


Even before the coronavirus pandemic hit, Intel, the dominant maker of processors for servers on the planet, was rejiggering its product roadmaps behind the scenes in conjunction with its largest OEM partners as well the hyperscalers and large public cloud builders that drive about a third of its revenues these days.
The Xeon SP server roadmap was getting bunched up a bit, and Intel needed to flatten it out a little with “Cooper Lake” and “Ice Lake” and “Sapphire Rapids” server chips all coming out in early and mid-2020 and then early 2021, respectively. In hindsight, by the time the pandemic did take off, mothballing the third generation “Cooper Lake” processors for the two-socket variants of the “Whitley” server platform and doing a refresh of the Cascade Lake processors for the existing “Purley” platform, as happened in February, was undoubtedly the right move for Intel to make.
What was clear to us at the time was that Intel needed to do something very early this year to take on the competitive threat that AMD’s Rome” Epyc 7002 series processors presented, the simplest and easiest thing to do was to tweaked the existing 14 nanometer “Cascade Lake” chips, with some clock tweaks and core count boosts at different price points, rather than waiting to launch a whole new Cooper Lake processor, also etched in 14 nanometers and sporting the BFloat16 (or now more commonly called BF16) numerical format created by Google for its TPU machine learning motors on the Xeon SP’s AVX-512 vector math units, on the two-socket machines as we suspect Intel had originally planned to do.
With the 10 nanometer “Ice Lake” Xeon SPs coming out later this year, Intel decided to fork the line sort of like it used to do with the Xeon E5 and Xeon E7 – or Xeon DP and Xeon MP even further back – processors lines. The reason is simple. Intel had to do something fast and easy to combat AMD in the one-socket and two-socket space, which it could do with a rejiggering of the Cascade Lake chips and the existing platforms, allowing OEMs and ODMs to keep using the same Purley platforms and not have to certify designs for the Whitley platforms. This was easy, and any engineering that companies had done with the Whitley platform could be applied to future Ice Lake Xeon SP systems.
Originally, Intel did plan to do two-socket variants of Cooper Lake as a stop-gap as it tried to get its 10 nanometer manufacturing capability, which has caused the company all kinds of technical heartburn but which has not dented its revenues one bit, ramped up.
“We actually at first looked at that and talked to our customers a lot about doing Cooper Lake top to bottom,” Lisa Spelman, vice president of datacenter marketing and general manager of Xeon products, said during a conference call going over the new chips. “But as we moved further along towards production and talked through the workflows, the use cases, and the timing for Ice Lake with them, we just felt that it was more congestion in the roadmap. And we felt like the work we did with the Cascade Lake refresh helped meet a bunch of those market needs that we would have been trying to address. The four-socket and the eight-socket machines and the need for the second generation of Optane persistent memory was the more pressing and pervasive opportunity.”

With AMD not having a four-socket or eight-socket server platform and this part of the Xeon SP line needing a refresh, Intel created a bridge platform, called “Cedar Island,” that could take the Cooper Lake processors but also provide support for faster memories and the second-generation “Barlow Pass” Optane persistent memory sticks, which plug into DDR4 memory slots, expected with Ice Lake machines and the Whitley platform. (Think of Cedar Island as a hybrid of the Purley and Whitley server platforms, and it is more or less like the old Xeon MP and Xeon E7 part of the server processor line.)
The fact that Cooper Lake is the first chip to sport the BF16 format, which we discussed at length last July, is interesting. And oddly enough, companies like Facebook, which is embracing BF16 for both CPUs and GPUs for its “Zion” eight-socket CPU and eight module GPU hybrid systems, needs a chip that has BF16 support and can span eight sockets because it wants a unified numerical format for the CPU and GPU portions of its machine learning training workloads. (Which is sensible, and which allows Facebook to use both CPUs and GPUs for training to full effect.) And given that Intel needed to make good on that promise to Facebook and those who want to use its Zion platform, or some clone of it, for machine learning training, it makes perfect sense to roll out a special subset of what would have been a full Cooper Lake Xeon SP line, but one aimed only at servers with four or more sockets.
And that is precisely what Intel has done. Eventually, thanks in large part to the work of Jim Keller, who retired from Intel for personal reasons earlier this month and who was senior vice president of silicon engineering, Intel will very likely get back to a proper annual cadence for chip rollouts that will look a lot less chaotic than the past several years. Keller has a long and illustrious career in chip design, and was instrumental in the “Sapphire Rapids” project and we presume ideas about how to best use the fabs and labs at Intel to get on a normal, regular cadence. If AMD can do it, Intel can do it, too.

The Cooper Lake launch is being wrapped by various announcements Intel is making, including the Barlow Pass Optane 200 Series memory, new D7-5500 and P5600 TLC flash storage, as well as a preview of the new Stratus 10 NX FPGA aimed at datacenter inference and limited sampling of the Goya and Gaudi machine learning accelerators that Intel acquired in December 2019, knocking out the accelerators that Intel got control of in August 2016 when it bought Nervana Systems for $350 million. Intel has a wealth of compute engines, and has its “Ponte Vecchio” Xe discrete GPU in the works for delivery in 2021. The intent is to glue all of these devices together with a single oneAPI programming framework, allowing customers to port applications to any and all of these Intel devices – and any other devices that get oneAPI support, should that come to pass. (Don’t hold your breath on that one.)
Diving Into Cooper Lake
The cores in the Cooper Lake chips are essentially the same as those used in the Cascade Lake chips, except for the ability to pump BF16 data through the AVX-512 units on the Xeon cores. And the Cascade Lake chips were essentially the same except for the ability to do 8-bit integer (INT8) instructions in the AVX-512 units, which is known variously as Vector Neural Network Instructions (VNNI) or DL Boost (short for Deep Learning Boost). While INT8 is useful for inference, BF16 is used for both training and inference and in that sense is more useful for many companies that are trying to do AI on CPUs, either wholly or partly. We are going to do a separate discussion of CPU-based AI, so sit tight for that. For now, we want to get into the feeds and speeds of the Cooper Lake chips that Intel has actually put out on the market. The VNNI INT8 support was expected in the original Ice Lake Xeon SPs, and they were expected years ago. So while BF16 is perhaps coming early-ish, VNNI in general was coming a little bit later than planned but not terribly so.
Chip happens.
There are eleven processors in the Cooper Lake lineup, not counting any customized parts that Intel might be making for the hyperscalers and cloud builders. Intel confirmed to us that there are no enhancements to instructions per second (IPC) to the Copper Lake cores with respect to the Skylake and Cascade Lake cores on which they are derived, so there is no extra oomph coming from microarchitectural tweaks. We do expect that Intel has been able to refine its 14 nanometer processes a little bit more, goosing clock speeds by a smidgen.
Usually, there are three different variants of any Xeon SP generation. The Low Core Count, or LCC variant, has ten cores on a mesh interconnect. The High Core Count, or HCC variant, has 18 cores on a mesh. And the Extreme Core Count, or XCC variant, has up to 28 cores on a mesh. That term “extreme” is relative, particularly with AMD delivering 64 cores per socket with its “Rome” Epyc 7002 server chips, Ampere Computing working on 80 cores for its “Quicksilver” Altra Arm server chips, and Marvell promising 96 cores for its “Triton” ThunderX3 Arm server chips. Anyway, there is not Cooper Lake LCC variant that is coming to market, but as you can see below, there are HCC and XCC variants.
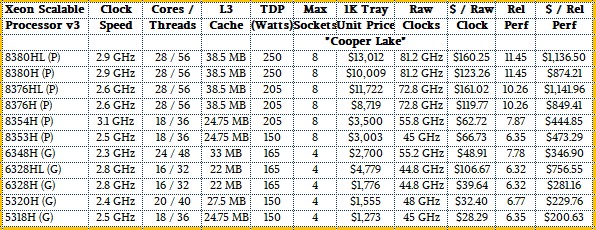
Here is a table outlining the new Cooper Lake chips:
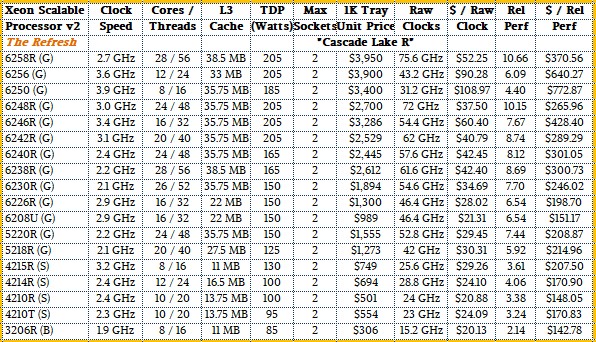
And for the sake of reference, here is the table for the Cascade Lake-R chips that came out in February:
And here is the table for original, unified Cascade Lake lineup, which included processors that spanned from two to eight sockets.
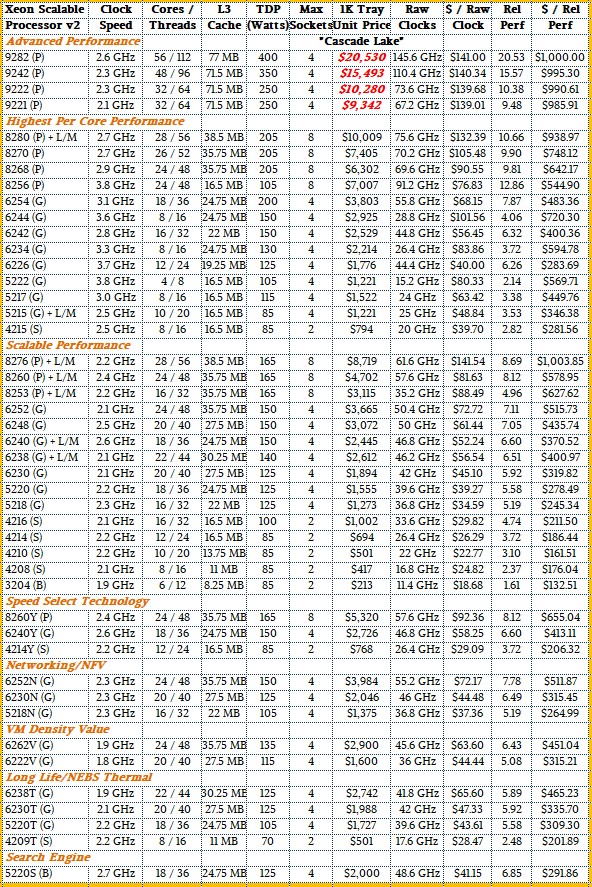
The larger Cascade Lake processors are the ones that the Cooper Lake machines need to be compared to as well as to the Cascade Lake R chips so you can see the premium Intel is charging (if any) for chips in four-socket and eight-socket servers.
In addition to the support for BF16 data formats and the next-gen Optane memory sticks, the Cooper Lake chips also sport an enhanced Speed Select Technology (SST) feature, which provides quality of service provisioning on selected Xeon SP processors in terms of their clock speeds and thermals. Interestingly, Speed Select is only available on three of the processors, and they are in the Gold series. They are the Xeon SP-6328HL, the Xeon SP-6328H, and the Xeon SP-5320H.
And those Barlow Pass Optane DC memory sticks are only available on three of the Cooper Lake SKUs: the Xeon SP-8380HL Platinum, the Xeon SP-8376HL Platinum, and the Xeon SP-6328HL Gold. These later three chips can have up to 4.5 TB of mixed DDR4 and Optane 200 memory; all of the other ones top out at 1.12 TB. By the way, you can only use the Optane 200 Series memory on four-socket machines with these specific processors; you cannot use them on eight-socket machines, which seems odd considering that the Xeon SP processors have enough physical bits to address 64 TB of memory and an eight-socket box would only have 36 TB of combined DDR4 and Optane memory.
The Cooper Lake chips have six memory channels per socket, like their Skylake and Cascade Lake predecessors, and can have two DIMMs per channel running at 2.93 GHz or, in the lowest two bin parts, 2.67 GHz, and the Platinum parts can have one DIMM per channel running at 3.2 GHz, yielding a 7 percent boost in bandwidth. With 256 GB DDR4 memory sticks – which no one can afford really – the system should top out at 1.5 TB of DRAM (six memory slots times 256 GB for each slot is 1,536 GB or 1.5 TB when divided by 1,024 GB per TB), but for some reason all of the spec sheets say 1.12 TB. A machine with mixed DDR4 and Optane memory can top out at 4.5 TB. These are the Cooper Lake chips that have an L at the end of their product name.
Like other Xeon SP chips, the Cooper Lake processors have the ability to boost the clock speed of cores of some or all of the other cores are turned down. While this is interesting, and can boost the speed of one core anywhere from 3.8 GHz to 4.3 GHz, we use base clock speed to gauge the aggregate throughput of Xeon processors over time.
In the tables above, we multiply the number of cores by the clock speed to get a raw performance metric, and then use the IPC uplift since the “Nehalem” Xeon 5500 series that launched in 2009 as the touchstone. In these tables, the performance of the performance of the Xeon E5540 standard part, which had four cores and eight threads running at 2.53 GHz and 8 MB of L3 cache memory is set at 1.0. And if you do all that math, then the relative performance of the top-bin Xeon SP-8380HL Platinum, running at 2.9 GHz, is 11.45, which is 7.4 percent higher than the performance of the Cascade Lake Xeon SP-8280 Platinum, which ran at 2.7 GHz. (That’s just the clock ratio given that the core IPC is the same and so is the core count. These chips have the same $10,009 price tag each when bought in 1,000-unit quantities, which just goes to show you Intel is not feeling any competitive pressure at all. If you want the fat Optane memory, you have to add $3,003 to the price of the chip. And in the case of that chip, that extra 200 MHz costs you an extra 45 watts of power. It is not clear why, and we suspected it might be a typo in the Intel documents, but it does not appear to be. The L3 caches are the same at 38.5 MB across the 28 cores, so that ain’t it. It’s peculiar.
In general, throughout the rest of the Cooper Lake stack, Intel is tossing two more cores, 2 MB more L3 cache, and 200 MHz more of performance for the like-for-like part (when you can find one to compare directly to) and charging the same price for the chip. So the price/performance goes up by that amount. This is a welcome thing. But at this point, a fully loaded two-socket Rome Epyc chip will deliver a third more cores for around the same or better performance, and for less money and therefore much better bang for the buck. These prices are the ceiling from which customers start negotiating, of course.
Here is how the four socket Cooper Lake machine is assembled:
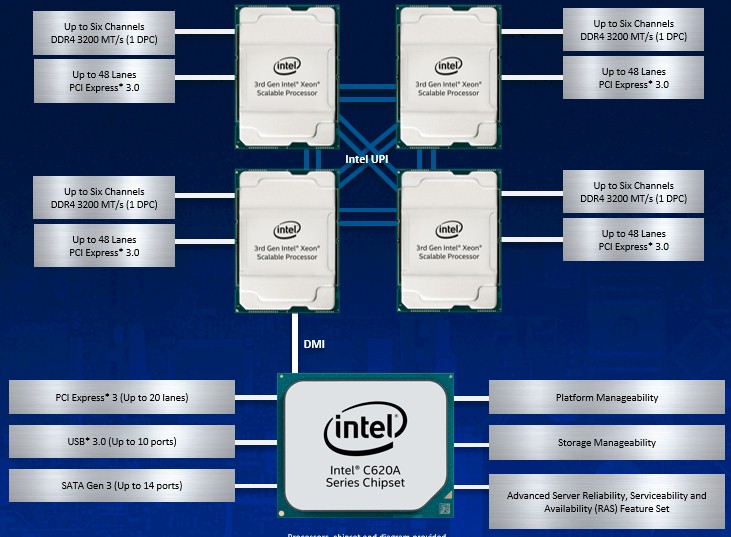
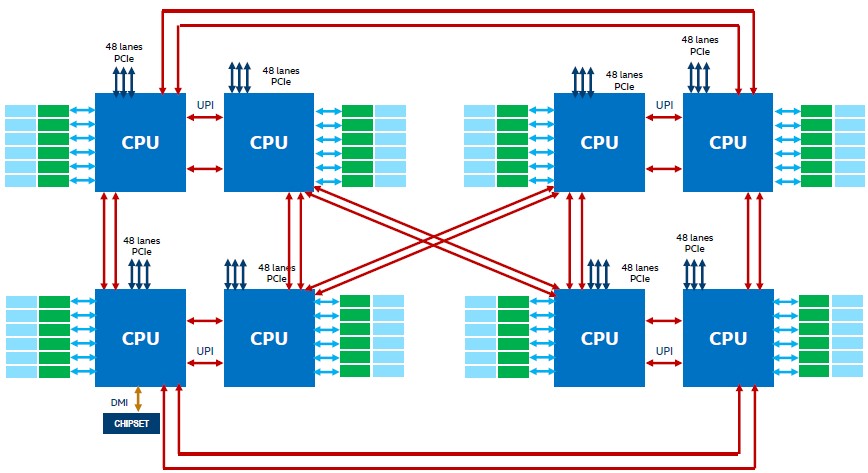
Each Cooper Lake chip has six 10.4 GT/sec UltraPath Interconnect (UPI) links for creating the NUMA connections between sockets; the chart above shows them, and they are not three pairs of lanes as I originally thought. (Apologies for the confusion.) The Cascade Lake chip had three UPI links, so this is a big improvement in NUMA interconnect bandwidth and scalability. This explains some — but not all — of the power increases we see in the Cooper Lake chips.
Each Cooper Lake chip has 48 lanes of PCI-Express 3.0 peripheral interconnect, and there is a direct memory interface that links from the processor complex out to the C620A Series chipset, which has 20 lanes of PCI-Express 3.0 itself as well as ten USB 3.0 ports, and up to fourteen SATA 3.0 ports.
Here is what the eight-socket Cooper Lake system looks like, which Facebook called a “twisted hypercube” topology in the Zion platform:
According to Spelman, average performance gain across a wide variety of commercial and technical workloads between a five year old “Broadwell” Xeon E5 chip in the same class is 1.9X and it is just under 2X for a database platform. We will be digging down into the AI performance of the Cooper Lake chips separately along with that discussion of CPU-based AI training and inference that we had with Wei Li, who is vice president and general manager of AI software and hardware accelerators at Intel.
That brings us to the Xeon SP roadmap:

The Sapphire Rapids processor, the fifth generation chip in the Xeon SP family, will be the second Intel server chip to use 10 nanometer manufacturing processes, and in fact will use the third iteration of those processes if all goes as planned, and will be based on the “Willow Cove” core that is used in the current “Tiger Lake” Core processors for client machines. Sapphire Rapids is still on track for 2021 and, as this chart reveals, has just powered on in Intel’s labs. The other interesting bit that was revealed in this chart is that Sapphire rapids will include something called Advanced Matrix Extensions, or AMX, for which Intel will be releasing the specifications later this month. We strongly suspect that the vector units will be able to do matrix multiply operations analogous to Tensor Core units on Nvidia GPUs – although very likely not compatible with Nvidia’s units, of course. We will be keeping an eye out for those AMX specs.