webscale applications, which kick off thousands and thousands of remote procedure calls (RPCs) that hit hundreds of servers all across a hyperscale datacenter, which are of course are linked by a massive network that spans the entire datacenter. This is a simple case, and there are examples that are much more complex, said Scott, who spent some time working at Google and seeing this first hand. If one or more of those RPCs takes a lot longer than the rest because of congestion on the network, then it screws up the service level agreement for the entire transaction. And hence, they overprovision their networks in a way that is impossible for HPC systems to do because of the cost.
But here is the fun bit: The hyperscalers and cloud builders need to test the effects of loading up the network with latency sensitive and bandwidth sensitive applications and then throwing congestors at them to see how their network reacts – every bit as much as HPC shops do.
And so, it is hoped, the foundation that HPE is laying with the GPCNeT test will result in useful benchmark results that not only help customers fix their existing networks and applications when they are not working optimally, but to help them choose better networks going forward, based largely, we think, on how well adaptive routing and congestion control features work.
How GPCNeT Works
Here is how the GPCNeT test works. There are a set of canaries that represent the latency sensitive and bandwidth sensitive workloads that normally run on HPC systems. These are loaded onto one fifth of the nodes on a supercomputer. These nodes run the canary workloads without any load on the other four-fifths of the machines in the cluster, and both average and 99th percentile measurements are made for latency and bandwidth for the application. Now, four different congestors are introduced to load up the network and cause contention for the interconnect resource and the measurements for the canary workloads at average and 99th percentile are taken again. The congestion impact is the ratio of the two.
There are a number of ways to use the GPCNeT benchmark, and the first implementation, which was revealed at SC19 in a peer-reviewed publication, shows a number of things. Take a look:
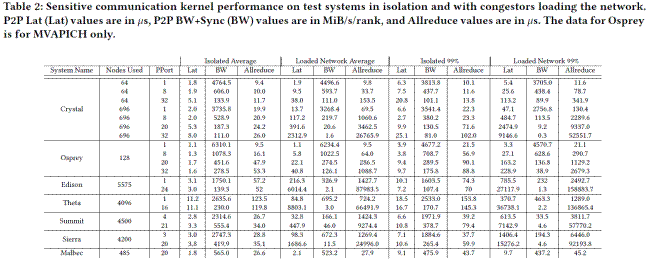
For those of you who like the raw data, and not normalized data, here is the full table from the SC19 peer-reviewed paper:
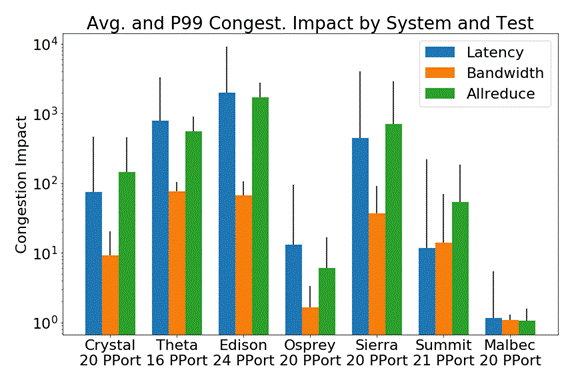 A couple of things pop out immediately looking at this data.
A couple of things pop out immediately looking at this data.
First, the InfiniBand systems did better than the Aries machines at handling congestion, and that is remarkable given the fact that the “Summit” machine at Oak Ridge and the “Sierra” machine at Lawrence Livermore both have the congestion control features on their 100 Gb/sec EDR InfiniBand switches turned off. The Osprey system, which is obviously a lot smaller, does not have congestion control turned on either, but does well because it does not taper its network and it is a smaller system.
The second thing to note is that smaller systems tend to handle congestion better than larger systems with more nodes and more end points and hops on the network. So the “Crystal” system does better than the “Theta” and “Edison” machines at the National Energy Research Scientific Computing Center at Lawrence Berkeley.
The third thing to note is that latency is more sensitive to congestion than bandwidth is, and that is because larger messages can be distributed across multiple paths on the interconnect and also have a larger baseline time to complete their transfers.
The fourth thing to note is that the taper of the network – the ratio of the global (bi-section) bandwidth of the network to the injection bandwidth of a node – matters. You can cut the taper, but at least on the GPCNeT tests run so far, there is a pretty substantial impact at mean and 99th percentile for latency and bandwidth.
The final thing that really pops out is that the 485-node “Malbec” test system in use at Cray-now-HPE to put Slingshot through the paces has very little congestion under load, even with the congestors trying to mess with the production workload. The congestion control features in HPE Slingshot seem to be working like a charm.
Now it is time for the other interconnect players and their HPC, AI, hyperscale, and cloud customers to work together to make GPCNeT a tool alongside Linpack, HPCG, STREAM, and other benchmarks used to compare systems – and to chime in with their own GPCNeT results. Consider this a challenge, not just for today with HPE Slingshot ramping in production on HPE Cray systems, but from this point forward.


Datacenter Infrastructure Report Card, Q3 2023
It is hard to keep a model of datacenter infrastructure spending in your head at the same time you want to look at trends in cloud and on-premises spending as well as keep score among the key IT suppliers to figure out who is winning and who is losing. And …
HPE Slingshot Makes The GPUs Do Control Plane Compute
In modern system architecture, there is a lot of shifting pieces of systems software (particularly in the control plane) and often their workloads around between pieces of silicon to get better bang for the buck, to improve the overall security of the system, or both. But it is important to …
Arrow Hits the Mark for Petabyte-Class Analytics Problems
When we first talked to Voltron Data following their launch in early 2022, we had to take care to explain why Apache Arrow was worth paying attention to and why it might warrant the level of enterprise support the startup promised. Even more explanation was needed to justify the $110 …
Be the first to comment